在RAG中使用PostgreSQL作为向量数据库
如何使用Postgres、pgvector扩展、Ollama和Llama 3大型语言模型构建本地检索增强生成应用程序。
带有pgvector扩展的PostgreSQL允许将表用作向量的存储,每个向量都保存为一行。它还允许添加任意数量的元数据列。在企业应用程序中,这种同时存储向量和表格数据的混合功能为开发人员提供了纯向量数据库中无法提供的灵活性。
虽然纯向量数据库可以调整为极高性能,但pgvector可能不是。然而,对于中型检索增强生成(RAG)应用程序(通常涉及约10万个文档),pgvector的性能绰绰有余。如果您正在为小组或小型部门构建知识管理应用程序,这种架构是一个简单的开始方式。(对于更小的单用户应用程序,您可以使用带有sqlite-vss扩展的SQLite。)
正如许多开发人员已经意识到的那样,“只需使用Postgres”通常是一个很好的策略。如果您的需求增长,您可能想要交换一个更大、性能更强的向量数据库。在那之前,Postgres将完成这项工作,并允许我们快速构建应用程序。
审查检索-增量生成
在您开始之前,您可能会发现回顾我之前关于构建RAG应用程序的两篇文章会有所帮助:
• 检索-增量生成,一步一步
• 完全本地检索-增量生成,一步一步
在第一篇文章中,我们使用Python、LangChain和OpenAI聊天模型构建了一个简单的“你好世界”RAG应用程序。我们使用OpenAI嵌入API生成嵌入,将这些嵌入保存在本地向量存储(FAISS)中,然后向OpenAI聊天模型询问了两个关于检索到的文档的两个问题,即拜登总统2023年2月7日的国情咨文。
为了刷新我们对RAG中工作流程的记忆,步骤如下:
1 我们分割了文本文档,并向OpenAI的嵌入API提交了一组块。
2 我们拿回了一组具有块浮点编码的向量——每个块一个浮点的向量。这些是文档的嵌入。
3 我们使用Faiss来存储这些编码的块或嵌入,并在上面进行相似性搜索。
4 我们创建了一个查询,并用它来对嵌入存储进行相似性搜索,找回那些可能包含用于回答我们查询的有用上下文的块。
5 我们通过聊天界面向OpenAI提交了查询和上下文的组合。
6 我们收到了OpenAI的回复,在我们块中相关信息的背景下回答了我们的问题。
在第二篇文章中,我们做了一个同等的练习,但相反,我们在本地运行了所有内容,这样就不会有信息离开该处所。这是我们朝着在企业中务实和相关地使用RAG的第一步。我们用来自名为Sentence Transformers的库的本地运行的嵌入生成器替换了OpenAI的嵌入API。我们使用带有sqlite-vss扩展的SQLite作为我们的本地向量数据库。我们使用Ollama在本地运行Llama 2大型语言模型。
现在,我们将更深入地研究向量数据库,到目前为止,它一直是一个神秘的黑匣子。通过使用Postgres作为向量存储的基础,我们可以使用熟悉的工具来查看内部并检查向量数据库中存储的内容。通过使用熟悉的主力产品Postgres,我们将尝试从向量数据库中取出一些谜团。
RAG与Postgres分成两部分
在这次探索中,我们将分两部分进行编码。首先,我们将将多个维基百科条目的文本摄取到单个向量数据库中。其次,我们将使用Postgres和SQL对该文本进行相似性搜索,然后使用结果查询Ollama运行的本地大型语言模型。
要创建知识库,我们需要将多种文档导入向量数据库的方法。为此,我们可以使用LangChain或LlamaIndex等库中的加载器和解析器。对于特别大或复杂的PDF文档,我们可能需要专门用于PDF的库。Java和Python中有几个这样的库。请注意,对于带有嵌入式图像或表格的PDF,您可能需要结合技术,特别是通过Tesseract的OCR,来提取隐藏在这些图像和表格中的数据。
让我们仔细看看我们的两部分。代码已详细记录,因此我们将首先概述每个部分的步骤,然后展示代码。
第1部分。在Postgres中创建一个向量数据库
在第1部分中,我们在Postgres中创建一个向量数据库,并填充来自一组向量化HTML页面的数据。步骤:
1 我们安装了名为pgvector的Postgres扩展,它使表具有向量类型的列,其中向量是一组浮点。在这个例子中,我们使用一个768维的向量,即长度为768的向量。
2 我们创建一个表格,将为我们的知识库保存文章——每篇文章的文本、文章的标题和文章文本的向量嵌入。我们命名表格articles和列title、text和embedding。
3 我们在四个维基百科URL上提取内容,并将每个URL的标题和内容分开。
4 我们清理每篇文章的正文,将文本分成500个字符的块,并使用嵌入模型从每个块创建768维向量。向量是文本块含义的数值表示(浮点)。
5 我们将标题、主体中的块和块的嵌入向量保存在数据库的一行中。对于每篇文章,向量的数量与块数量一样多。
6 我们在第2部分中对相似性搜索的向量列进行索引。
import psycopg2
from sentence_transformers import SentenceTransformer
import requests
from bs4 import BeautifulSoup
import re
import ollama
# Your connection params here
MY_DB_HOST = 'localhost'
MY_DB_PORT = 5432
MY_DB_NAME = 'nitin'
MY_DB_USER = 'nitin'
MY_DB_PASSWORD = ''
# Set up the database connection
conn = psycopg2.connect(
host=MY_DB_HOST,
port=MY_DB_PORT,
dbname=MY_DB_NAME,
user=MY_DB_USER,
password=MY_DB_PASSWORD
)
cur = conn.cursor()
# Create the articles table with the pgvector extension
# If the pgvector extension is not installed on your machine it will need to be installed.
# See https://github.com/pgvector/pgvector or cloud instances with pgvector installed.
# First create the pgvector extension, then a table with a 768 dim vector column for embeddings.
# Note that the title and full text of the article is also saved with the embedding.
# This allows vector similarity search on the embedding column, returning matched text
# along with matched embeddings depending on what is needed.
# After this SQL command is executed we will have
# a) a pgvector extension installed if it did not already exist
# b) an empty table with a column of type vector along with two columns,
# one to save the title of the article and one to save a chunk of text.
# Postgres does not put a limit on the number of dimensions in pgvector embeddings.
# It is worth experimenting with larger lengths but note they need to match the length of embeddings
# created by the model you use. Embeddings of ~1k, 2k, or more dimensions are common among embeddings APIs.
cur.execute('''
CREATE EXTENSION IF NOT EXISTS vector;
DROP TABLE IF EXISTS articles;
CREATE TABLE articles (
id SERIAL PRIMARY KEY,
title TEXT,
text TEXT,
embedding VECTOR(768)
);
''')
conn.commit()
# Below are the sources of content for creating embeddings to be inserted in our demo vector db.
# Feel free to add your own links but note that different sources other than Wikipedia may
# have different junk characters and may require different pre-processing.
# As a start try other Wikipedia pages, then expand to other sources.
urls= [
'https://en.wikipedia.org/wiki/Pentax_K-x',
'https://en.wikipedia.org/wiki/2008_Tour_de_France',
'https://en.wikipedia.org/wiki/Onalaska,_Texas',
'https://en.wikipedia.org/wiki/List_of_extinct_dog_breeds'
]
# Fetch the HTML at a given link and extract only the text, separating title and content.
# We will use this text to extract content from Wikipedia articles to answer queries.
def extract_title_and_content(url):
try:
response = requests.get(url)
if response.status_code == 200: # success
# Create a BeautifulSoup object to parse the HTML content
soup = BeautifulSoup(response.content, 'html.parser')
# Extract the title of the page
title = soup.title.string.strip() if soup.title else ""
# Extract the text content from the page
content = soup.get_text(separator=' ')
return {"title": title, "text": content}
else:
print(f"Failed to retrieve content from {url}. Status code: {response.status_code}")
return None
except requests.exceptions.RequestException as e:
print(f"Error occurred while retrieving content from {url}: {str(e)}")
return None
# Create the embedding model
# This is the model we use to generate embeddings, i.e. to encode text chunks into numeric vectors of floats.
# Sentence Transformers (sbert.net) is a collection of transformer models designed for creating embeddings
# from sentences. These are trained on data sets used for different applications. We use one tuned for Q&A,
# hence the 'qa' in the name. There are other embedding models, some tuned for speed, some for breadth, etc.
# The site sbert.net is worth studying for picking the right model for other uses. It's also worth looking
# at the embedding models of providers like OpenAI, Cohere, etc. to learn the differences, but note that
# the use of an online model involves a potential loss of privacy.
embedding_model = SentenceTransformer('multi-qa-mpnet-base-dot-v1')
articles = []
embeddings = []
# Extract title,content from each URL and store it in the list.
for url in urls:
article = extract_title_and_content(url)
if article:
articles.append(article)
for article in articles:
raw_text = article["text"]
# Pre-processing: Replace large chunks of white space with a space, eliminate junk characters.
# This will vary with each source and will need custom cleanup.
text = re.sub(r'\s+', ' ', raw_text)
text = text.replace("]", "").replace("[", "")
# chunk into 500 character chunks, this is a typical size, could be lower if total size of article is small.
chunks = [text[i:i + 500] for i in range(0, len(text), 500)]
for chunk in chunks:
# This is where we invoke our model to generate a list of floats.
# The embedding model returns a numpy ndarray of floats.
# Psycopg coerces the list into a vector for insertion.
embedding = embedding_model.encode([chunk])[0].tolist()
cur.execute('''
INSERT INTO articles (title, text, embedding)
VALUES (%s, %s, %s); ''', (article["title"], chunk, embedding)
)
embeddings.append(embedding)
conn.commit()
# Create an index
# pgvector allows different indexes for similarity search.
# See the docs in the README at https://github.com/pgvector/pgvector for detailed explanations.
# Here we use 'hnsw' which is an index that assumes a Hierarchical Network Small Worlds model.
# HNSW is a pattern seen in network models of language. Hence this is one of the indexes
# that is expected to work well for language embeddings. For this small demo it will probably not
# make much of a difference which index you use, and the others are also worth trying.
# The parameters provided in the 'USING' clause are 'embedding vector_cosine_ops'
# The first, 'embedding' in this case, needs to match the name of the column which holds embeddings.
# The second, 'vector_cosine_ops', is the operation used for similarity search i.e. cosine similarity.
# The same README doc on GitHub gives other choices but for most common uses it makes little difference
# hence cosine similarity is used as our default.
cur.execute('''
CREATE INDEX ON articles USING hnsw (embedding vector_cosine_ops);
''')
conn.commit()
cur.close()
conn.close()
# End of file
第2部分。从向量数据库中检索上下文并查询LLM
在第2部分中,我们提出了一个知识库的自然语言问题,使用相似性搜索来查找上下文,并使用LLM(在这种情况下是Meta的Llama 3)在提供的上下文中生成问题的答案。步骤:
1 我们使用与从维基百科页面中提取的文本块相同的嵌入模型将自然语言查询编码为向量。
2 我们使用SQL查询对该向量进行相似性搜索。相似性,或特别是cosine相似性,是在我们的数据库中查找与向量查询最接近的向量的一种方式。一旦我们找到最近的向量,我们就可以使用它们检索与每个向量一起保存的相应文本。这就是我们对法学硕士的查询的背景。
3 我们将此上下文附加到我们的自然语言查询文本中,明确告诉LLM,提供的文本将作为回答查询的上下文。
4 我们使用围绕Ollama的编程包装器将自然语言查询和上下文文本传递到LLM的请求API并获取响应。我们提交了三个查询,并在上下文中收到每个查询的答案。下面显示了第一个查询的示例屏幕截图。
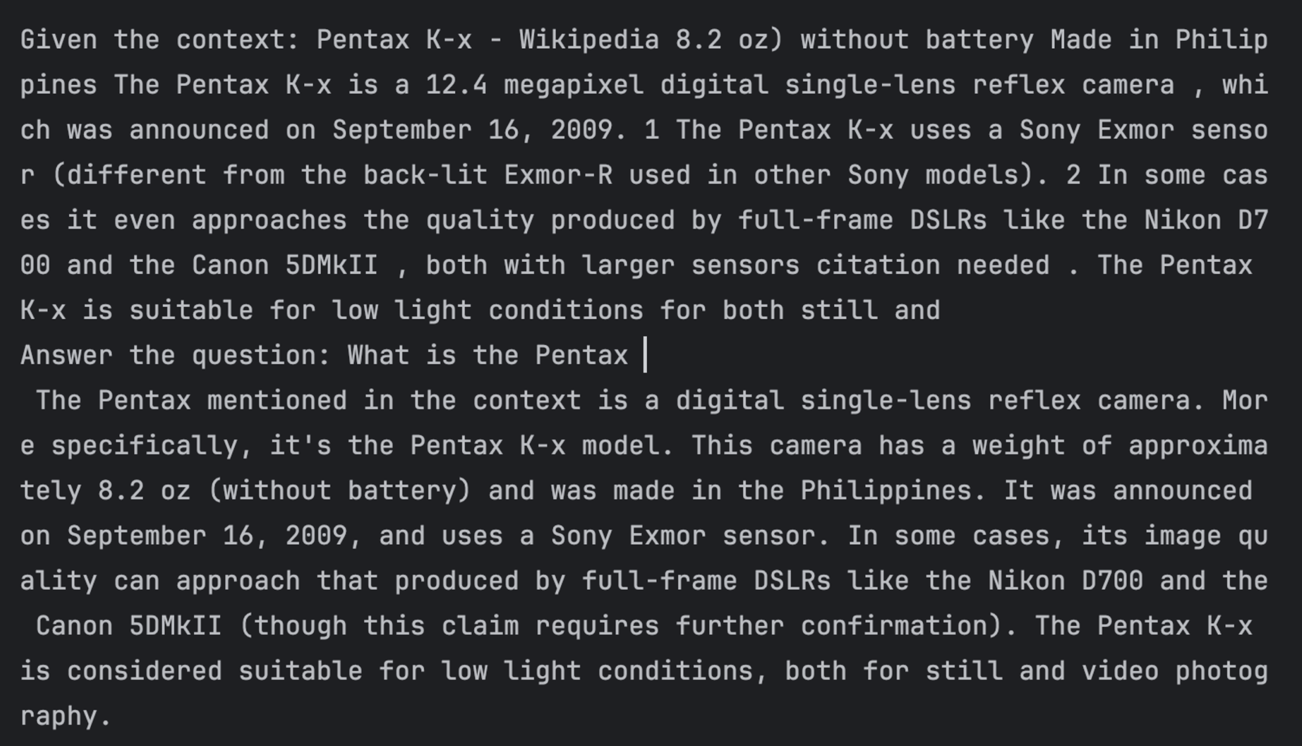
import psycopg2
import ollama
import re
from sentence_transformers import SentenceTransformer
# Your connection params and credentials here
MY_DB_HOST = 'localhost'
MY_DB_PORT = 5432
MY_DB_NAME = 'nitin'
MY_DB_USER = 'nitin'
MY_DB_PASSWORD = ''
# Note that this model needs to be the same as the model used to create the embeddings in the articles table.
embedding_model = SentenceTransformer('multi-qa-mpnet-base-dot-v1')
# Below are some low-level functions to clean up the text returned from our Wikipedia URLs.
# It may be necessary to develop small custom functions like these to handle the vagaries of each of your sources.
# At this time there is no 'one size fits all' tool that does the cleanup in a single call for all sources.
# The 'special_print' function is a utility for printing chunked text on the console.
def chunk_string(s, chunk_size):
chunks = [s[i:i+chunk_size] for i in range(0, len(s),chunk_size)]
return '\n'.join(chunks)
def clean_text(text):
text = re.sub(r'\s+', ' ', text)
return text.replace("[", "").replace("]", "")
def special_print(text, width=80):
print(chunk_string(clean_text(text), width))
return
def query_ollama(query, context):
# Note: The model can be changed to suit your available resources.
# Models smaller than 8b may have less satisfactory performance.
response = ollama.chat(model='llama3:8b', messages=[
{
'role': 'user',
'content': context + query,
},
])
response_content = response['message']['content']
special_print(context + "\n")
special_print(query + "\n")
special_print(response_content + "\n")
return response_content
# Create sample queries
# Set up the database connection
conn = psycopg2.connect(
host=MY_DB_HOST,
port=MY_DB_PORT,
dbname=MY_DB_NAME,
user=MY_DB_USER,
password=MY_DB_PASSWORD
)
cur = conn.cursor()
# There are 3 queries each focused on one of the 4 pages we ingested.
# One is deliberately left out to make sure that the extra page does not create hallucinations.
# Feel free to add or remove queries.
queries = [
"What is the Pentax",
"In what state in the USA is Onalaska",
"Is the Doberman Pinscher extinct?"
]
# Perform similarity search for each query
for query in queries:
# Here we do the crucial step of encoding a query using the same embedding model
# as used in populating the vector db.
query_embedding = embedding_model.encode([query])[0].tolist()
# Here we fetch the title and article text for the top match using cosine similarity search.
# We pass in the embedding of the query text to be matched.
# The query embedding will be matched by similarity search to the closest embedding in our vector db.
# the operator is the cosine similarity search.
# We are asking for the top three matches ordered by similarity.
# We will pick the top one; we could just as easily have asked for the top one via 'LIMIT 1'.
cur.execute('''
SELECT title, text
FROM articles
ORDER BY embedding CAST(%s as vector)
LIMIT 3;
''', (query_embedding,))
result = cur.fetchone()
if result:
article_title = result[0]
relevant_text = result[1]
#special_print(f"Query: {query}")
#special_print(f"Relevant text: {relevant_text}")
#special_print(f"Article title: {article_title}")
print("------------------------------------------\n")
# Format the query to the LLM giving explicit instructions to use our search result as context.
query_ollama("Answer the question: " + query + "\n", "Given the context: " + "\n" + article_title + "\n" + relevant_text + "\n")
else:
print(f"Query: {query}")
print("No relevant text found.")
print("---")
# Close the database connection
cur.close()
conn.close()
# End of file
请注意,这与我们在早期文章中采用的方法相同,除了我们使用带有向量扩展的Postgres。这允许我们依赖熟悉的SQL概念,但使用单个额外的运算符(<==>),并通过已安装的pgvector扩展扩展我们的RDBMS知识,以涵盖向量数据。因此,我们可以透明地看到RAG调查过程的每一步正在发生的事情。
在这里,我们没有使用LangChain检索链、OpenAI嵌入API或OpenAI聊天模型,所有这些都是黑匣子。在这里,我们可以检查数据库表的内容,我们可以看到进行相似性搜索的SQL的语法,我们可以看到搜索返回的内容,以及它如何将其用作将查询传递给LLM的上下文。甚至我们发送给LLM的查询也是可修改的。
如果我们将此与我们在第一篇文章中逐步完成的本地RAG实现进行比较,该技术更加透明,步骤现在更精细。
https://www.infoworld.com/article/3516109/using-postgresql-as-a-vector-database-in-rag.html

