AutoGPT放弃使用向量数据库
AutoGPT 放弃使用向量数据库,对某些人来说,可能会有些出乎意料。因为从一开始,向量数据库就被认为可以帮助 AI 代理管理长期记忆。
是最初的想法发生了变化吗?到底发生了哪些变化?让我们从一些背景知识和 AutoGPT 的诞生说起。
#01
AutoGPT 的愿景
AutoGPT 在 3 月 30 日发布时,引发了 ChatGPT 热潮的巅峰。这是一个令人震撼的 AI 项目,激发了开发者对于像 ChatGPT 这样的 LLM 如何用于创建能够处理复杂任务的完全自主代理的想象力。
与其反复提示模型,不如让一个自主代理自主工作,规划任务,将其分解为较小的任务,并实现整个想法。
计划非常宏伟。支持者们提出了一种基于 LLM 作为推理引擎的复杂架构,其中包括一个专注于规划、任务管理和优先级设置的独立部分。这一理念包括一种以嵌入形式管理代理记忆的方式,以及一种在需要时存储和检索这些记忆的向量数据库。
因此,当时似乎认为向量数据库是整个解决方案中重要的组成部分。其他 AGI 项目也采用了相同的方法,比如 BabyAGI。
事实证明,AutoGPT 最近进行了 “向量内存改造”,删除了所有向量数据库的实现,只保留了一些负责内存管理的类,而 JSON 文件成为了存储内存/嵌入的默认方式。
#02
过度复杂的解决方案
Jina.AI 创始人肖涵博士曾在他的文章《Auto-GPT Unmasked: The Hype and Hard Truths of Its Production Pitfalls》中批评原始 AutoGPT 的选择,将向量数据库称为 “过度复杂的解决方案”。
这一观察实际上非常简单:
假设 LLM 需要 10 秒来生成一个完成的任务 —— 这是要存储的单个新内存。当你积累到 100,000 个这样的内存时,所需时间为:100,000 * 10 秒 = 1,000,000 秒 ≈ 11.57 天。
现在,即使使用最简单的蛮力算法,比如 Numpy 的点乘查询,也可能只需要几秒钟就完成 —— 这种优化完全不值得!你根本不需要近似最近邻搜索,更不用说向量数据库了。
关于重新引入向量数据库,目前有一场正在进行的讨论,作者提到这并不是他们目前的重点,尤其是他们并没有看到任何附加价值。
过度设计
作为工程师,我们常常会对炒作产生兴趣。我们沉迷于学习新事物并构建复杂的、全能的解决方案。不出意外,AutoGPT 一开始就包括了向量数据库。但随着时间的推移,优秀的工程师开始关注真正重要的事情。炒作已经过去,现在需要为实际用户提供价值,这时复杂性就成为了我们的敌人。
#03
多代理协作
目前,另一个重要变革正在发生,即引入多个代理,它们高度专业化,以任务为导向,具有自己的记忆和责任,彼此合作。
事实证明,采用一刀切的方法,让一个全知全能的代理处理所有任务,表现并不出色。
以任务为导向的代理可以获得某个任务的示例,并通过上下文学习来更自然地执行任务。这也将限制提示的长度 —— 最近的研究表明,LLM 倾向于忽略提示中间的部分。
示例工作流程
多代理方法的一个示例可能是 GPT Pilot。它旨在创建多个代理,对应于软件开发公司中已知的角色:产品负责人、程序员、DevOps、架构师等。下面是 GPT Pilot 创建应用程序的步骤:
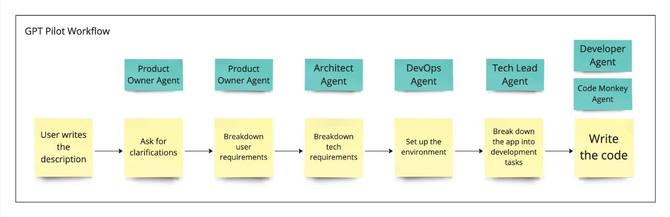
GPT Pilot 也不使用任何向量数据库。编码工具通常使用不同的方法来获取相关上下文,例如 GitHub Copilot 的算法通过查看最近使用的文件或打开的标签页中的代码来实现。
从稍有不同的角度看,对于类似 AutoGPT 的项目,有两种选择:
通用代理,针对每个不同的任务替换其思维
高度专业化的代理,具有自己的短期记忆,专门针对特定任务
第二个选项似乎更有可能在特定任务上实现更高的准确性,提示和代理的身份也可以更精确地描述如何解决问题。
#04
搜索代理
自主代理可以使用各种我们提供的工具。它们可以使用 Google 来查找网络上的相关信息,也可以使用计算器,甚至编写和执行代码来解决特定任务。
与其获取相关的记忆,为什么不直接使用常规搜索来查找重要信息、以前的笔记呢?
搜索可以是一种抽象的概念,可以是关键字搜索、向量搜索或混合搜索,关键在于代理可以以不同的方式多次查询,直到找到所需的信息或得出信息不存在的结论。
#05
简而言之
AutoGPT 决定放弃向量数据库是朝着正确方向迈出的一步,专注于提供价值而不只是考虑技术。
编码助手,如 GPT Engineer、GPT Pilot,甚至 GitHub Copilot,并没使用向量数据库,而是通过查看文件的最近使用情况、在文件系统中的接近度,或查找特定类别或函数的引用来找到相关上下文。
BabyAGI 仍然假定将记忆存储在向量数据库中,但似乎没有太多更新,原始作者决定将算法保持简单,作为其他项目的示例或基础。
复杂性是开发人员的最大敌人。
未来会发生什么?
向量数据库会被重新引入 AutoGPT 吗?
向量数据库实际上是否是 AI 革命的重要组成部分?还是 Pinecone 的愿景成为 AI 的长期记忆只会被认为是一句空口号?
有人认为真正的问题在于像 AutoGPT 这样的项目并没有提供真正的价值,发挥这些项目的价值可能还需要几年时间。
再次强调,时间证明一切。

