HashData携手中国移动 共筑通信技术数字化之路
背景
近年来,随着宽带接入技术、移动通信技术的发展,互联网业务应用迅速扩张,其中移网和固网的网络与业务发展更为迅猛。工信部印发的《上网日志留存规范》通知明确要求,全量数据的留存元素包括:NAT后用户公网IP地址、NAT后源端口、用户私网IP地址、WLAN上网帐号、用户访问URL、目的IP、目的端口、访问时间等。根据相关的政策法规,中国移动河南分公司率先开始了日志溯源技术措施的建设,不仅实现了全网范围内上网用户的日志查询、内容审计功能,同时满足大量相关需求。
| 旧挑战,新思路
在最初的日志建设中,方向是重存储,轻分析。采用以Hadoop技术体系为主,整合MR+Hive SQL+HDFS+Flum的传统架构方案进行支撑:
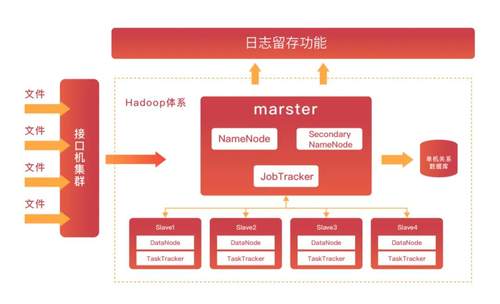
这一策略带来了三个显著问题:首先由于存储的数据激增带来数据有效利用率降低的问题,数据存储的成本持续升高 ; 其次,因为计算能力和存储紧密的耦合,系统无法灵活扩容存储空间,集群架构的数据分析能力较弱,从而导致应用端无法实现多种数据融合分析,且多并发能力不足、查询效率不高;最后,存储访问也存在较大瓶颈,无法支持海量数据按需扩展,产生的运维和建设成本难以满足海量日志分析需求。
面临多重挑战,中国移动河南分公司明确了新建设思路:按照集中化的方式建设日志留存系统,在满足相关政策和业务的前提下应考虑后期的系统扩展,将采集数据统一上报至省日志留存平台,完成省日志数据的统一存储、数据关联分析、以及汇聚分发等功能,按需向各种应用提供各类数据服务。
新的思路对架构重构提出了更高的目标,希望实现以下四个能力:
1. 满足数据量大,可采集汇总现网用户网络行为数据;
2. 实时性强,数据处理以批处理和准实时处理为主,数据可持续不断的接入汇总 ;
3. 数据查询处理以SQL查询为主,多字段关联查询需求多,单表大;
同时面向多个应用系统或者数据需求方,具备高处理性能和资源隔离性。
| 高可用、高弹性、高扩展性的新一代HashData架构方案
为实现这一目标,HashData以对象存储为基础,计算集群和存储集群分离,集群扩容业务不停,产品架构如下:
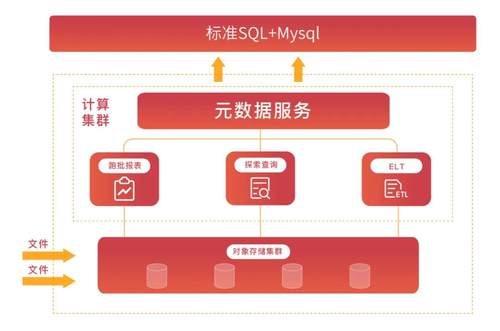
在确保计算单元与数据存储有着明确的逻辑对应关系和集群I/O吞吐不下降的前提下,通过巧妙的缓存策略设计可以享受计算存储分离带来的好处,包括高可用性、多维度弹性、高扩展性等。
其中独立元数据服务是完全创新性的云原生架构,元数据状态从计算节点中消除,使得计算节点变得完全没有状态(新型的shared-everything MPP架构与传统的shared-nothing架构对应) 。尽管每个计算节点都没有状态,但面临需要增加节点数量时,仍可以访问到系统中的任何数据与任何元数据。
新架构的主要策略是在满足数据快速增长的情况下实现“存储资源虚拟化,计算资源最大化”,对日志留存平台的数据转发和数据分析提供最大限度的支撑。
| 节省 40% 的集群规模,降本提效
HashData产品使用了自带ETL工具代替Flume,对象存储代替HDFS;计算包含Hadoop方案中的清洗+计算, 通过自定义函数UDF代替Hadoop方案中的清洗和计算,自带有向无环图的数据结构和算法以方便替换;同时标准SQL和自定义函数UDF代替MR,产品实现日志留存功能技术路径如下:
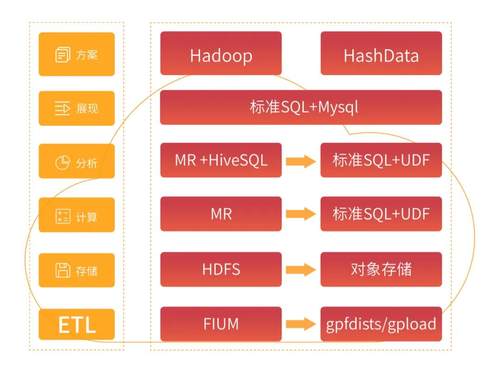
综上所述,在计算和存储分离的产品架构中,独立扩展的计算和存储表现更加灵活,可显著降低存储成本。HashData整体实现了日志留存系统,在保证和原Hadoop体系存储数据相同的情况下仅使用原集群规模的40%左右,应用开发周期缩短了50%,查询性能提升了一个数量级,充分实现了降本提效的目的。
| 小结
HashData融合了MPP数据库的高性能与丰富的分析功能、大数据平台的扩展性和灵活性,以及云计算的弹性和敏捷性等优势。在此项目的建设中为中国移动河南分公司构筑了新一代企业级云端数据仓库,真正实现了降本提效,未来双方将在共筑通信技术的数字化之路上继续携手前行!

