新闻评论
首先,要改变当前主流的AI叙事,将AI从效率工具转变为客户价值的驱动者,公开且明确地宣告AI将如何帮助您的客户。团结领导团队围绕以客户为导向的AI战略,并建立专注于利用AI释放客户价值和差异化优势的工作流。

无论是专家分析还是AI分析,第一步都是筛选需要看的数据。实际上在一个故障发生的时候,数据库可观测性的数据对于所需要分析的 任务而言是太多了而不是太少了。对于一些国产数据库而言,很可能会缺少一些关键的数据(指标、日志等),但是其指标数据的总量依然不少。

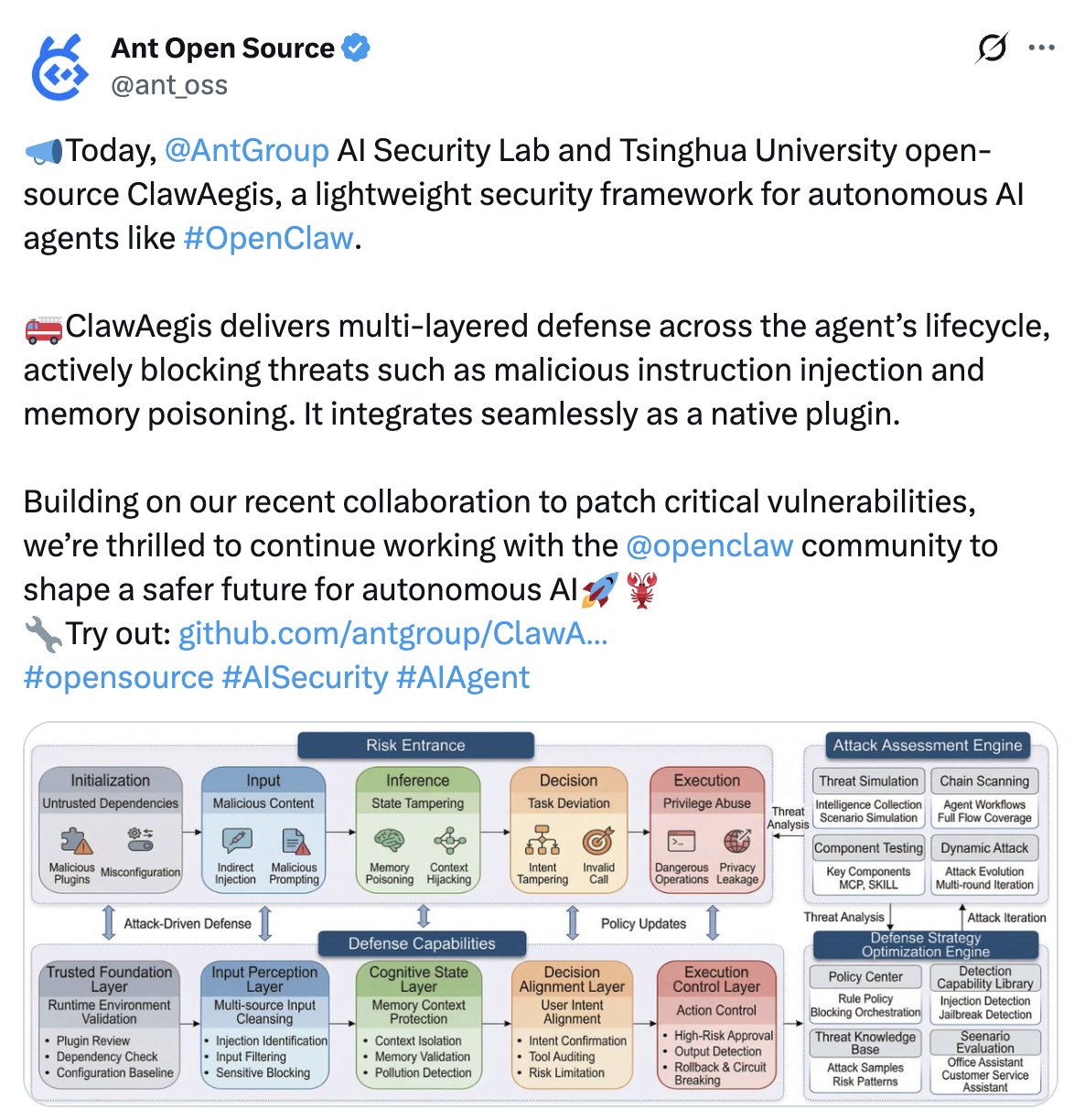
4月2日,蚂蚁集团AI安全实验室与清华大学联合开源ClawAegis——这是首个覆盖OpenClaw全生命周期的安全防御插件,旨在系统性解决其面临的安全与可靠性风险,为自主智能体提供多维度、轻量化、即时干预的原生防护能力。
OpenAI周二宣布,已完成一轮创纪录的融资,投后估值达8520亿美元。与此同时,我们看到该AI巨头一面巨额融资,一面关停产品进行战略聚焦调整, OpenAI的发展也为我们揭开AI市场的一角真相。

3月,世界数据组织在北京完成组建,选举产生首届理事、监事和组织负责人。这标志着世界数据组织正式投入运行;一批MySQL社区成员和开发者向甲骨文发出联名公开信,意欲扭转MySQL不利局面;OceanBase 正式发布面向 AI 时代混合负载场景的融合版本Ocea

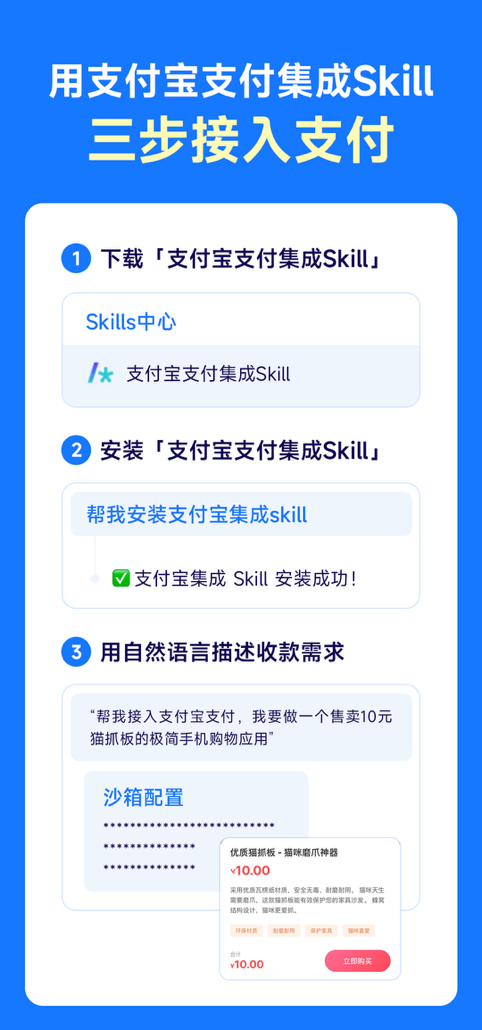
3月31日,支付宝正式发布国内首个“支付集成Skill”,并同步上线魔搭社区Skills中心。该产品将基础支付能力深度封装为标准化组件,让Vibe Coding开发者可通过自然语言在应用开发中快速接入支付宝支付功能。


之所以称其为转折点,是因为相关问题已不再是悄无声息或孤立存在——它们正以协调一致且公开透明的方式浮出水面。企业对锁定效应、不透明的路线图、定价权以及可维护性问题日益警惕。与此同时,云服务提供商已表示,若治理结构更加清晰,他们愿意加大投入力度。

3月26日,在中关村论坛未来产业创新发展论坛中,蚂蚁数科大模型技术创新部总经理章鹏在演讲中表示,OpenClaw的爆发将带来企业级AI范式革命,推动大模型在产业场景的落地从‘参数竞赛’走向“Token效能竞争’。”

如果脚手架是造车的流水线,Harness是交通指挥系统,那么 OpenClaw 就是一辆已经造好、加满油、可以直接开上路的车。

在IT运维领域,虽然AI冲击波给大家的冲击不小,不过AI战略大多数也只是在某些人的脑子里,并未形成实质性的化学反应。这波龙虾潮的到来,一下子让很多企业的IT管理者不安起来,好像能够颠覆很多传统领域的势力已然出现,自己再不搞点AI要被时代抛弃了似的。

自动化软件供应商Zapier最近的一项调查发现,98%的高管现在期望员工具备一定程度的人工智能能力。这一发现表明,AI专业知识不再局限于专门的技术岗位,而是正在成为日常工作的默认组成部分

当地时间3月23日,Anthropic在官方博客宣布为Claude发布了计算机操作(computer use)功能,Claude可以利用电脑进行点击操作并完成任务。搭配上周发布的Dispatch功能,用户可以在手机上为其分配任务,自主干活。

LingBot-VLA基于覆盖9种主流双臂机器人构型、总计超20,000小时的真实世界操作数据进行预训练,与自研高精度空间感知模型LingBot-Depth协同工作,进一步提升操作精度。

与OpenAI的合作、收购Observe的意向以及Project SnowWork项目,都指向同一个核心理念:数据平台应当是AI实际运行的场所,而不仅仅是数据导出的源头,

数据本体是对特定领域知识的正式、结构化表示。它定义了业务中存在的概念、描述这些概念的属性以及连接这些概念的关系,从而形成一个共享的、机器可理解的词汇表。
蚂蚁数科正式推出“蚁天鉴2.0 - 龙虾卫士”AI安全防护体系,并同步启动“龙虾AI安全守护计划”,旨在为部署OpenClaw的企业提供全生命周期、多层次的安全保障。

随着AI技术深入应用,开源数据库将扮演重要角色。互联网时代,MySQL成为了LAMP堆栈的代表。而在AI时代,PostgreSQL暂时获得了更好的发展势头,MySQL也在调整追赶。
