向量数据库:从AI热潮到如何落地的真实思考
专用向量数据库并非新生事物,如Milvus等,它们早已问世,并主要被设计用于非结构化多模态数据的高效检索。这类数据库满足了诸如以图搜图(类似于淘宝的拍立淘功能)、以音搜音(类似音乐识别应用Shazam)以及用视频搜视频等特定需求。同时,PostgreSQL生态系统中的pgvector、pase等插件也提供了类似的功能。然而,尽管这些技术在特定领域内有一定的应用,但由于其相对小众的需求,长期以来并未引起广泛的关注。
向量数据库爆火“缘起”
然而,随着OpenAI及其ChatGPT等大型语言模型的出现,这一切发生了翻天覆地的变化。这些先进的AI模型展现出了对多种形式文本、图片和音视频的深刻理解能力,并且能够将它们统一编码为相同维度的向量。这一创新的重要性在于,它使得向量数据库在存储和检索这些AI大模型生成的嵌入向量(embedding)方面发挥了至关重要的作用。
具体来说,大型语言模型如ChatGPT通过深度学习技术,将不同模态的数据(文本、图像、音视频等)转化为高维空间的向量表示。这些向量捕捉了数据的内在特征和语义信息,使得相似数据在向量空间中的距离更近。向量数据库,如Milvus,则提供了高效存储和查询这些向量的能力。它们利用近似最近邻搜索(ANN)等算法,在海量数据中快速找到与查询向量最相似的结果。
因此,OpenAI/ChatGPT等技术的兴起不仅改变了我们对AI能力的认知,还极大地推动了向量数据库的应用和发展。如今,这些原本小众的向量数据库正逐渐成为支撑AI应用的重要基础设施,助力实现更加智能和高效的数据检索与分析。
向量数据库在今年的科技浪潮中迎来了一个显著的增长节点,具体在3月23日,当OpenAI发布chatgpt-retrieval-plugin项目时,推荐将向量数据库作为增强ChatGPT插件“长期记忆”功能的关键组件。自此之后,无论是在Google Trends的搜索热度上,还是在Github的Star数量上,向量数据库项目都呈现出爆发式的增长态势。与此同时,沉寂了一段时间的数据库投资领域也迎来了新的生机,Pinecone、Qdrant、Weaviate等“专用向量数据库”公司纷纷崭露头角,竞相融资数亿,唯恐错过这场AI时代基础设施建设的盛宴。
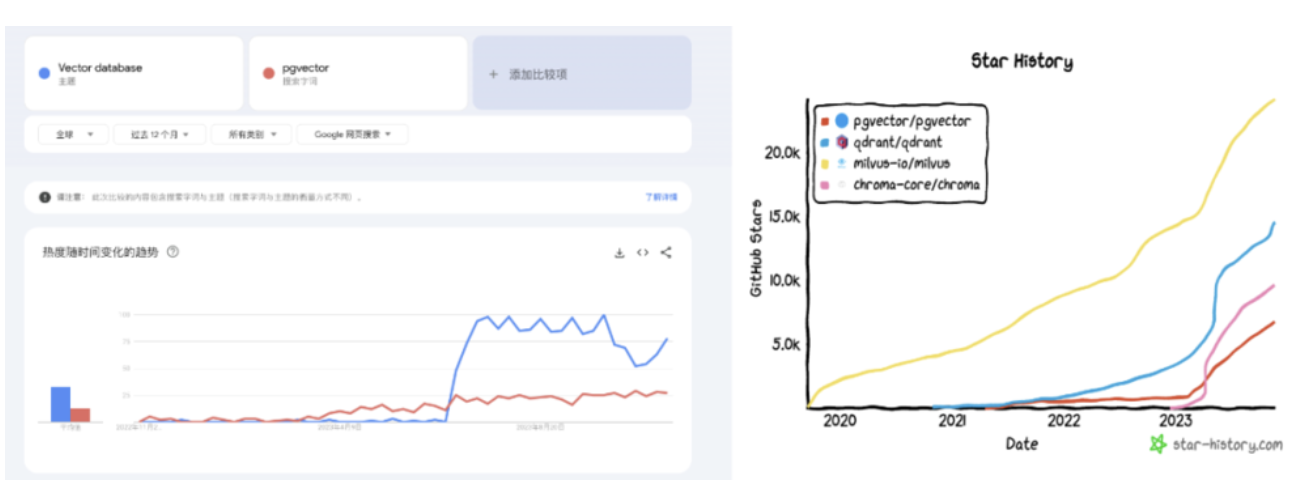
Google Trens 与 Github Star
与此同时,数据库领域在投资领域沉寂了一段时间后,又迎来了一波小阳春 —— Pinecone,Qdrant,Weaviate 诸如此类的“专用向量数据库”冒了出来,几亿几亿的融钱,生怕错过了这趟 AI 时代的基础设施快车。

向量数据库生态全景图
然而,这股向量数据库的狂热浪潮终究难逃剧烈波动的命运。其高涨的势头在短短半年内便迅速降温,形势发生了翻天覆地的变化。如今,除了少数二线厂商仍在追赶末班车,试图通过软文营销来吸引眼球,已经鲜少有人再热衷于炒作专用向量数据库这一话题,昔日的热潮已渐渐退却。

向量数据库:真实需求还是伪需求?
在讨论向量数据库是否为伪需求时,我们首先要认识到向量的存储与检索是AI发展中一个真实且不断增长的需求。然而,这并不意味着专用的向量数据库是满足这一需求的必然选择。
专用向量数据库的局限性:早期的专用向量数据库如Pinecone、Weaviate等,虽然在解决AI模型记忆能力不足的问题上有所贡献,但随着AI技术的进步,尤其是GPT-4等模型上下文处理能力的显著提升,这些数据库的作用逐渐减弱。
GPTs 将 AI 的易用性提高到一个全新的层次
OpenAI GPTs功能的冲击:OpenAI推出的GPTs功能为中小知识库场景提供了完整的“记忆”与“知识库”解决方案,进一步挤压了专用向量数据库的市场空间。用户无需配置复杂的向量数据库,只需上传知识文件并编写提示词,即可快速开发出AI Agent。
经典数据库的向量扩展:与此同时,PostgreSQL、Redis等经典数据库系统纷纷推出了向量扩展功能,这些扩展不仅性能稳定可靠,而且与现有系统无缝集成。用户无需引入新的专用向量数据库系统,即可轻松实现向量数据的存储与检索。
技术门槛与开源库的应用:尽管数据库系统本身具有一定的技术门槛,但向量数据处理的技术门槛相对较低。成熟的开源库如FAISS、SCANN等已经足够满足大多数场景的需求。对于大厂来说,利用这些开源库实现向量数据处理功能既简单又高效,无需额外引入专用向量数据库系统。
尽管向量的存储与检索是真实需求,但专用向量数据库并非满足这一需求的唯一途径。随着AI技术的进步和经典数据库的向量扩展功能的推出,专用向量数据库的市场空间将受到进一步压缩。因此,从逻辑性和清晰度的角度来看,我们可以认为专用向量数据库在一定程度上是一个伪需求。
专用向量数据库陷入了一个死局之中:小需求 OpenAI 亲自下场解决了,标准需求被加装向量扩展的现有成熟数据库抢占,超大需求也几乎没什么实现的门槛。留给专用向量数据库的生态位也许能足以支持一家专用向量数据库内核厂商活下来,但想做成一个产业是不可能了。
通用数据库与专用向量数据库的比较
在探讨通用数据库与专用向量数据库时,我们首先要明确一个合格的向量数据库不仅应具备向量的存储与检索能力,还需满足数据库的基本标准和要求。然而,从市场现状来看,通用数据库与专用向量数据库之间存在显著的差异。笔者在采访中也听到了众多用户和开发者的声音。
通用数据库,如PostgreSQL,经过数十年的发展,已经相当成熟和完善。它们支持多种数据类型、提供备份/恢复机制、高可用性等关键功能,并通过数百万行的代码解决了数据库领域的复杂问题。
相比之下,专用向量数据库的设计则显得相对简单。尽管它们专注于向量的存储与检索,但从技术门槛的角度来看,向量部分的实现难度远低于通用数据库。以pgvector为例,这个基于PostgreSQL的向量数据库扩展仅用不到两千行代码就解决了向量问题,这凸显了向量与数据库之间复杂度的巨大差异。
专用向量数据库的简化设计也引发了一些质疑。例如有些用户表示,由于它们过于专注于向量功能,往往忽略了数据库的其他关键特性,如数据类型多样性、备份恢复机制等。这种简化设计可能导致在实际应用中面临诸多限制和挑战。
从技术门槛的角度来看,实现一个专用向量数据库可能并不需要深厚的数据库专业知识。基本的数组数据结构、排序算法和向量点积计算等知识点对于稍有编程经验的本科生来说并不陌生。因此,专用向量数据库的技术门槛相对较低,难以形成独特的竞争优势。
pgvector与Pinecone:通用与专用向量数据库的较量
在向量数据库领域,pgvector与Pinecone的对比凸显了通用与专用数据库之间的显著差异。pgvector作为PostgreSQL的向量扩展,不仅功能强大,而且正在迅速占领市场。而Pinecone,虽作为专用向量数据库SaaS的佼佼者,却在多个关键维度上显露出不足。
首先,性能方面,Pinecone引以为傲的高性能在实际测试中却不及pgvector。在Supabase的测试案例中,pgvector在延迟表现、总体吞吐以及成本上均优于Pinecone,这直接挑战了专用向量数据库的性能神话。实际上,在AI应用中,向量检索的性能往往并非决定性因素,因为模型推理的开销往往远超向量检索。
其次,易用性上,Pinecone的专用Python API与pgvector的通用SQL Interface各有优劣,但真正的挑战在于混合检索的需求。在实际应用中,我们往往需要结合向量检索与关系型数据库的元数据来进行综合查询,这时pgvector的SQL接口无疑更具优势。Pinecone虽然支持附加元数据,但基于API的设计使其扩展性和可维护性受限。
更重要的是,Pinecone在数据库基础功能方面存在明显不足,如备份/恢复/高可用、批量更新/查询操作、事务/ACID等,这些功能对于生产环境至关重要。此外,Pinecone在召回率与响应速度之间的权衡上也显得过于简单,缺乏灵活性。
与此同时,pgvector等通用数据库加装向量功能的方案,不仅成本更低,而且功能更全面、性能更稳定。这些通用数据库已经拥有庞大的用户基础和成熟的生态系统,加装向量功能后能够迅速满足市场需求。
因此,尽管向量的存储与检索是AI时代的重要需求,但专用向量数据库的市场前景并不乐观。pgvector等通用数据库的崛起已经预示着专用向量数据库的衰落。对于寻求稳定、可靠解决方案的用户来说,选择pgvector等通用数据库加装向量功能的方案无疑是明智之举。
参考资料:
[1] 为什么我们用 PGVector 替换了 Pinecone: https://medium.com/@jeffreyip54/why-we-replaced-pinecone-with-pgvector-2f679d253eba

