华为云王传廷:融合普惠的云数仓——解析华为云GaussDB(DWS) 3.0
本文摘要:
现代的数据分析需求已经远远超出传统BI的范畴,云原生、湖仓一体、数智融合成为了现代数据栈的发展趋势。
华为云GaussDB(DWS) 3.0是新一代云原生架构数据仓库,将高并发、高性能、交互式的查询体验带入湖仓融合的数据栈,GaussDB(DWS)使能数据生产线与AI生产线的无缝高效配合,具有云化架构的资源池化存算分离,与云深度结合和优化的显著特点。
本次分享将简要概述华为云数仓技术架构,着重介绍华为云GaussDB(DWS)在云原生、打通湖与仓的生态、融合数与智等方面的关键特性。
演讲正文:
数据仓库的趋势:下一个十年,智慧数仓提供开放、融合、云化、实时、全场景分析。
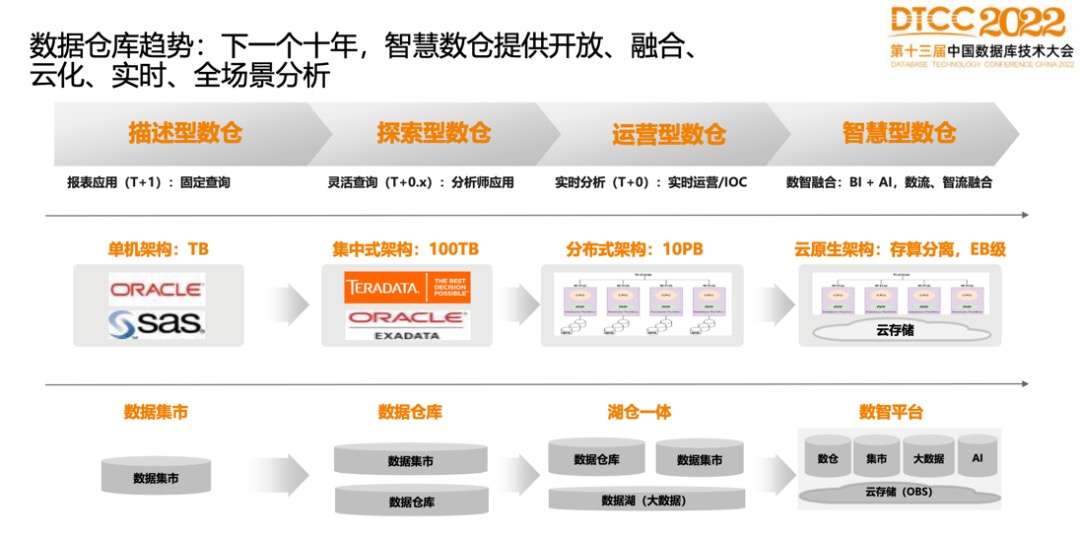
数据仓库从数据量上来讲,从较小的数据量到现在PB级,甚至EB级的数据,数据量越来越大,数据分析架构也从最初的单机架构到集中式架构,到十多年前比较热的分布式架构,再到前几年的云原生架构,架构一直在螺旋上升。
GaussDB(DWS)十多年前一开始做数据仓库,采用的就是分布式架构,好处是相比商业数据仓库而言,性价比比较高,因为是用本地盘,没有昂贵的集中式存储。性能的扩展性比较好,但是不太灵活的点是:计算节点扩容时要做数据的搬迁,因此从应用角度来看,弹性不是特别敏捷,上云之后,计算和存储天然就是分离的,于是我们开始向云原生架构转型。
云原生架构非常重要的特点是:存算分离。从业务角度来看,看到的是计算和存储可以分别做弹性,弹性更为敏捷,对应用来讲,弹性的时效性也更好,因为在做计算弹性时已经不需要做数据的重分布了,可以做到比较实时的弹性。而且在计算和存储分离之后,数据仓库一般都会采用对象存储,像GaussDB(DWS)用的华为云OBS也是对象存储,成本会降低很多,带给应用的价值就是性价比会提升很高。
从数据仓库本身架构上来讲,现在大部分厂商都是在朝着云原生去做。
从数据仓库支撑业务来看,从传统支持离线T+1的固定报表分析业务到现在数仓像OLTP一样,已经是一个实时的生产系统,可以做实时入库、实时分析、实时运营或风控分析。现在很多数仓企业或产品在北向也提供了更多能力,例如更丰富的BI以及AI能力,从单一数仓扩展为一栈式数据分析平台。
从南向角度来讲,数据仓库从原来只能处理仓库内的结构化的数据,到现在可以处理来自于不同系统、不同类型的数据,例如跟大数据做融合或者跟云存储上裸的数据做融合。
因此,总结来说,数据仓库本身会走向云化、实时、湖仓一体,从单一的数据分析产品演变为全场景的一站式数据分析平台。
GaussDB(DWS)演进历史:十年技术沉淀,厚积薄发
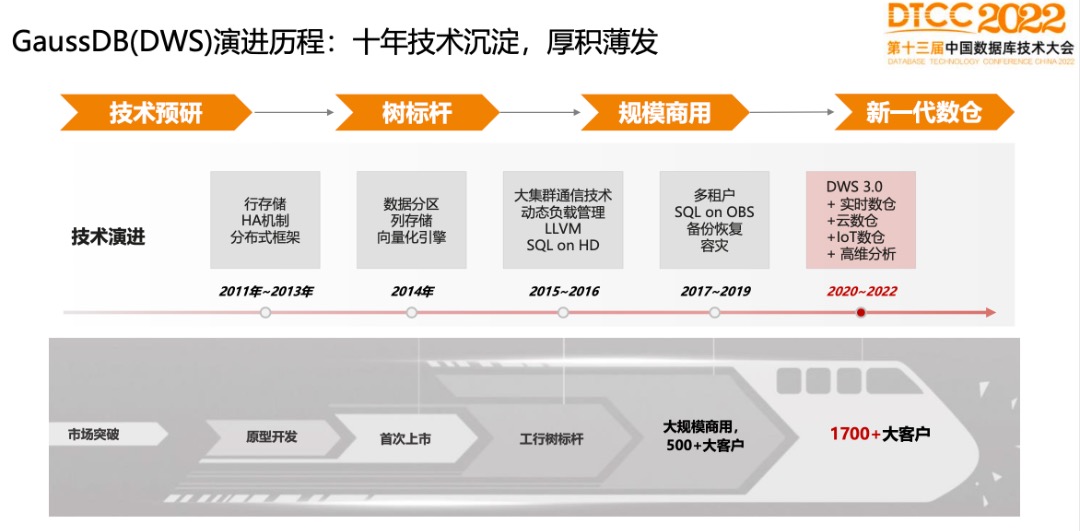
华为在2011年开始储备OLAP技术,首次对外上市是在2014年,2015、2016华为一直在工行做国产替代,到今天差不多有2000个大客户。起初,GaussDB(DWS)主要做的就是列存储和向量化等OLAP领域比较普适的技术。
在GaussDB(DWS)面向客户后,增加了很多企业级特性,特别是高可用方面,由于数仓巨大的数据规模,带来了比较大的挑战,此外还要和客户已有技术资产做集成。GaussDB(DWS)相继实现了大集群通信技术、动态负载管理、LLVM(编译执行)、多租户、SQL on HD,SQL on OBS、备份恢复、容灾等。
GaussDB(DWS)在2020年开始预研DWS 3.0的架构,这也是今天演讲的重点。
GaussDB(DWS):新一代全场景云数据仓库,简化IT架构使能人人用数
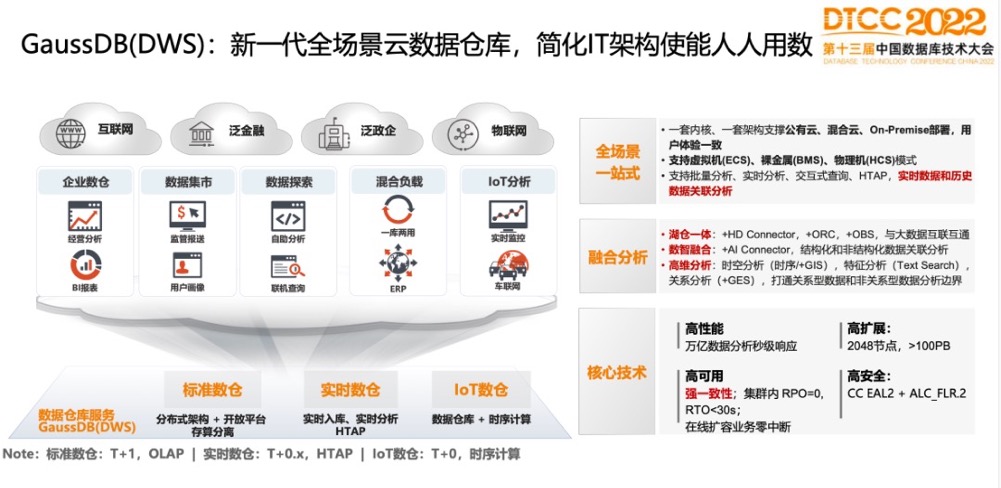
GaussDB(DWS)的定位是提供全场景、一站式的云数仓分析平台,为用户提供在各种场景下一致的体验,用一套产品去支撑T+1的跑批分析、实时入库、实时分析、时序分析等所有跟数据分析相关的业务。
GaussDB(DWS)现在做到的,也是用一套内核、一套架构同时支持公有云、混合云和on-premise部署,支持虚拟机、裸金属、物理机等部署模式,用户体验一致。从业务特征上来看,支持批量分析、实时分析,交互式查询、HTAP以及实时数据和历史数据关联分析。
在融合分析方面可以跟大数据系统做互联互通。核心技术有高性能、高扩展、高可用、高安全等四大特征。
在高扩展方面,GaussDB(DWS)通过了信通院2048节点大集群的测试。高可用的强一致有两个维度,从分布式事务角度来讲,是强一致模型,写进去的数据可以立马看到。从数据多副本角度讲,主备一开始就使用强同步的复制协议,主备数据完全一致,从主机切换到备机后,数据没有任何丢失,业务不需要做追增。在高安全方面,GaussDB(DWS)是国内首家通过了国际CC安全认证的数仓产品。
云数仓技术特点:分层弹性、横向融合、数智融合
` 分层弹性
GaussDB(DWS)采用存算管的三层分离的架构。计算、存储独立伸缩,进一步朝Serverless化的演进。另外,计算、存储分离之后非常方便地做数据共享,数据共享的代价非常低,实现零拷贝的数据共享。
` 横向融合
北向提供了更多编程语言、驱动支持,接入更多的报表、商业分析等数据分析软件,南向实现湖仓一体、数智融合,打造端到端一站式的服务。
` 数智融合
面向内部,做自动负载分析或自动调优去降低使用成本、维护成本,提高性价比。
面向客户,把数仓跟AI生产线做一些融合,能够让AI使用更加方便。
GaussDB(DWS)3.0的Serverless云原生架构,极致弹性,湖仓一体,数智融合
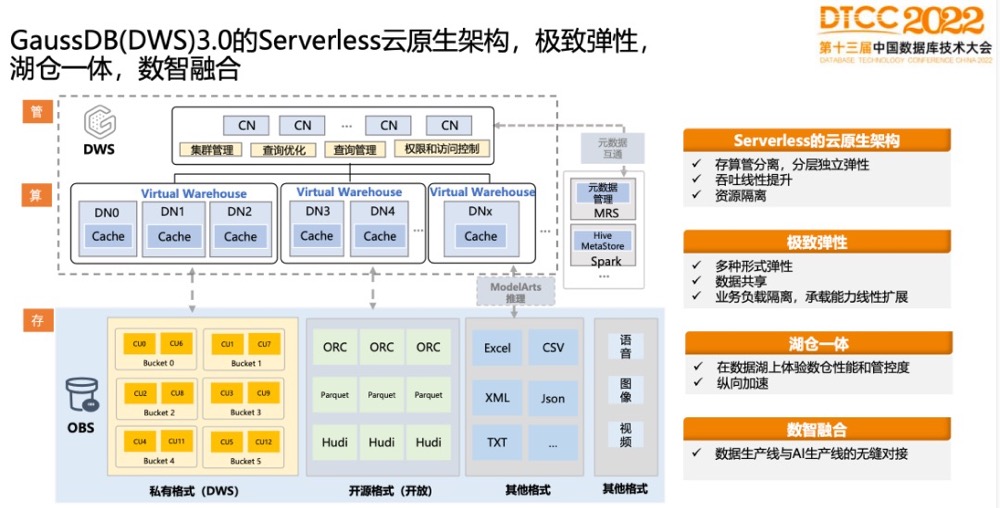
如上图,GaussDB(DWS)采用存算管的三层分离的架构。
存储层,现在支持开放格式和私有格式。开放格式支持ORC、Parquet和Hudi格式,GaussDB(DWS)还有自己的私有格式,私有格式上会提供更丰富的索引,存算分离之后数据是按bucket拆开存储到华为云OBS对象存储上,目的是为了让计算弹性会更加容易。
计算层,有逻辑集群的概念。计算层可以支持多个VW,VW借助OBS实现数据共享,不同VW又能做到计算资源隔离,可以为不同的业务服务,每一个VW都可以独立扩缩。
管理层,主要是做查询优化、权限访问、全局事务等功能,同时具备对接Hive MetaStore能力,可以直接读Hive里的表,跟它做关联分析,也就是湖仓一体。
弹性优势:极致弹性、数据共享,赋能高灵活度、高性价比的使用体验
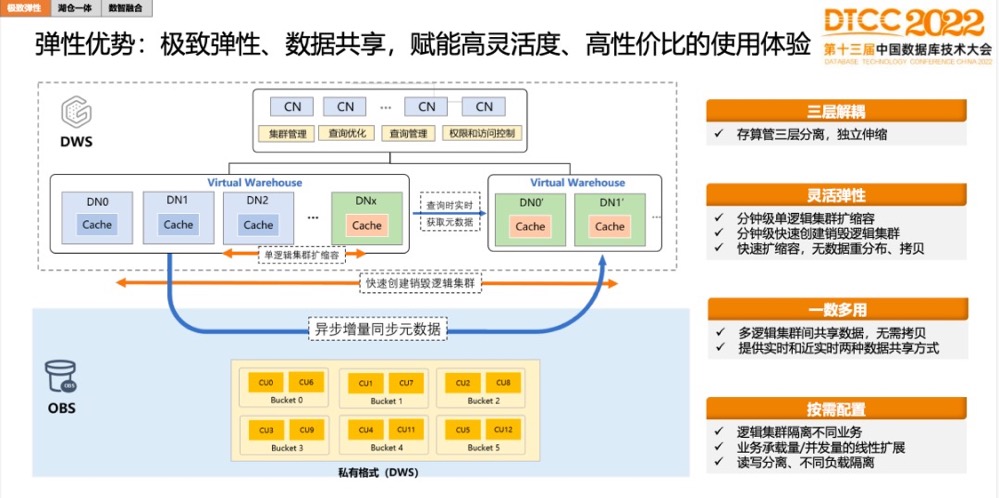
这里主要讲计算的弹性,存储的弹性更多是依赖OBS本身的弹性。GaussDB(DWS)会把数据在OBS上拆成一个个小的bucket去存,每个VW就是一个计算物集群,里面有多个DN,每个DN跟bucket之间做绑定,比如有6个bucket,3个DN,每个能绑定2个bucket做计算,当有6个DN的话,每个DN绑定1个bucket做计算。这样单VW内DN扩缩,只需要修改映射关系,扩容速度会非常快。
另外,计算的弹性还体现在,可以扩展多个VW,比如业务并发很大,刚开始是几百并发,后面几千并发,一个VW撑不住时,可以扩多个VW去支撑。
每个VW都可以做读写,而不像传统的只能增加只读的VW,GaussDB(DWS)每个VW都可以做读写。
GaussDB(DWS)在做存算分离时,并没有损失掉已有的SQL能力,有些云数仓相比一体化的本地盘部署形态丢失了很多特性,比如:索引、主键、唯一约束、分区表等能力,在云数仓形态下就不支持。GaussDB(DWS) 在做存算分离时,设计方案一直保证了对前项功能兼容的能力。
多VW共享。数据都是在OBS上,数据部分天然就是共享的。多VW之间数据共享,除了数据,还有很多存储元数据,比如在数据基础上做的一些索引,数据部分通常写下去之后不会动了,如果做更新或删除时,通常会改元数据。这部分存储元数据的同步比较困难,直接放到OBS上去效率也会很差。
因此,存储元数据的共享实际上是实现数据共享最关键的一环,那怎么做存储元数据共享?GaussDB(DWS)提供了两种共享方式:
第一种方式:近实时。原理就像主备异步复制一样,VW1同步增量到VW2,但是,实现时,VW2和VW1之间并没有建立复制链路,而是借助了OBS。VW1会把增量写到OBS上,VW2从OBS上加载增量,通过OBS作为共享的媒介,来简化VW之间同步的维护代价。这个同步的箭头是双向的,每个VW都可以做读写,可以双向同步。同步是定时触发的,有数据新鲜度延迟。
这种方式类似于主备异步复制方式,数据多少有点延迟。
第二种方式,类似Oracle RAC,如果VW2直接读VW1内存状态,就可以读到最新的数据,我们称之为实时共享模式,可以到VW1源端集群上读它最新的状态,这种情况下,查询就是实时的,VW1写下去的数据,VW2立马可以读到。
按需弹性实践:高性价比地适应灵活多变的业务需求
如果业务特点是比较稳定的,变化不是很频繁,比如,每个季度数据量或者业务量才会发生一次大的变动,就可以用一个VW去承载,按季度或者按业务量做节点扩容。还有一些业务变化比较快,比如一天之内都会有不同的变化,业务1点在8点时需要一个小的VW,单DN可以承载,中午业务上来了,需要3个DN的VW才可以承载。到了晚上8点又缩回去了,到凌晨又需要弹回来,也可以通过一个VW去承载。
另外一部分场景是,不同的时段,业务类型差别很多,可能会在晚上增加新的业务类型,比如跑批业务、日结业务或数据加载业务,这时候可以启动新的VW去承载新的业务,业务跑完之后,VW自动销掉。
所以,GaussDB(DWS)可以做到:1.对单VW按时间做弹性伸缩,去支撑单个业务的扩展。2.对于不同类型的业务,也可以扩展新的VW,这个业务跑完之后VW就自动停掉,为业务提供更好的性价比,不需要买一个很大的集群一直放在那里。
湖仓一体:与大数据互联互通,体验横向融合分析
华为在很早之前就支持这个特性,之前是通过外表技术,对于Spark或Hive的一个表,需要在数仓里建一张外表和它一一对应,就可以查Spark和Hive里的数据。这种方式的问题是维护代价比较高,当表的规模是上千或上万时,都需要建外表,而且Spark表结构变了之后,外表也需要同步刷新,维护代价会比较高。
现在引入External schema的概念,可以创建一个External schema,创建之后,可以通过schema.table方式去访问Hive和Spark的元数据,和正常SQL一致,还可以和DWS的内表做关联分析,可以充分使用。DWS的优化器能力和执行引擎能力,性能更好。
现在外表支持的数据格式包括ORC、Hudi、Parquet。
不但可以支持查询,而且可以支持写出,可以把DWS数据写到OBS上,让Spark来查。
纵向加速:灵活可配的性能优化选择,保持优异性能
计算存储分离之后,如果不做性能优化,性能肯定是比本地盘要下降的,因为计算和存储拉远了,拉远之后时延变高,性能肯定会受损失。所以GaussDB(DWS)在性能加速方面做了很多事情。
今天主要分享三点:
第一:缓存。缓存可以理解是把移动数据到计算这边,缓存可以用盘,也可以用内存。这是一种思路,就是把数据移动到计算端。还有一种思路是把计算下推到数据端,让一些无关的数据可以提前过滤掉,就是算子下推。
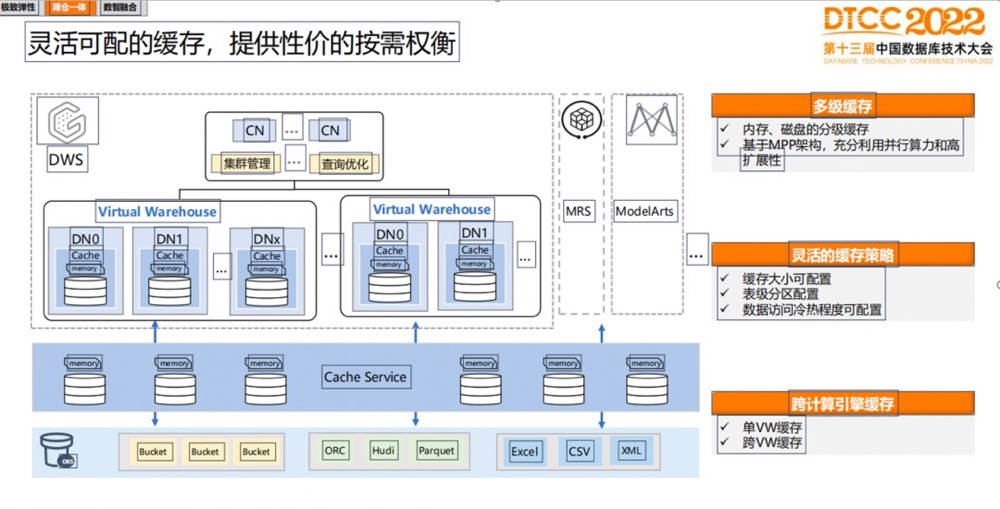
在100%缓存情况下,跟原来本地盘性能基本可以做到持平。
缓存方面做了两层:第一层是单VW内的缓存,可以指定哪些对象做缓存,也可以让系统自动根据数据访问热度自动做缓存。第二层是支持网络缓存服务,就是跨VW的缓存服务,这个服务好处在于,可以让VW启停时性能预热速度更快一些。
第二:算子下推。相当于移动计算到数据端,GaussDB(DWS)支持把简单的一些过滤条件下推到OBS上去,可以提前过滤掉一些无用数据,减少计算和存储之间的网络传输量。
第三:IO调度。OBS的特点是时延高,但带宽比较大,想法是怎么用它的大带宽去弥补时延不足。
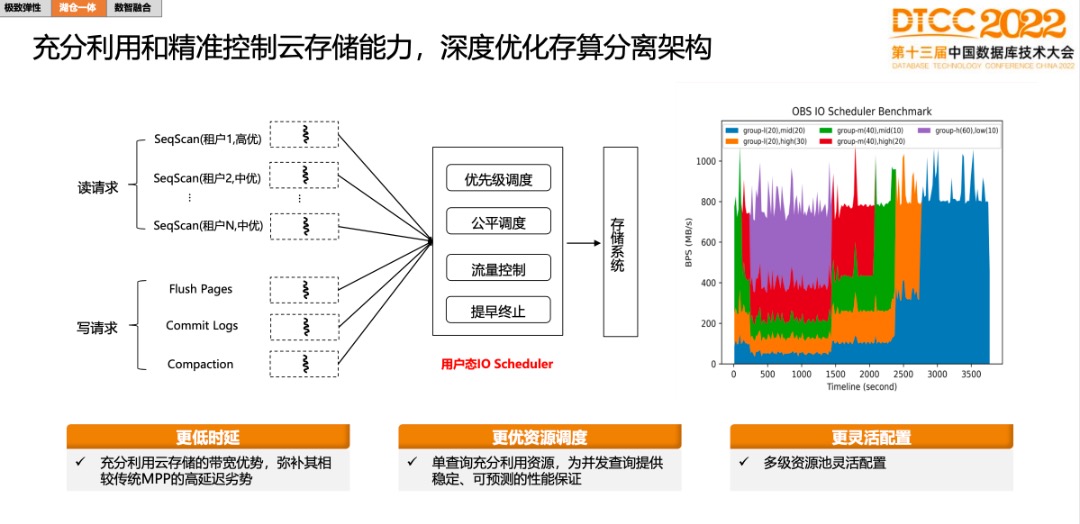
效果如上图,当只有1个查询时,可以把资源跑满;当中间有5个并发在跑时,可以根据业务优先级做优先级调度,紫色的优先级最高,就可以拿到更多的IO资源。IO调度的效果就是,充分把带宽打满,同时让资源之间竞争更加公平。
数据生产线与AI生产线的高效配合
数据生产线和跟AI的生产线如何更高效融合,可以分为两部分:
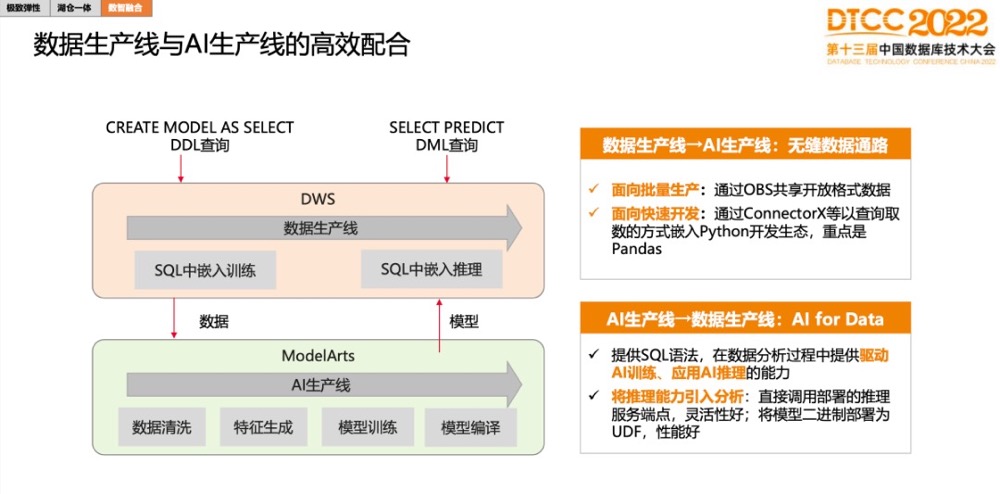
GaussDB(DWS)数据怎么能够比较快地流动到AI去。有两种场景,1)批量数据,DWS可以存储到OBS上,通过OBS实现和AI之间的数据共享。2)即时查询,我们优化了一些数据访问插件,可以让它从DWS上取数据的速度更快。
|华为云GaussDB(DWS): 企业数字转型的理想合作伙伴 |
华为云GaussDB(DWS)深入云原生数据仓库技术的研究和实践,发挥自身优势,以丰富的跨域业务场景和实践经验,助力千行百业数字化转型。截止目前,已服务全球1700+客户,遍布金融、政企以及互联网等行业。面向未来,华为云GaussDB(DWS)还会继续携手更多合作伙伴,打造更优、更专业、高效的数据仓库服务,加速企业数字化转型,创造数字化新未来。
|嘉宾介绍|

王传廷
华为云数据仓库技术专家
王传廷,华为云数据仓库技术专家,具有10年+数据库内核开发经验。

