企业数据库工作1:数据库选型,除了TPS、QPS还要关注什么?
春节和老友相聚,曾经一起奋斗的兄弟们现在已是首席架构师、资深总监甚至是CIO、CTO了,而我终日不学无术,只能继续在数据库一线搬砖,实在是惭愧。酒过三巡后,大佬们开始凡尔赛,诉说着身为中层高层的困难,其中一点是如何把企业的数据库伺候好。这咱可以好好唠唠,于是有了下面这幅图。
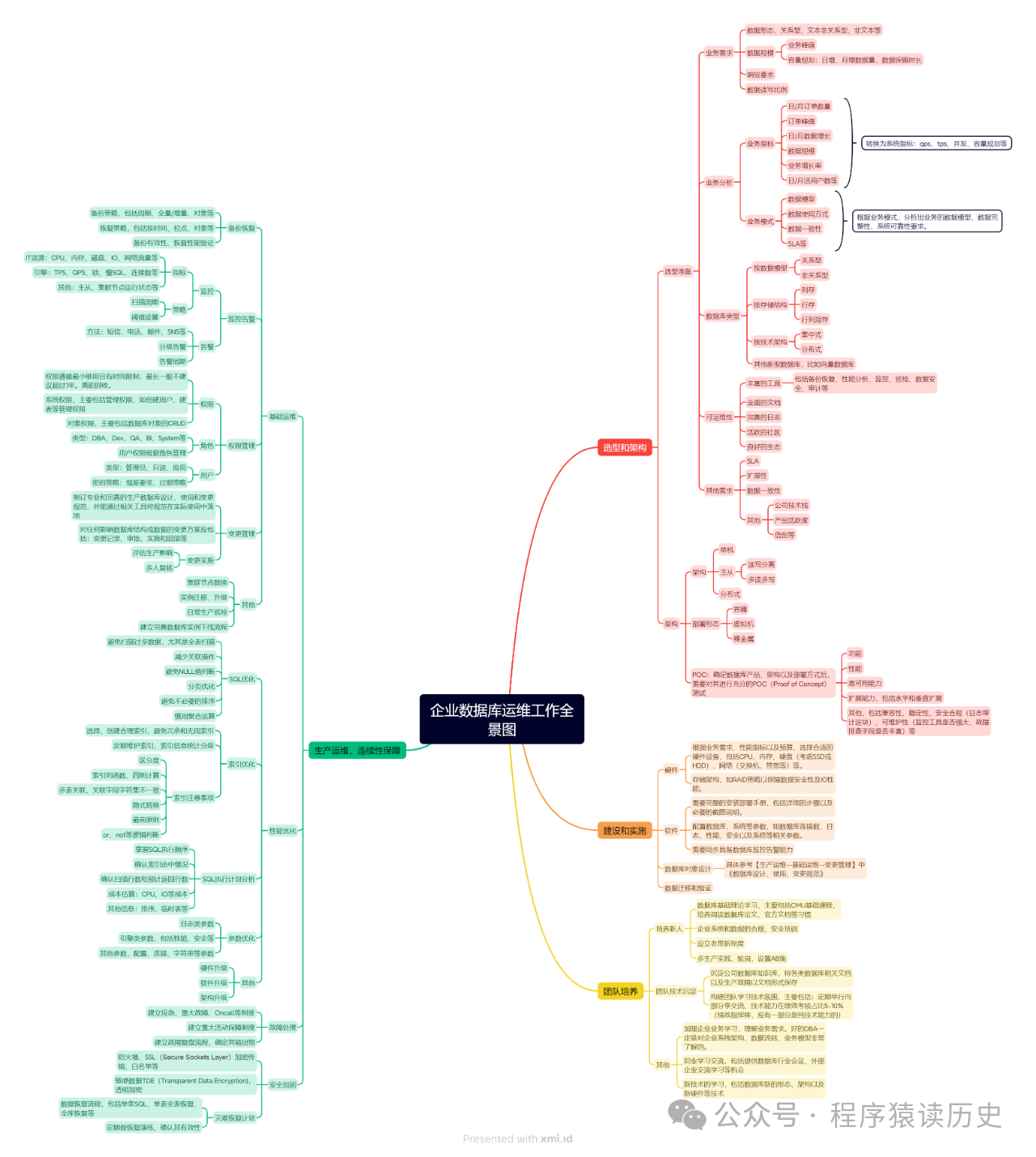
我认为企业数据库工作可以分为数据库选型、架构设计、建设实施、生产运维(连续性保障)、团队培养等五个主要方面。我将准备一个系列,尝试着说清楚这五个方面,本文是系列第一篇,从业务、数据库特性和可运维性等角度聊聊数据库选型那些事。由于小弟能力有限,写的不妥之处,可能我也很难改 ^_^
01 业务分析
企业发展初期,业务规模小、并发低,以目前数据库和硬件的能力,可以任性的选择数据库。经过发展几年后,企业业务往往会变得规模大,并发、系统服务等级和复杂度高。此时,数据库选型变的重要和专业工作。
数据库是服务业务的,在选型前要分析业务这几乎是共识,但该如何分析业务呢?我认为,业务分析包括业务目标和业务数据模型的分析,而绝大多数架构师只做业务目标分析。
业务目标
业务目标是指业务明确的系统日/月的订单数量、用户数、业务峰值、业务增长率等指标。通常架构师们会根据应用系统的实现方式,将业务目标换为系统指标,比如TPS、QPS、吞吐量、最大并发、数据存储规模等,从而计算出系统所需硬件的规模和数据库架构,以及是否需要读写分离、分布式数据库。
数据模型
数据模型是指描述和组织系统运行中产生的数据的抽象模型,它定义了数据的结构、操作和约束条件。
数据结构描述了数据之间如何组织和存储的关系。早期的数据模型有层次、网状等,上世纪70年初出现的关系型模型至今长盛不衰,互联网出现后,诞生了文档、键值、列簇、图、时序等模型。再多说一句,关系型数据库通过关系模型、表来组织数据,表中的行表示记录,列表示属性;数据操作是通过特定的方式来操纵数据,比如关系型数据库通过SQL对数据做CRUD;数据约束条件是确保数据的准确性和一致性。
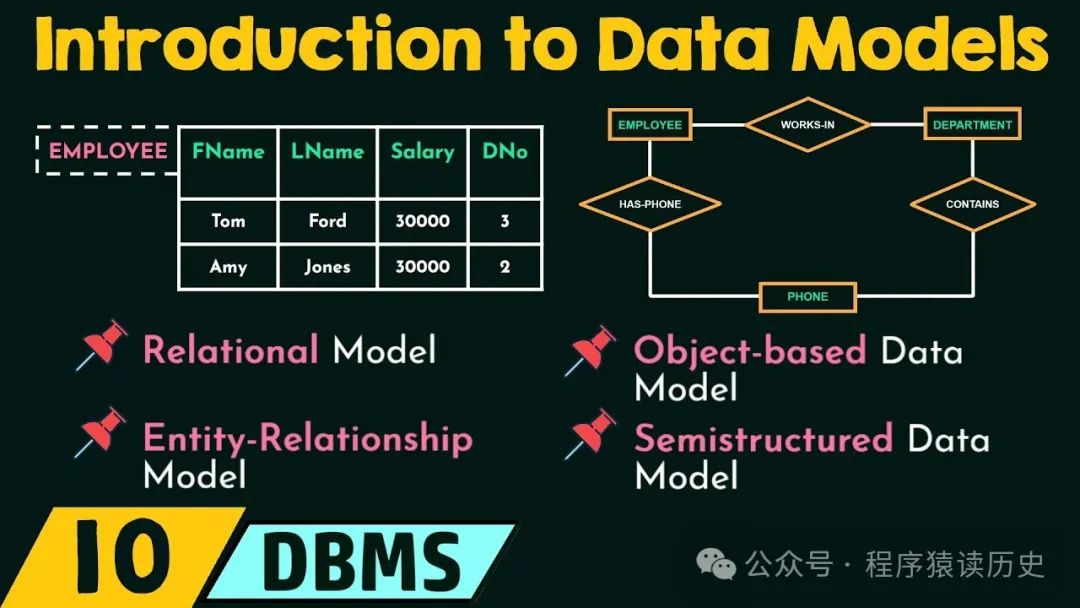
图片来自Neso Academy
通过业务的数据模型分析,可以了解数据的来源、类型、关系以及业务规则,从而确保所选数据库能够准确、高效地存储和管理这些数据。另外,不同的数据模型对数据库的读写性能、并发处理能力、扩展能力以及数据一致性保障等方面都有着不同的要求。
02 数据库特点分析
完成业务分析的“知己”后,架构师们还需要了解市场上纷繁复杂的数据库及其特性,做到“知己知彼"。那么现在市场上有多少数据库呢?根据墨天轮分析,国内目前至少有288个数据库产品。国数据库权威机构DB-Engine报告,全球则有400多个数据库产品,如此多的数据库也确实难为甲方“爸爸们”去选型。
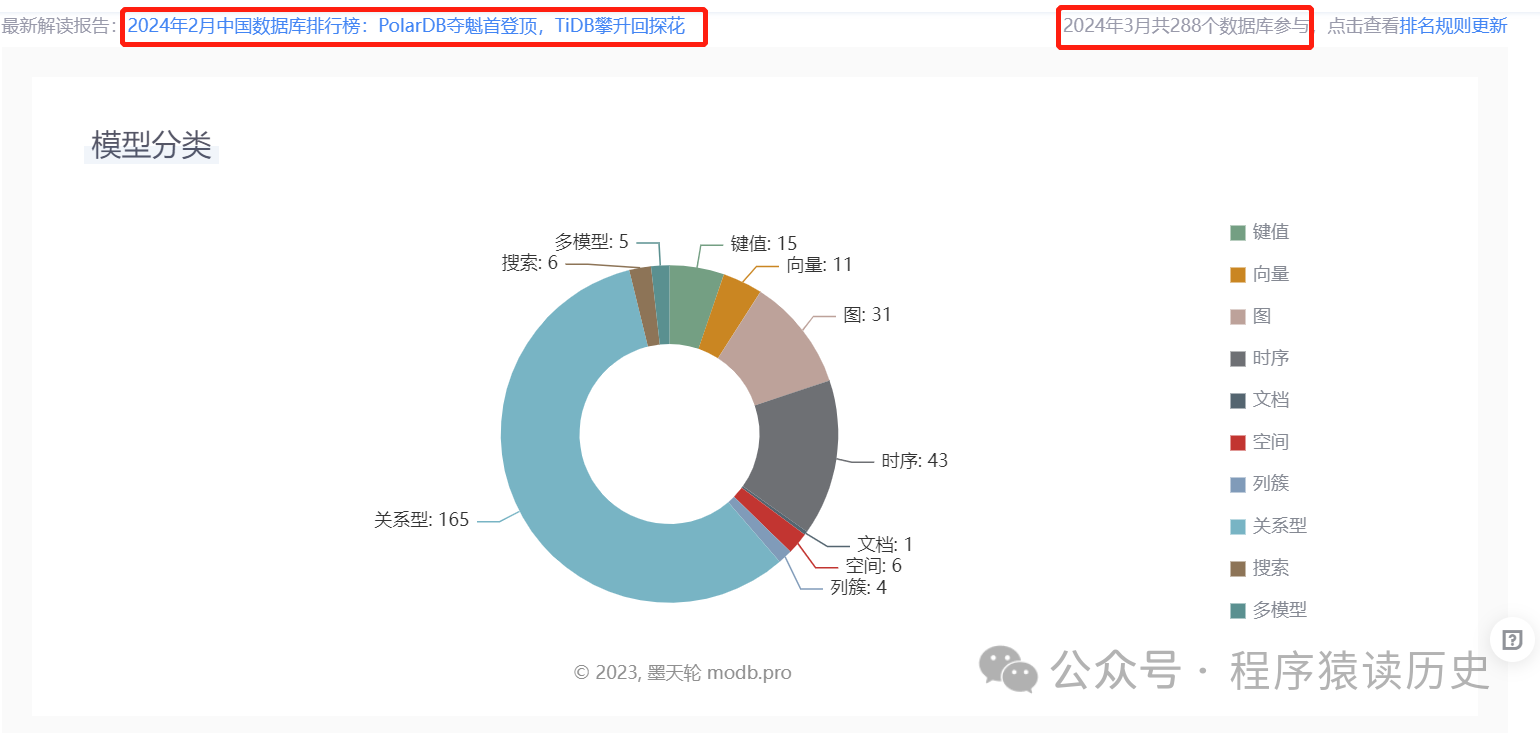
图片来自墨天轮官网
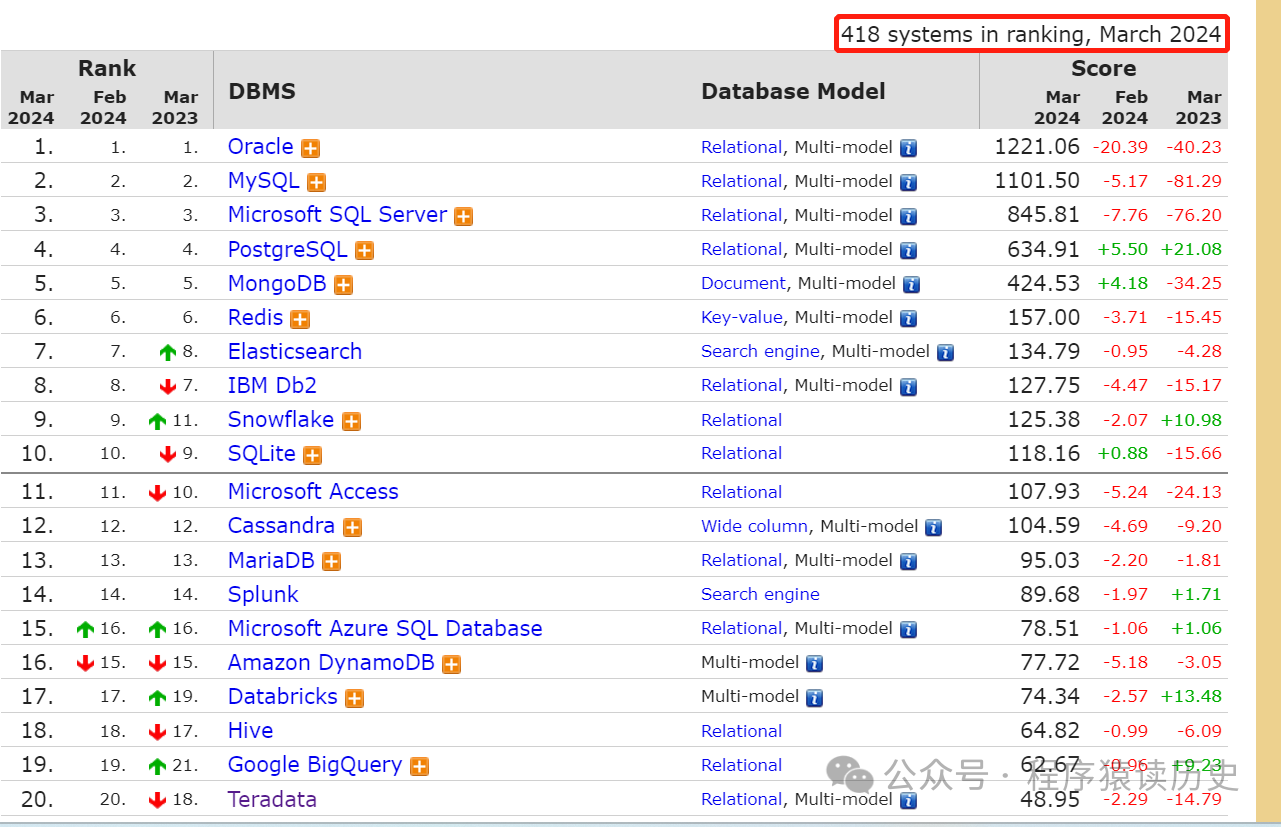
图片来自DB-Engines
数据库按数据模型、存储结构、技术架构等维度,可以分为关系型、非关系型、行存、列存、行列混存、分布式等类型。
数据模型
传统的关系型数据库是基于关系模型,使用表格来组织数据,每个表包含行(记录)和列(属性),适合存储结构化数据,通过SQL进行高效读写操作;非关系型数据库采用不同的数据模型,常见的有键值、文档、图形、时序存储等模型来组织数据(时序数据库和数据库的时序能力、JSON文档数据库和数据库JSON类型是两回事情),这类数据通常不支持标准SQL、关联查询较弱,但在读写性能、扩展性上有更好的表现。
存储结构
行式数据库(Row-Based)数据按行存储,常见的关系型数据库大多为行存;列数据库(Column-Based)数据存储方式按列存储,列存数据库有Hbase、Clickhouse、Doris 等。
在行存模式下,数据按行连续存储,所有列的数据都存储在一个block(page)中,不参与计算的列在IO时也要全部读出,读取操作被严重放大。而列存模式下,只需要读取参与计算的列即可,极大的减低了IO 开销,加速了查询。
同一列数据属于同一类型,相同类型的数据会有更高的压缩比。因此,列存往往有着高达十倍甚至更高的压缩比,节省了大量的存储空间,降低了存储成本。更高的压缩比意味着单位 block(page) 可以存储更多的数据,一次IO可以从磁盘中读取更多数据,从而提高查询效率。同时单位内存中可以存放更多的数据,系统 cache 效果更好。
下面是 ClickHouse 文档提供的行存、列存在分析统计时的效果动画,从中可见,列存数据库在分析统计时有明显的性能提升。
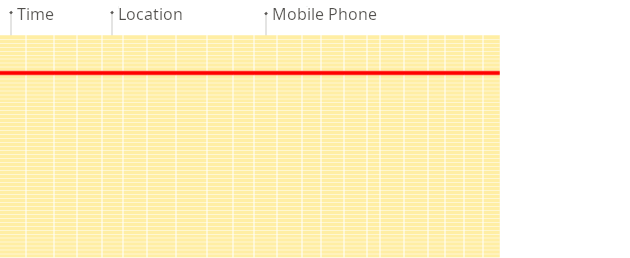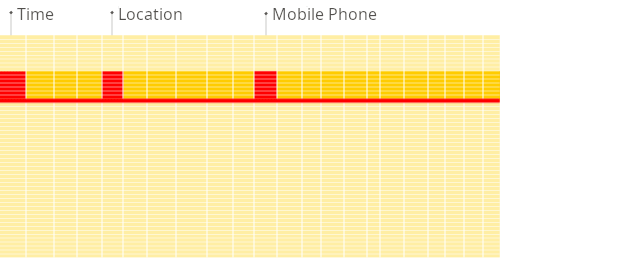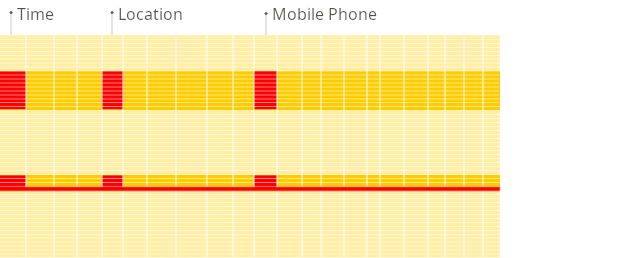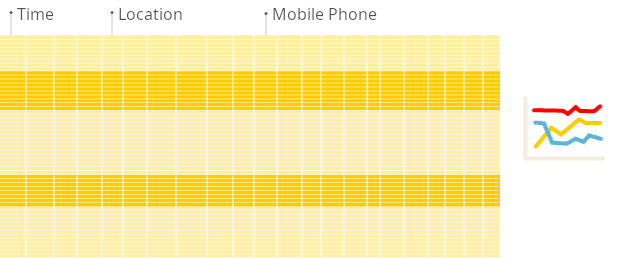
行存

列存
列存技术也不是数据库银弹技术,虽然在统计分析查询、压缩比上有显著优势,但是在单条数据写入以及数据写入完整性上有较大挑战。当需要更新或插入单个记录的某个字段时,可能需要读取整个列的数据并重新写入,这会导致写入效率不如行存储数据库。列存模式下中,一行数据的不同字段可能存储在磁盘的不同位置,这可能导致在执行涉及多个字段的操作时出现数据一致性问题。
技术架构
根据架构形态,数据库又可以分为集中式、分布式,常见的关系型数据库 多为集中式架构;分布式数据库并没有一个严格官方的定义,通常将物理上分散存储在多个地点、逻辑上作为一个整体的数据库系统称为分布式数据库,国内比较著名的分布式数据库产品有 TIDB、OceanBase、GaussDB、PolarDB-X 等。
分布式数据库以高性能、可靠性、扩展性著称,这几年被很多人称为“银弹数据库”,大有企业不上分布式数据库无法显示逼格,还有一部分是真的不了解分布式数据库的坑,比如运维、多维数据使用、高并发写入等场景。
阿里云曾对分布式数据库写入性能做过一个测试,它的结论是:分布式数据库实现的全局索引中,即使只有1个索引,写入性能也都会下跌到30%以下,在8个索引的情况下,性能基本都会跌倒10%以下。而像MySQL这种单机数据库,8个索引的情况下,性能依然保持在85%以上。详见 分布式数据库二级索引写入性能测试
其他
随着chatGPT的火爆,向量数据库走进了大众视野,实际上它在图片、音频、视频等多媒体文件搜索以及推荐类系统中早已有成熟运用。向量数据库是用于存储、索引和检索矢量数据的数据库系统,它的数据模型是围绕向量存储和相似性搜索展开。在计算机科学中,“矢量”指的是一个多维数组,其中每个元素代表了数据的一个特征或属性值。

经过业务、数据库分析后,大部分企业的数据库选型也就完成了。从满足业务需求来看,做到这两点也确实够了,但如果要加上“业务系统连续性”要求,那么数据库的可运维性是数据库选型中必不可少的一项。

图片来自网络
上面这个文章标题是国内著名DBA社区——dbaplus,对数据库可运维性的态度。
03 可运维性
试想下如果数据库每次异常,企业只能依靠厂家或者社区来解决所有问题,那这样的产品即使性能再强大、功能特别丰富,也难以服务好业务。
业务方要求系统尽快上线,他们和程序猿KPI不同,评估方式不同,对数据库的要求自然也不同。如果前面的选型要求是为了满足业务需要,那么可运维性往大的说是为了系统稳定性和容灾能力,往小的说和程序猿的起夜率、节假日的幸福度密切相关。
图片来自网络
我认为的数据库可运维性应该包括这几个方面:丰富的工具、全面的文档、完善的日志、活跃的社区、良好的生态等。
丰富的工具
丰富的工具是提升数据库可运维性的关键,包括备份恢复、性能分析、监控、巡检、数据安全、审计等,这些工具能够帮助DBA面对数据库异常时,快速解决问题,恢复系统运行,避免整个IT团队大眼瞪小眼的等着厂家来处理的尴尬。
全面的文档
好的数据库文档不仅详细介绍数据库的结构、原理和功能等,还有丰富的数据字典,记录了数据库元数据、运行和负载等信息,帮助DBA和开发人员快速理解和掌握数据库,从而能更好使用和运维数据库。
完善的日志
完善的日志系统、标准的错误码也是提高数据库可运维性的重要手段。日志记录了数据库的运行状态和操作历史,标准的错误码是数据库产品能力体现。当数据库出现问题时,可以通过查看错误日志、错误码来快速定位问题原因,从而缩短系统的恢复时间。
活跃的社区
数据库社区不仅为数据库提供丰富的技术支持和经验分享,还能通过用户使用过程中的问题反馈、讨论、解决中推动产品发展,从用户实际使用中,提升产品能力。另外,活跃的社区有助于提高数据库的知名度和影响力,让更多人了解、使用产品。
良好的生态
良好的数据库生态也是选型的关键因素,这不仅仅在遇到问题时,快速在网上找到类似答案,同时也降低人才招聘、上手成本、兼容性的隐形成本。如果选择了一种数据库市场对应的人才很少,那么一旦出现人员流动,数据库就处于无人维护的情况,这对于公司来说是绝对不允许发生的事情。
04 总结
写到这,数据库的选型工作也基本结束,它主要包括业务和数据库特点分析以及可运维性的考虑,架构师容易忽略业务中的数据模型和数据要求的分析,和可运维性的考虑。前者涉及到系统的性能、扩展性以及数据的一致性和完整性;后者小到和程序猿的幸福感相关,大到和系统的稳定性、快速恢复能力相关。
另外,这几年因为众所周知的原因,数据库选型时还要考虑信创、商业采购成本等问题,以及在使用开源数据库时的开源协议等问题。关于开源协议这块,网络上大家讨论较多,似乎能说清楚的不多,后面有机会可以再细聊。
作者介绍
司马辽太杰,目前就职于一家国有企业,主要负责数据库连续性保障、性能优化、架构选型和设计。10余年数据库架构和管理经验,专注于数据库运维、架构和行业发展,擅长 MySQL、MongoDB、Clickhouse、Oracle、Greenplum 等数据库。业余热爱历史,偶尔读点闲书,欢迎关注个人公众号“程序猿读历史”。

