新闻评论

当地时间5月4日,SAP宣布将收购数据集成与分析服务提供商Dremio,旨在将其数据分析和AI代理构建工具的应用范围扩展至外部数据源。

每个大型企业都有数据目录。其中大多数是在 2018 年至 2024 年间构建的,当时正值数据民主化、自助式分析以及当时颇具革命性的理念(即人们应该能够查找和理解其组织产生的数据)掀起一股热潮之际。

时隔六年,达梦数据的云数据库迎来了全新升级,在日前举办的2026中国数据库技术与产业大会上,达梦数据发布了达梦启云数据库V4.0版本,将云原生数据库带到智能化时代,更进一步强化了其在云数据库市场的差异化竞争力。

4月,阿里巴巴进行组织架构调整,李飞飞(飞刀)出任阿里云CTO,负责阿里云技术以及AI云基础设施建设;多伦多大学教授警告企业应用NL2SQL要谨慎;达梦数据2025年实现营业收入13.06亿元;腾讯云、OceanBase等发布智能体记忆服务;平凯星辰正式发布平

AI正重塑行业竞争格局,也改写了市场竞合关系。谷歌既是Anthropic的投资者,与此同时,其Gemini与Anthropic在模型和服务市场展开竞争。

其实DBA去拥抱AI并不是一句空话,或者是一句引发焦虑的话,自己从点点滴滴的小技巧的收集开始,并且用一个小的AI助手来管理这些知识,并逐步用到你的运维实践中,那么你就会变成一个AI时代的DBA了。

数据库性能是一个永无止境的话题,IT专业人士——尤其是DBA——似乎永远谈不完,我想这是因为数据库应用程序的性能是最终用户抱怨最多的问题之一。

根据SolarWinds最近发布的《数据库现状报告》,超过三分之一的数据库管理员(DBA)正因职业倦怠而考虑离职,这一数据折射出的问题,将波及企业多项核心业务职能。此外,作为拥有30多年经验的数据库专家,我担心这些后果会引发连锁反应,从而限制未来的创新、缩减

开发在线OLAP数据库DuckDB的团队提出了一种解决方案,旨在解决他们所称的困扰基于Databricks、Snowflake、Google等技术实现的湖仓(Lakehouse)架构的“微小变更”问题。


散热是另一个关键挑战。地球上的数据中心依赖空气或液体将热量从系统中带走,在轨道上,没有空气,因此热量必须通过辐射散发,这种方式速度较慢,且难以实现规模化。

企业AI落地并没有那么顺利,有数据指出过去超过90%的AI项目没有带来预期价值。这波OpenClaw热潮,如何才能穿过AI落地的迷雾,实现价值提升,更值得关注与思考。

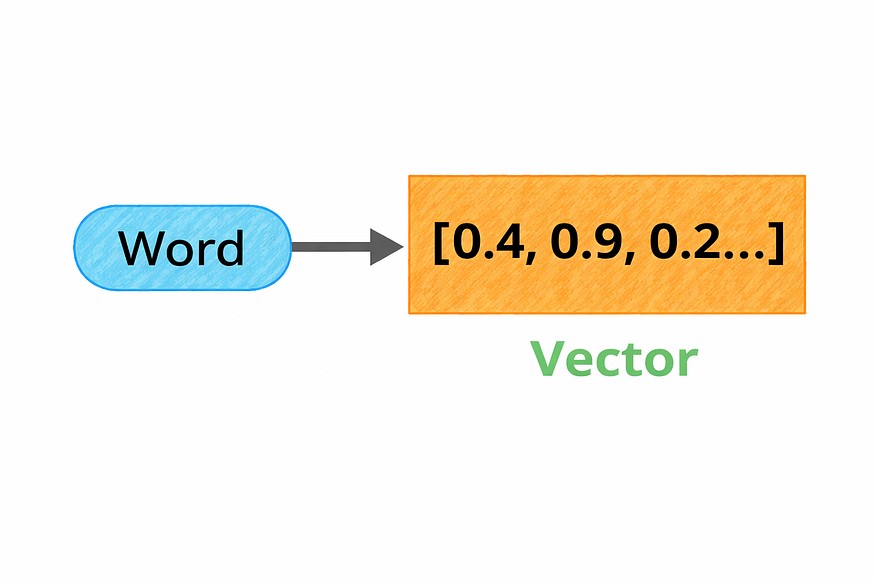
在这篇文章中,我将用最简单的方式来讲解20个最重要的AI概念。没有晦涩难懂的术语,没有故弄玄虚,只有清晰明了的解释和直观的例子,正是我希望当初有人能这样解释给我听的。
文章探讨了AI时代命令行界面(CLI)相对于图形用户界面(GUI)的优势。作者指出,CLI是AI的“母语”,能高效处理文本和结构化任务,而GUI主要为人类设计。随着AI智能体的发展,CLI在自动化运维等场景中展现出更高生产力。

文章来自 AgentC2的编辑团队,是一份面向 CTO 的分步指南,帮助其从个人 OpenClaw 智能代理迁移至具备治理机制的企业级 AI 智能代理部署。虽然有一定的立场倾向,但是其中关于 OpenClaw 的思考和实践可以借鉴。

据CNBC报道,埃隆·马斯克与OpenAI双方的法律纠纷进一步升级,马斯克正寻求通过诉讼罢免OpenAI首席执行官萨姆·奥尔特曼和总裁格雷格·布罗克曼的职务,并“撤销OpenAI的营利化转型与重组”。

下一阶段将呈现不同面貌。扩展AI不再仅仅是向前推进,而是要在各种制约因素之间寻求平衡:计算能力与能源之间,资本与回报之间,国家利益与全球供应链之间。

尽管目前超过三分之一的美国人每周都会使用AI,但仅有5%的人表示对AI非常有信心。我们正生活在一个使用AI却尚未信任AI的世界,仅靠增加投入无法解决这一问题。

- DBA如何确保AI真正创造价值?
- IDC首发智能体开发平台市场份额报告——私有化初具规模,公有云商业化起步
- 蚂蚁数科位列非云厂商第一!IDC首发中国智能体开发平台私有化市场排名
- 三成央企核心系统首选!OceanBase发布“央国企AI一体化数据解决方案”
- 从“数据结构+算法=程序”到“数据+业务规则=应用”
- Tiger Data推出Ghost,一款专为智能代理时代打造的数据库服务
- 搞定运维脚本里的龙宫探宝
- Neo4j收购GraphAware,推出可替代Palantir的情报分析解决方案
- 火山引擎开源数仓项目ByConity宣布即将退休
- AI员工上岗电站!蚂蚁数科推出电力交易与新能源运营智能体