开源向量数据库比较:Chroma, Milvus, Faiss,Weaviate
语义搜索和检索增强生成(RAG)正在彻底改变我们的在线交互方式。实现这些突破性进展的支柱就是向量数据库。选择正确的向量数据库能是一项艰巨的任务。本文为你提供四个重要的开源向量数据库之间的全面比较,希望你能够选择出最符合自己特定需求的数据库。
什么是向量数据库?

向量数据库是一种将数据存储为高维向量的数据库,高维向量是特征或属性的数学表示。每个向量都有一定数量的维度,根据数据的复杂性和粒度,可以从数十到数千不等。
向量通常是通过对原始数据(如文本、图像、音频、视频等)应用某种转换或嵌入函数来生成的。嵌入函数可以基于各种方法,如机器学习模型、词嵌入和特征提取算法。
向量数据库的主要优点是,它允许基于数据的向量距离或相似性进行快速和准确的相似性搜索和检索。
这意味着不用使用基于精确匹配或预定义标准查询数据库的传统方法,而是可以使用向量数据库根据语义或上下文含义查找最相似或最相关的数据。
为什么需要向量数据库?
可以通过将向量嵌入到向量数据库中来索引它们,通过搜索周围向量来定位相关的信息。
在传统领域,开发人员可以使用不同类型的机器学习模型来自动从扫描文档和照片等数据中提取元数据。然后用向量索引信息,通过关键字和向量的混合搜索改善搜索结果,还可以将语义理解与相关性排名结合起来。
最新的生成式人工智能(GenAI)的创新带来了新型模型,如ChatGPT,它可以生成文本并处理复杂的人机交互。例如,一些模型允许用户描述风景,然后创建与描述相匹配的图片。但是生成模型在提供不正确的信息时容易产生幻觉。向量数据库正好可以帮助解决这个问题。通过向量数据库补充生成人工智能模型和外部知识库,以确保它们提供可靠的信息。
Chroma

向量数据库 Chroma 是一种专门设计用来高效管理和查询向量数据的数据库系统。Chroma 通过其高效的数据结构和算法优化,能够快速处理和检索大量的向量数据。
以下是 Chroma 向量数据库的一些主要特点:
高效的向量索引:Chroma 使用高效的索引结构,如倒排索引、KD-树或基于图的索引,以加快向量搜索速度;
支持多种相似度度量:它支持多种向量相似度度量标准,包括欧氏距离、余弦相似度等,使其可以广泛应用于不同的应用场景;
可扩展性和弹性:Chroma 能够支持水平扩展,适应大规模数据集的需要。同时,它也能有效处理数据的动态变化,适应快速发展的存储需求;
易于集成和使用:Chroma 设计有易于使用的API接口,支持多种编程语言接入,便于开发者在不同的系统和应用中集成使用;
实时性能优化:Chroma 优化了查询处理过程,支持实时的数据查询和更新,满足实时分析和决策的需求。
Milvus

Milvus 提供了高效的向量检索能力,特别适合用于机器学习和人工智能领域,如推荐系统、图像检索和自然语言处理等。Milvus 支持海量数据的快速检索,以及灵活的数据更新和扩展功能。
以下是 Milvus 的一些关键特点:
高效的向量索引:Milvus 支持多种索引类型,如倒排索引、HNSW、IVF 等,用户可以根据具体需求选择最合适的索引策略来优化检索性能;
多种相似度度量:它支持多种相似度计算方法,包括欧氏距离、余弦相似度等,以满足不同场景下的需求;
可扩展性:Milvus 能够在不同的硬件和平台上运行,支持在云环境中部署。其架构支持水平和垂直扩展,适应从小规模到大规模的应用需求;
强大的API支持:Milvus 提供了丰富的API,包括Python、Java、Go等多种语言的SDK,便于开发者集成和使用;
云原生支持:Milvus 支持在Kubernetes环境中部署,使得其能够利用云原生技术的优势,如容器化、微服务架构和自动化管理。
Milvus 的设计理念是提供一个灵活、高效和易于使用的向量数据管理平台,帮助用户解决在处理大规模复杂数据时遇到的挑战。它的开源特性也为广泛的社区合作提供了可能,使得其功能和性能不断得到提升和优化。
Faiss

Faiss 是由 Facebook AI Research(FAIR)开发的一个高效的库。Faiss 特别适合处理大量高维数据的相似度搜索任务,常用于机器学习和人工智能领域中的应用,如图像检索、视频推荐和自然语言处理等。
以下是 Faiss 的一些关键特性:
高效的索引结构:Faiss 提供多种索引结构和搜索算法,包括扁平(flat)索引、倒排文件(IVF)索引和基于量化的索引(如 PQ 和 OPQ)。这些索引能够在维护较高查询精度的同时,显著提高搜索速度;
支持批量查询:Faiss 设计了优化的批处理查询,能够同时处理多个查询,这样可以充分利用现代多核CPU的计算资源,提高处理速度;
灵活的距离计算:它支持多种距离计算方法,包括L2(欧氏距离)和内积,用户可以根据具体需求选择适合的度量方式;。
GPU加速:Faiss 还提供了GPU版本,可以利用GPU强大的并行处理能力来进一步加速向量搜索和聚类计算;
易于集成和使用:Faiss 可以与 Python 紧密集成,通过提供的 Python 接口,用户可以方便地在 Python 环境中使用 Faiss 进行数据处理和分析。
Faiss 的设计目标是提供一种既快速又准确的方式来搜索和聚类数十亿级别的向量数据。它的高效性使其在工业级应用中非常受欢迎,而开源的特性也使得社区能够持续对其进行改进和优化。
Weaviate

Weaviate 是一个开源的向量搜索引擎,它采用了最新的机器学习模型来优化向量搜索和存储。Weaviate 使用图数据结构来组织数据,支持高效的向量索引和近似最近邻(ANN)搜索。
以下是 Weaviate 的一些关键特性:
基于图的数据模型:Weaviate 使用图数据结构来存储和管理数据,每个数据点都作为图中的一个节点,这些节点可以通过边相互连接,以表示复杂的数据关系;
机器学习集成:Weaviate 直接集成了机器学习模型,如Transformer模型,用于自动将文本和其他数据类型转换成高维向量。这种集成简化了AI驱动应用的开发流程;
模块化和可扩展:Weaviate 的架构支持模块化,用户可以根据需要添加不同的模块来扩展功能,如自定义向量化模块或特定的数据连接器;
实时索引与查询:Weaviate 设计了实时数据索引和查询的能力,支持在大规模数据集上进行高效的向量搜索;
丰富的API和客户端支持:Weaviate 提供了RESTful API、GraphQL接口,以及多种客户端库(如Python、JavaScript),便于开发者使用和集成;
云原生和高可用性:Weaviate 是为云环境优化的,支持在Kubernetes上部署,确保了高可用性和弹性。
Weaviate 为开发者提供了一个功能强大、灵活且易于使用的向量搜索平台,特别适用于那些需要深入挖掘和理解大规模复杂数据集的应用。
比较
最后我们基于一些常用标准来比较这些开源向量数据库:
1、开源协议
作为项目的最主要的一个选择标准就是开源的协议类型。一般向量数据库类软件倾向于选择对商业和开源社区都友好的许可证,以鼓励技术的采用和发展。上面的四个库也不例外。

Faiss使用最开放的MIT,其他的库也都对商业使用友好。
2、关键特征对比
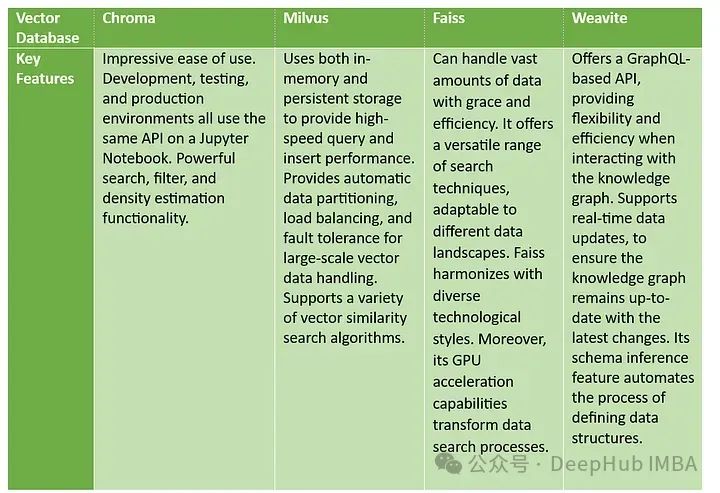
对比来看:
易用性: Chroma 强调在 Jupyter Notebook 上的易用性,而 Weaviate 则强调其 GraphQL API 的灵活性和效率;
存储与性能: Milvus 在存储和查询性能方面提供了内存与持久存储的结合,相比之下,Faiss 强调 GPU 加速能力在搜索过程中的作用;
数据处理与更新: Milvus 提供自动数据分区和容错,Weaviate 支持实时数据更新,确保数据的时效性;
搜索技术: Chroma 和 Milvus 都提到了它们对搜索算法的支持,而 Faiss 则提供了适应不同技术风格的搜索技术,Weaviate 使用 GraphQL 提高了数据结构定义的效率。
3、使用案例
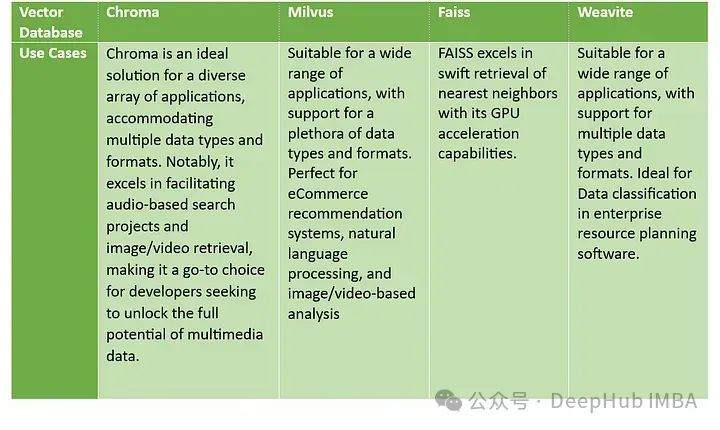
Chroma擅长处理多媒体内容,Milvus 提供通用的数据处理能力且特别适合于推荐系统和语言/视觉分析,Faiss 强调其 GPU 加速在搜索上的优势,而 Weaviate 则以其在企业级数据管理中的应用为特色。
4、支持语言

可以看到chroma基本是原始python的内置库了,对于跨语言调用这方面还是支持的不够。
5、GitHub Stars
虽然不是那么重要但是它可以侧面反映出项目的受欢迎程度,Stars越多,意味着大家关注的程度就越高,这样如果有问题的话被解决的几率也会更大。

总结
Chroma在易用性上占优,特别适合在Jupyter Notebook上进行开发、测试和生产,是处理多媒体数据,尤其是音频和视频搜索的理想选择。
Milvus强调在存储效率和数据查询性能上的平衡,支持内存和持久存储,适用于各种数据类型和格式。它在电子商务、自然语言处理以及图像和视频分析等多个方面有广泛应用,特别是在数据分区、负载均衡和容错方面提供了强大的支持。
Faiss可以进行GPU加速的高速检索,特别擅长处理庞大数据集的快速最近邻搜索,适用于不同技术需求和数据环境,能够与多种技术风格相协调。
Weaviate则提供了GraphQL-based API,强调与知识图的灵活高效交互。支持实时数据更新,确保数据的时效性,以及通过模式推断功能,自动化了数据结构定义的过程,适合于需要数据分类和企业资源规划的场合。
它们都能提供高效的搜索能力和处理大规模数据集的能力,但在细节实现和特定功能上各有侧重,这需要根据实际业务需求来决定最合适的选择。选择使用哪个库将取决于数据的类型、处理需求和预期的使用场景。

