DBdoctor,致力于解决数据库的一切性能问题
本文 5542 字,读完大约需要 8 分钟(文末有惊喜 License!)
17(一起),这是我的幸运数字,恰巧今年 8 月 17 日在 DTCC 大会上我们全网首次发布 DBdoctor 数据库性能诊断软件(简称 DBdoctor),这个月同样是17日,在全网首发整四个月后我们发布重磅大版本 V3.1 。值此重大更新之际,想与各有识之士深度聊一下这款产品,以及它背后的故事。
自 DTCC 大会首发以来,DBdoctor 受到了业内同仁的广泛关注,有 200 多家用户把我们产品应用到了生产环境,同时我们跟 20 多家行业公司包含 Oracle、阿里、腾讯、京东、中兴、移动、浪潮、沃趣、爱可生等进行了深度交流,结合大家的建议,紧锣密鼓地迭代了五个版本,从功能和体验上都有了大的跃迁,今天我们发布 V3.1 版本,基本达到了“一分钟定位问题 SQL ”的第一阶段目标。

DBdoctor:IT168 年度最 佳创新产品奖

DBdoctor 是一款内核级数据库性能诊断软件,致力于解决数据库的一切性能问题。是的,我们只聚焦在数据库性能这个极细又专的领域,国内并不缺少数据库的平台级产品,但是把性能这个最痛的点真正解决的并没有,单独做数据库性能相关的就更少之又少了,最终我们选择为行业打通这最艰难的一公里。
性能问题的表现非常数字化,通过基础监控便能很清晰的体现,但是偏偏解决起来不易量化,强依赖故障处理经验,所以业界产品往往围绕经验沉淀做解法,但是仍然没有彻底解决性能困扰。DBdoctor 从一开始便摒弃了传统的经验法,开辟出一条独有的数学量化方法,我们内部把 DBdoctor 比喻为数据库的 CT 机,通过 CT 扫描获得真正的性能问题,而不是强依赖经验的号脉方法。DBdoctor 可以快速诊断性能问题,就像 CT 机可以准确定位病因,不仅如此,还可以提前发现性能隐患,就像每年体检通过 CT 防患于未然一个道理,不同的是 DBdoctor 会实时不间断的守护着您的数据库。

基于此,我们期望可以帮助更多的 DBA 和研发工程师。助力 DBA 更快的解决与规避问题,彻底从 oncall 中释放出来,做架构改善等更有意义的事情;赋能不太熟悉数据库的研发人员具备排查数据库性能问题的能力,帮助没有专业 DBA 的企业不再受数据库性能问题困扰。

上图是我们的 logo,一只可爱的啄木鸟,有着鸟类医生的美名,长着锐利的长喙,身体是由数据库的缩写 DB 组成,寓意着像啄木鸟医生一样实时守护着您的数据库,消灭一切虫子(bug)。

聚好看作为海信旗下的互联网科技公司,服务着海信全球亿级互联网电视用户,像春晚、奥运、大阅兵等大家集中看电视的日子都是我们的流量洪峰;同时我们还作为海信集团的云设施提供方,管理了上万套数据库实例。
当家电进入智能与 IOT 时代,数据库的重要性不言而喻。2020年,我从阿里云RDS团队回到美丽的青岛并加入聚好看,承担了数据库去 O 和云化工作,历经一年成功搭建了我们的数据库私有云平台,并完成去 O 和上云工作。去 O 后一直困扰于性能问题,之前 Oracle 和硬件掩盖了很多问题。于是我们决定编写工具解决这些问题,团队有同学对 eBPF 研究的非常深入,一开始就使用了 eBPF,21年实现了初版 V1.0,并在聚好看生产环境落地。
2022 年阿里好友郑老师加入团队,作为研发负责人对 DBdoctor 进行了全方位加强,此时不仅是集团内部,上下游多个合作企业主动提出使用 DBdoctor,并给予较高的评价,这是 V2.0 。
23年初基于集团内部和合作方的诉求,我们对行业和数据库用户做了进一步调研,发现性能问题一直排在 MySQL 十大痛点之首,业界也少有致力于解决数据库性能问题的产品,于是将 DBdoctor 商业化,最终有了 DTCC 大会上首发的 V3.0 版本,历经五个小版本后,今天发布了 DBdoctorV3.1。
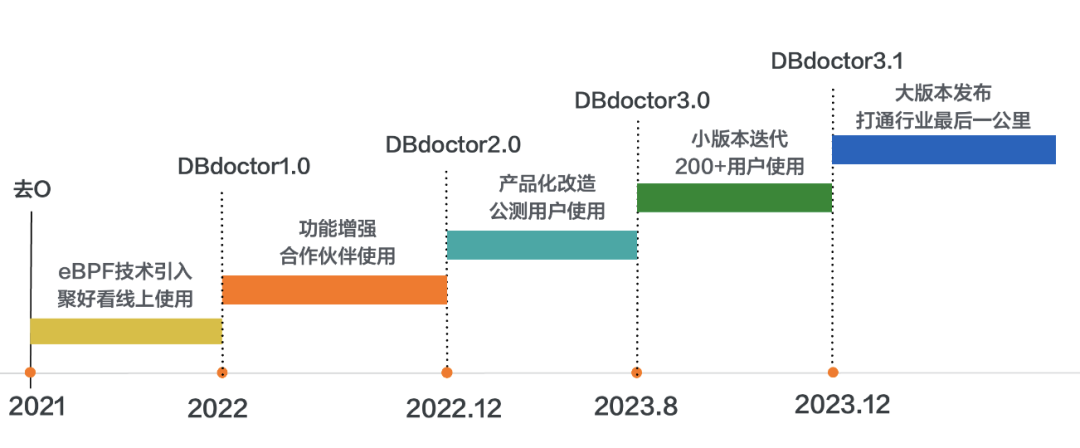
DBdoctor缘起

性能问题面临的挑战
数据库发展到今天,基于 Prometheus 和 Grafana 很容易就搭建一套数据库监控系统,从主机、容器到实例,监控指标上百个,同时也会采集慢日志、错误日志、审计日志等定位问题。但性能问题仍然是最大的痛点,关键现象有三:
① 事出即紧急:在大促等流量激增的关键时刻,数据库一出问题就会影响到数以千万计的用户和收入,一次故障甚至会导致一家小微企业的破产,成为悬在相关者头顶的达摩克利斯之剑。
② 事中难处理:平时没有慢 SQL,一出问题则满屏慢 SQL,有的 SQL 平时不慢突然会变慢,监控指标和日志浮于表面,难以定位根因,强依赖有大量经验的资深 DBA。
③ 人才难培养:资深 DBA 难招,且故障处理经验难以传承;另外数据库技术门槛高,仅数据库锁就有十几种分类,再加上现在数据库引擎多元化,资深 DBA 也难面面俱到,更何况那些没有专职 DBA 全靠研发工程师的公司了。
所以过去在阿里云时,往往要轮流 oncall,整日忙于救火,半夜被电话告警叫醒那是常态。甚至出现性能问题后还会有业务方和 DBA 推诿扯皮的现象,故障定责、问题复盘,苦不堪言。

性能问题面临的挑战
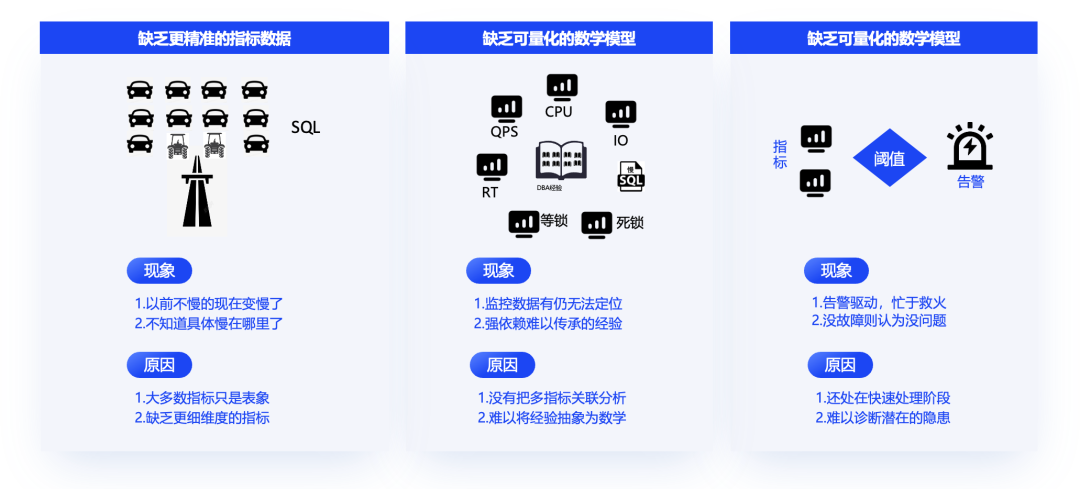
上述现象根本原因
① 缺乏更精准的指标数据。基于数据库内核吐出的慢日志进一步加工成执行耗时 top 或者出现频次等分析浮于表象,如慢日志的判定只基于执行时间,超过时间参数阈值的都是慢日志,难以区分哪些 SQL 是真正的执行耗时长,哪些是被其他 SQL 阻塞,这就是为什么经常会出现之前不慢,出现故障就都变慢了的原因。就如同下图中的轿车和拖拉机过桥的例子,因为拖拉机阻塞了汽车过桥,从表象数据上看汽车的速度也很慢,但真正原因是拖拉机速度慢或者桥太窄。
② 缺乏可量化的数据模型。过去靠经验沉淀,遇到问题,先看是否熟识,熟识的可以快速定位,新引入的则需要进行一系列的复现验证,能解决的就进入经验库,不能解决的就成为疑难杂症,想措施去规避。但经验积累的速度往往跟不上业务发展,于是成熟业务的经验难复用到新业务,MySQL 上生效的经验也不一定在 PostgreSQL 上生效。经验归根结底是规则,业界普遍在想方设法来丰富规则库,但多引擎并存的时代,构建通用规则库真的太难了。
③ 缺乏提前发现问题的措施。传统性能问题的发现基于告警驱动,缺少主动发现的措施,通过设置指标阈值,当监控指标超出阈值后发出告警。一旦数据库实例达到一定规模后容易出现放松与收紧的两个极端循环中,不出问题时进行告警治理,调高阈值减少告警量,出现问题后会立马调低阈值提升灵敏度,治标不治本。
DBdoctor 从 1.0 版本开始就摒弃了日志采集和经验规则方法,坚信通过数学方法解决数学问题。eBPF 是我们的主要工具,通过 eBPF 观测 SQL 在数据库内核中的执行路径,并采集各环节的重要消耗是 DBdoctor1.0 版本突破的技术点。基于这些重要数据进行大数据聚合、分析、处理并与 CPU、IO、MEM 等基础资源关联映射是 DBdoctor2.0 主要攻克的难题。通过图形相关性分析和异常图像识别的数学模型来识别根因和问题隐患是 3.0 的主要创新。下面我会逐一详细介绍这三部分优势,可能会偏技术一点,但绝对新颖。

DBdoctor:整体架构
优势一:使用更精准的指标数据做分析
DBdoctor 基于 eBPF 技术采集到了一条 SQL 语句在执行堆栈上的详细资源消耗,包含了 CPU、IO、网络、锁等消耗数据,针对这些消耗数据按照时间维度绘制出了具体消耗的分布图,并赋予不同的颜色,并把一系列图形放在同一坐标系下,通过压缩与切割最终产出详细的量化分析。
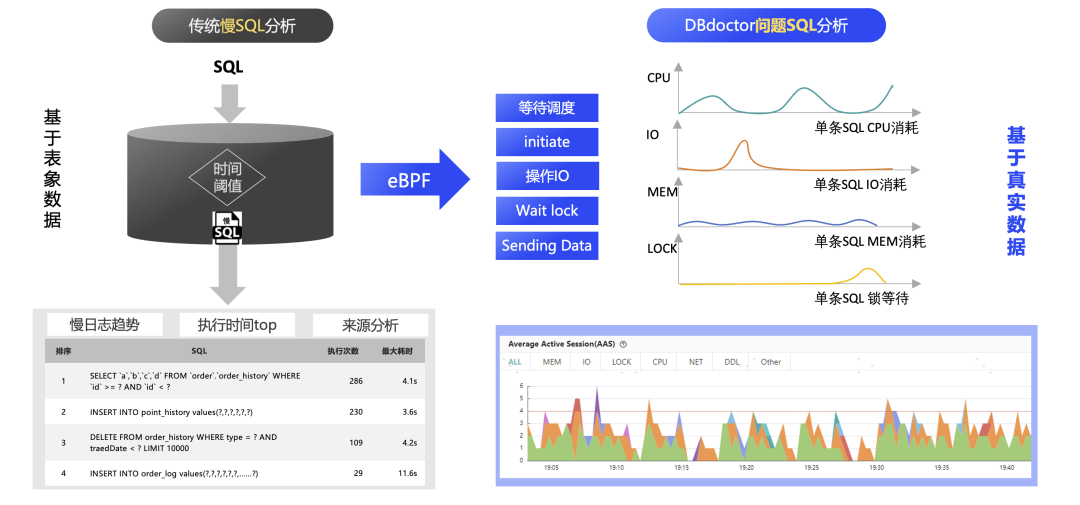
使用更精准的指标数据做分析
所以无需联动与推敲多而杂的指标项,只需聚焦关键资源,拖拉拽的方式便能查看到具体的诊断详情,使用颜色区分 SQL 在内核中的不同执行阶段,把资源消耗情况映射为颜色面积,由面积和相关性算法(后面会详讲)进行计算筛选从而得到主要的资源瓶颈,支持 IO、锁和 CPU 等不同资源维度切换,查看对应的资源消耗情况。

三步精准发现问题 SQL
同时采集包含详细锁数据的细粒度数据,在大数据处理阶段将此串联,形成下面的锁泳道图。并将锁问题划分为锁等待、死锁、长事务、未提交四个事件,这样我们就能按照每个事件的特征产出事件画像,比如锁等待要有等,死锁要有环。锁事件->具体的锁->锁分别所在的 SQL->SQL 分别所在的事务->事务中包含的 SQL->SQL 中又包含的锁,每个锁是什么类型,影响的行数,是持有还是等待及其 page 和 heap 信息。更甚者我们目前正在突破锁的具体数据,详情敬请期待。
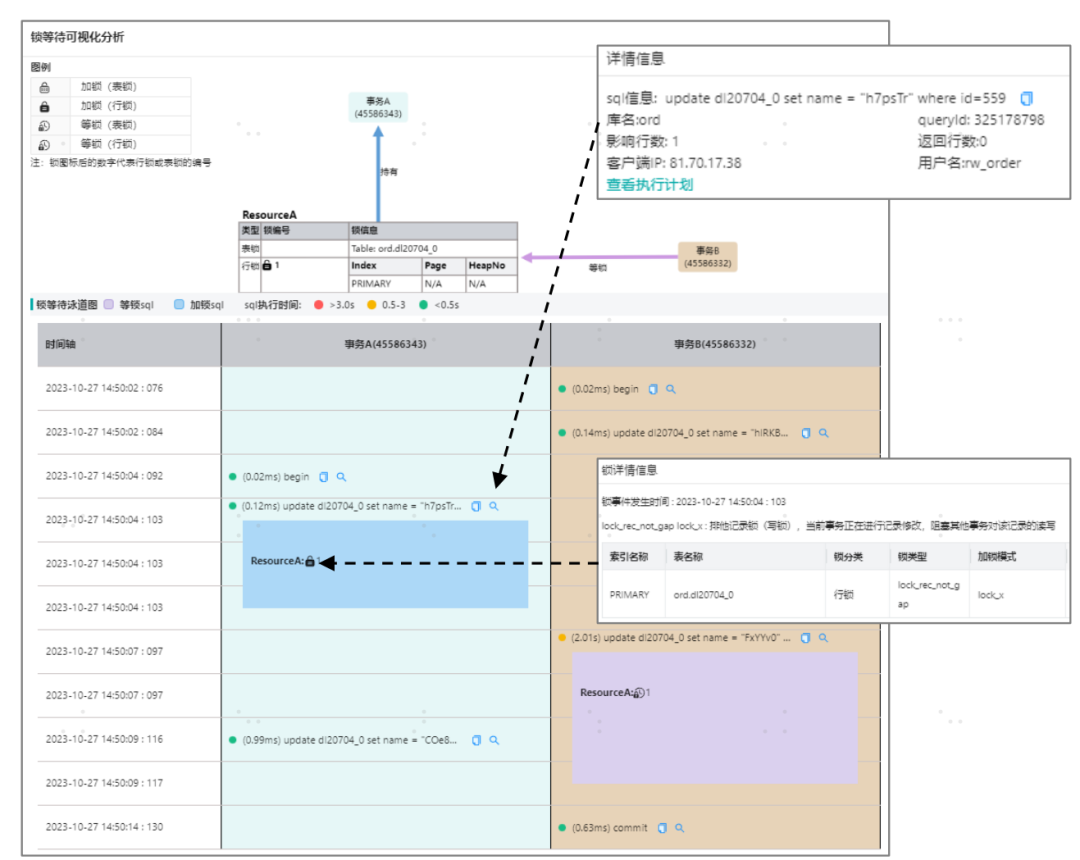
锁等待可视化分析
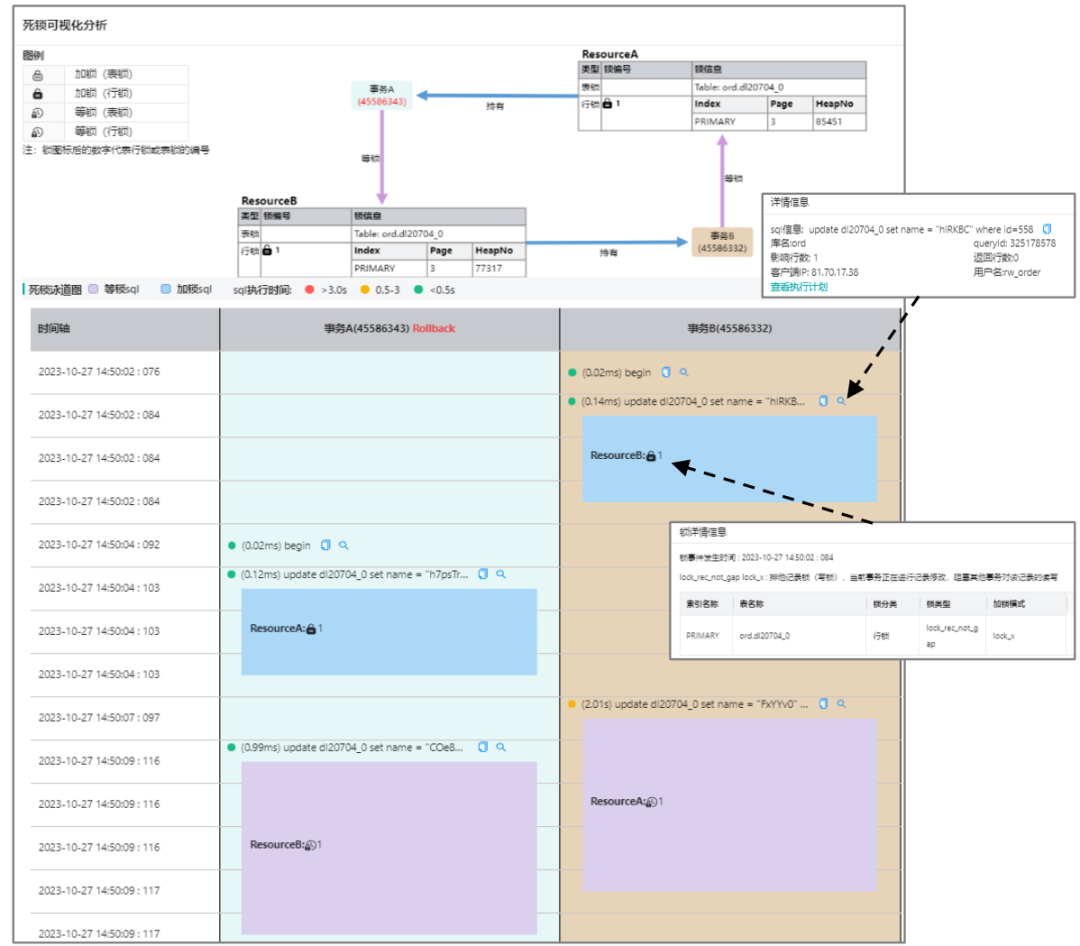
死锁可视化分析
优势二:使用可量化的数学模型做分析
DBdoctor 通过采集到的细粒度指标数据,先进行 SQL 模糊处理,按照模糊后的 SQL 进行了数据聚合,并将聚合后的 SQL 再次拉齐到同一时序图,把每条模糊 SQL 的资源消耗和整个实例的资源消耗进行相关性算法分析,这里可以简单理解为比较两个图形的相似性,并给出模糊 SQL 的相关性得分,由相关性得分再次进行重排序,从而得出关联 SQL 的最终排序。所以在 DBdoctor SQL关联分析列表中的 SQL 都是通过数学模型精准计算得来。

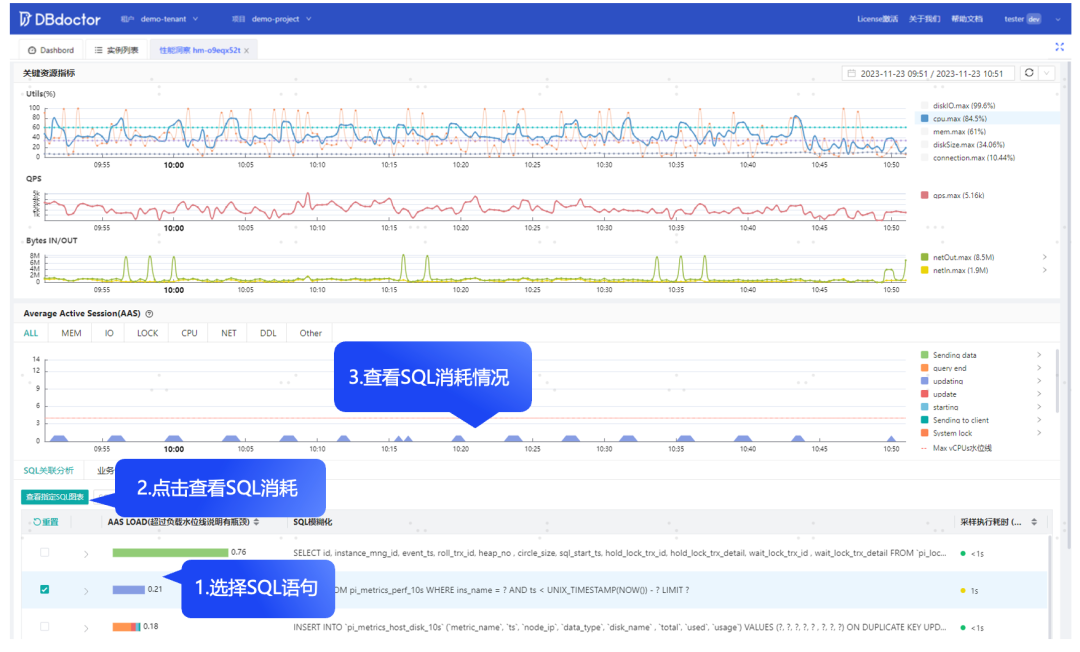

给出优化建议
优势三:主动发现潜在问题避免故障发生
在上述两点基础上,我们又提出了基于图形识别的问题发现算法,可以理解为寻找图形的突变,根据不同的突变幅度进行等级分类,目前主要分为了异常和隐患两个等级,如下图黄色方块和红色方块。同时不止于主动找出事件,还去定位引起此事件的根因,特别是同一区域内出现多个事件的场景。这里我们主要实现了一套根因修正算法,会根据SQL是否新增、性能是否恶化,是否跟其他 SQL 有关联性,是否已是源头了等修正方法进行加权修正,最终得出根因 SQL。
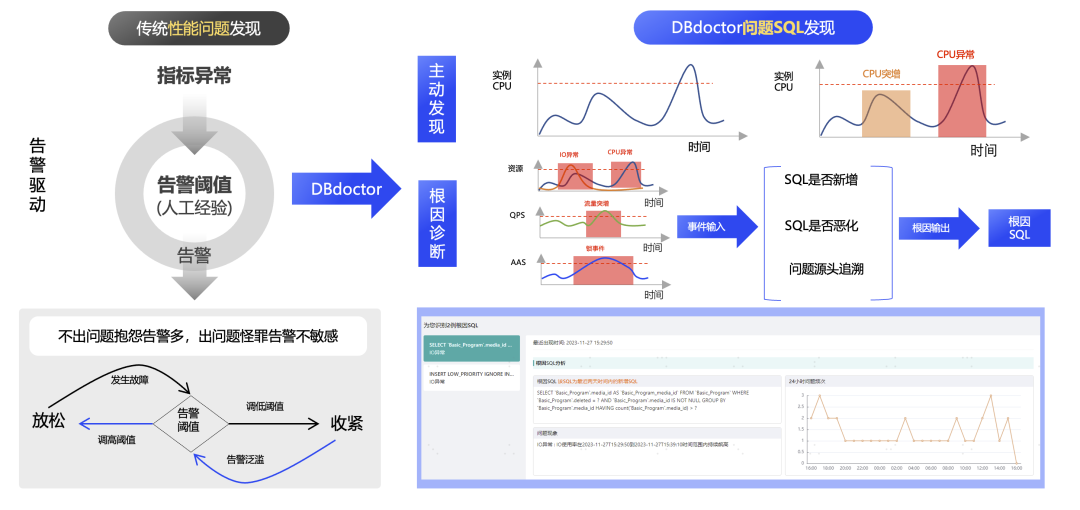
如下图所示,异常和隐患区间中可以区分资源异常( CPU、IO等)、流量异常(QPS)、各类锁异常等,并且给出引起此次异常或隐患的根因 SQL。除此之外,DBdoctor 也会近乎实时地融合各个异常进行联动分析和加权修正,得出整个实例维度的异常根因,并针对根因给出问题现象和详细分析,后续会给出进一步的优化建议,从而提供一份完整的根因诊断报告。
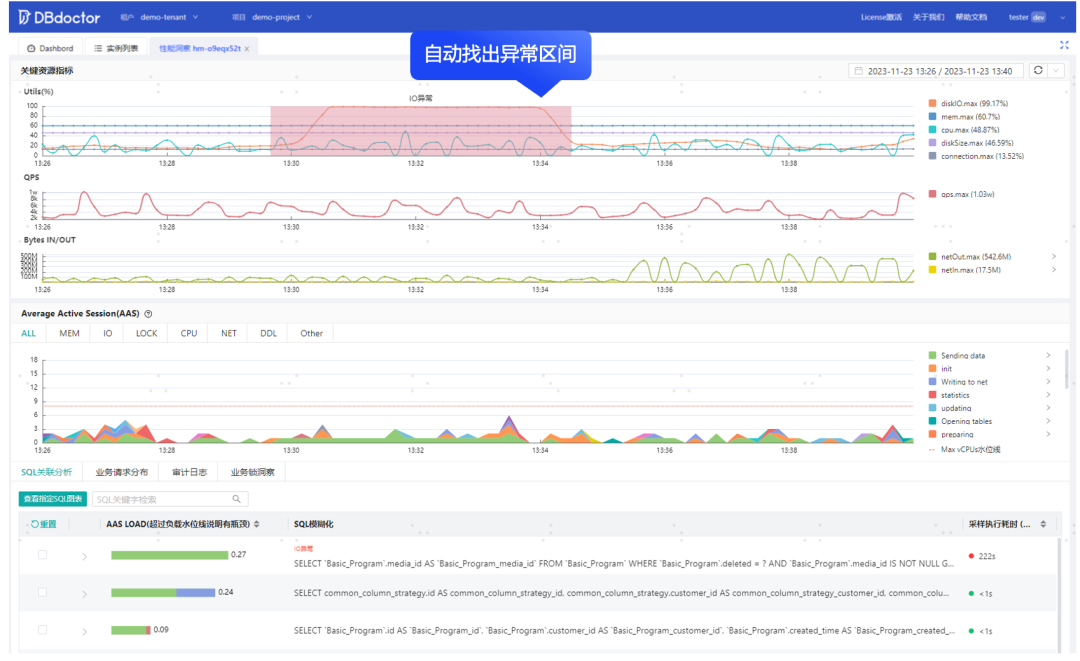
自动找出异常区间
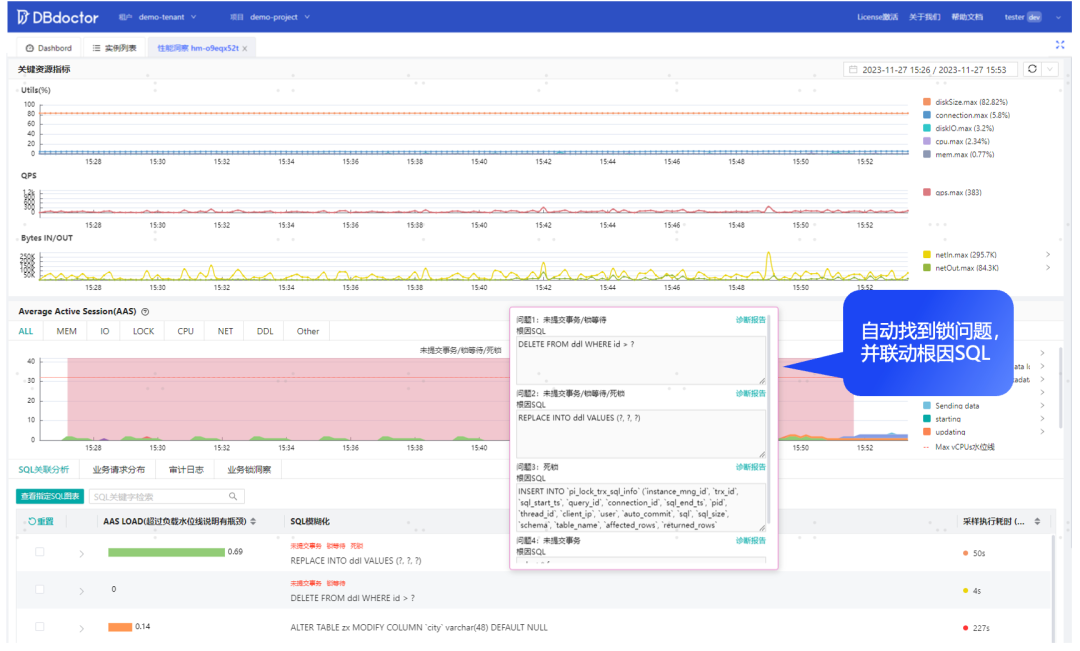
自动发现锁问题并找到根因
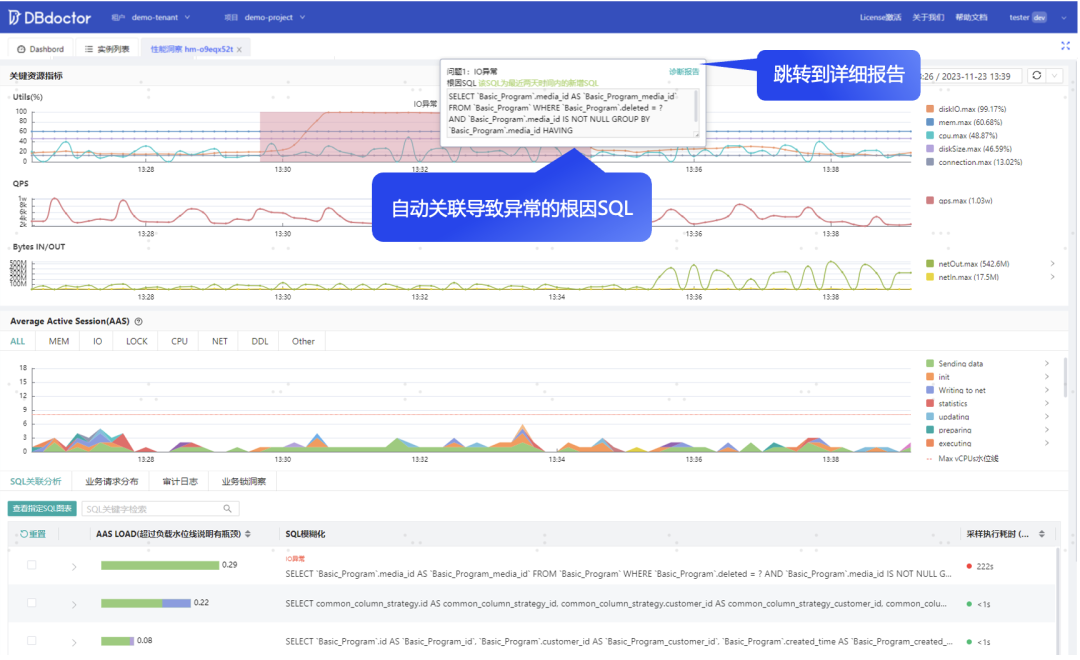
自动分析推导出根因SQL
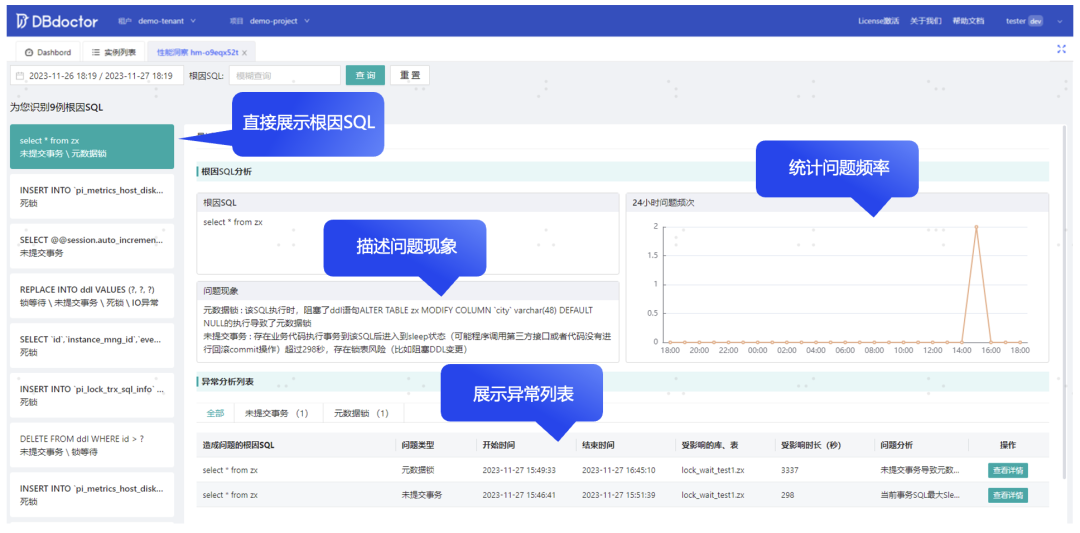
下图根因诊断页面,以结果的视角直接给出造成问题的源头SQL,每条SQL会详细描述问题现象,统计问题出现的频次,以及此SQL造成的异常事件列表。
在云原生时代,DBdoctor同样支持实例的多租户管理,在租户视角提供可自行编辑的性能大盘,按照根因问题数和异常事件数两个维度查看所有实例的性能情况,可以直接点击问题实例下钻到根因诊断页面查看问题详情。
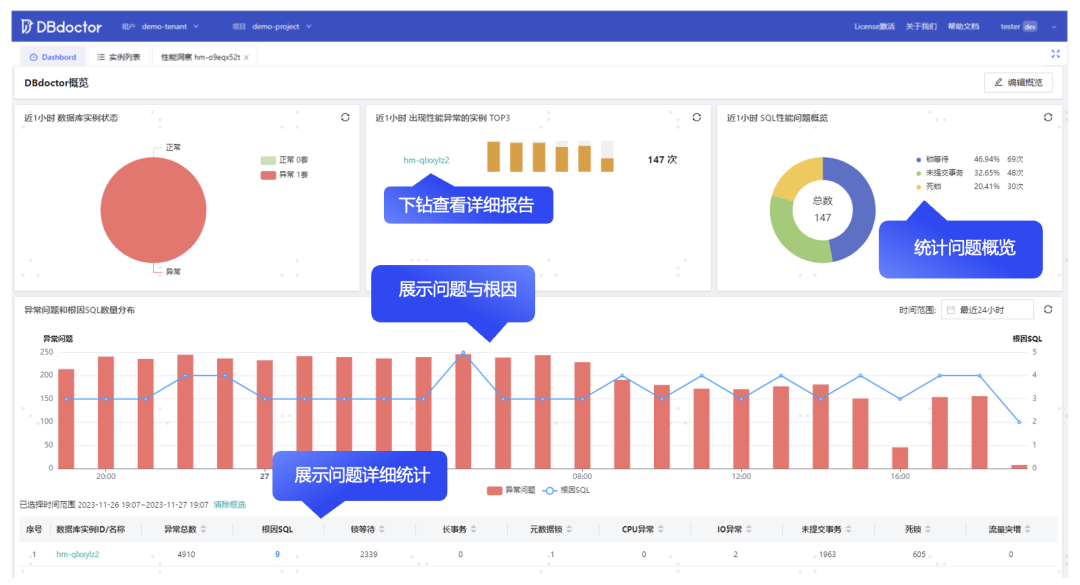
性能大盘

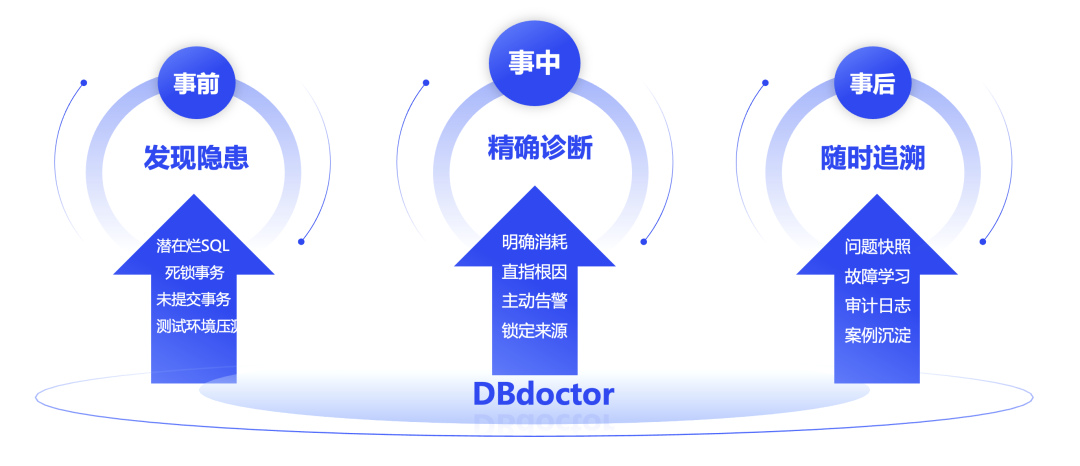
最后,我们聊一下应用场景:
1.主动发现隐患,提前规避故障。《黄帝内经》说,圣人不治已病治未病,不治已乱治未乱,于数据库亦然。接触过一个客户,公司数据库3年内并未发生过性能故障,但是使用 DBdoctor 接入的第一个实例时就发现了一个未提交事务导致的 DDL 锁问题,过去研发也反馈过偶尔做 DDL 变更会卡住,但就是不知道是哪条 SQL 堵住的,再后来接入了大部分实例,最终找出了 35 个潜在问题,这些问题虽然现在没有发生故障,但是说不定哪天就会爆雷。另外一些新开发的系统,或者数据库引擎替换的系统,在压测过程中就可以接入 DBdoctor,把问题尽可能在测试环境暴露出来。我们目前正在突破 SQL 性能评估功能,当对 SQL 性能把握不准时可以到 DBdoctor 上实时评估,感兴趣的小伙伴可以关注我们的后续版本。
2.降低性能诊断门槛,让开发人员也能诊断性能问题。DBdoctor 不再依赖专业经验,也无需推敲多而杂的监控指标,通过简单的颜色对比就能找到问题 SQL,主动框选问题区间,直指问题根因,给出解决建议,真正实现像 CT 机一样 24 小时守护着您的数据库。另外,我们的预研小组已经跑通 SQL 索引推荐的所有场景,通过 eBPF 采集到了 SQL 优化器的关键指标,可以基于线上数据构建索引树,从而精准推荐索引,此功能很快就能跟大家见面。
3.紧急救火,快速定位根因,减少业务损失。基于内核更细粒度的指标采集,通过大数据进行数学量化分析,快速精准诊断性能根因,主动发出携带根因 SQL 的异常事件,方便大家把事件接入邮件组、运维群。举个简单的例子,执行 online DDL 变更被阻塞,DDL 获取 MDL 锁会进一步阻塞此表的所有增删改查,严重影响到业务,如果没开启 MDL 相关的 instrument 想要拿到谁阻塞了 DDL 还挺棘手,除非是把 DDL 前的会话全部找到,出现这种场景大家为了救火第一想法是赶紧 kill DDL 语句,但是如果 DDL 是在 commit 前被阻塞了,kill DDL 就要回滚之前的操作,成本还是非常大的。使用 DBdoctor 出现此问题会直接告诉你谁是罪魁祸首,根因诊断会把阻塞 DDL 的语句放在异常事件中发出,您也可以在未提交或者长事务中找到此 SQL 的事务详情。这只是一个例子,我们并没有为这个例子做单独的处理,因为通过规则处理是永远处理不完的。
未来,解决数据库的一切性能问题,实现高度自治是DBdoctor的愿景。覆盖全方位的精准诊断是坚实的基础,完成决策建议是进阶,真正落地高度自治是我们的终极目标。

看到这里的一定是真爱,为了感谢大家的关注,我们准备了 20 个高阶版 license,在群中随机抽奖,可供您全功能免费使用一年。同时,只要进群,前 500 位用户都可获得全功能免费一个月的普通版 license。活动截止日期是 12月 30 日,抢先加小助手微信号入群,获得高阶 license 的概率会更高哦!
建议在PC端打开,为您提供下载和在线试用两个选项。(或者点击底部阅读原文进入)



关于聚好看
聚好看科技是海信集团旗下的互联网科技公司,以云计算、大数据与 AI 技术服务 B 端行业客户,连续六年获得“独角兽企业”称号。先后承担国 家级项目 10 项,相关科研成果“支撑千万级用户的智能设备云平台及其应用”“JuDB 云数据库 PaaS 平台”经鉴定达到国际领先水平。
聚好看研发团队的核心成员来自阿里、华为、腾讯、EMC 等国内外一线科技企业,在数据库、云计算领域有着深厚的技术沉淀和实践经验。我们致力于通过持续的技术和产品创新,打造业界领先的云数据库产品。
关于作者
张纪宽,数据库技术爱好者,一直专注于数据库产品研发。
海信聚好看云平台负责人,主要负责海信云原生容器平台 JuCloud、云数据库平台 JuDB 、融合集成平台 JuAPI、持续集成平台 JuCICD、多云容灾平台 Hybridge、数据库性能诊断平台 DBdoctor、数据库操作安全平台 DBArmor。从 0 到 1 搭建了海信数据库私有云平台,主导并落地了数据库去O与云化,DBdoctor 产品负责人。
曾任阿里云RDS PostgreSQL管控负责人,主导了RDS PostgreSQL存算分离落地,阿里集团数据库高可用负责人,多活容灾负责人,成功支撑阿里数据库存算分离和自研XDB替换落地。


