后分库分表时代的数据库新选择:二维火搭载OceanBase再出发
作者:二维火 运维总监 三七;OceanBase解决方案架构师 孙鹏
如今,在中国任意走进一家餐饮商户,不论其规模大小,扫码点餐、自助点餐机、商家点餐小程序等已经基本成为标配。随着餐饮行业数智化持续加速推进,餐饮 SaaS 已经逐渐成为商户们的“必选题”,二维火便是这“必选题”之一。2007 年,二维火发布餐饮管理系统 1.0,深耕餐饮SaaS领域十余年,目前,二维火已经形成涵盖智能化找店、点餐、营销、管理、供应链服务的全产品矩阵,服务商户49万余家,服务范围覆盖400多个城市,注册会员超2亿。
餐饮 SaaS 有一个特点,中午、晚间点餐高峰期系统高并发,大量订单的写入和查询对系统的抗压能力要求很高。作为 Cobar 长期用户之一,单点瓶颈的消除在过去对业务稳定发展有很大帮助,但伴随着应用和高可用性上的限制,以及运维复杂度的增加,对业务未来的升级创新,二维火还是感受了到掣肘。近期,二维火开始选型满足其业务长远发展的分布式数据库,本文将从“分库分表”出发,阐述二维火选型新数据库(OceanBase)背后的考量。
“分库分表”的诞生
21世纪的第1个十年,互联网产业蓬勃发展,面对互联网海量数据存储与处理的需求,在扩展性上存在瓶颈的传统商用关系型数据库越发显得捉襟见肘。NoSQL 数据库如 Redis、MongoDB 等的快速、可扩展特性在特定场景优势明显,可以作为关系型数据库的有效补充,却不能完全取代。
当硬件发展的速度已经跟不上业务需要,传统商用关系型数据库又面临着高昂的 License 费用,头部互联网公司自然开启新路径探索。
分库分表方案在时代的大背景下应运而生,化整为零,分而治之。在 Amoeba 的基础之上,2009 年 Cobar 初版完成,开始在阿里巴巴集团内部使用;2011年完成集群化改造;2012年6月,Cobar 开源。
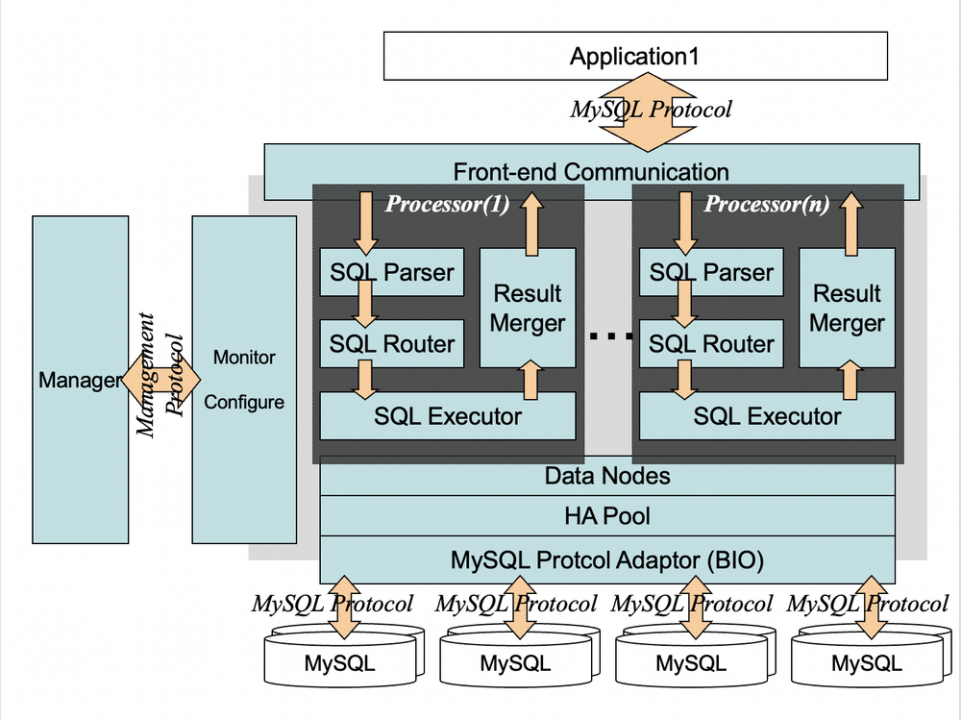
Cobar 架构图(图片来源于网络)
Cobar 本质上是一个关系型数据库的分布式处理系统,是提供关系型数据库(MySQL)分布式服务的中间件。和很多用户一样,二维火当初选择 Cobar 作为中间件构建业务系统主要出于以下考虑:
· 突破单点性能瓶颈
· 解决单实例连接数过多
· 可用性问题,Master 故障的发现和切换
· 使用开源 MySQL,避免高昂的软硬件费用
“分库分表”壮大背后的隐忧
21世纪第2个十年,由于人口红利尚在,互联网产业继续高歌猛进,MySQL已经成为大多数互联网公司建站的首选和事实标准,相应配套的分库分表解决方案也如雨后春笋般不断涌现,很多公司都研发了自己的分布式数据库中间件,Cobar 进化为 MyCat,工作在客户端的 Sharding-JDBC 也被很多用户认可并采纳。简单列举常见产品,如下图所示:
分布式数据库中间件常见产品罗列
上述远非可用分库分表方案的完整列表,但总结所有方案基本分为两类:第一类,作为独立进程运行的中间件,第二类,工作在客户端的插件。这两类方案为解决单点瓶颈而生,但在实际使用中其实会给用户产生各种烦恼,例如:
· 应用限制,很多只支持简单的SQL,复杂应用需改造
· 非 Sharding Key 查询
· 分布式事务和数据一致性
· 不成熟的高可用
· 运维复杂
选型新数据库背后的考量
21世纪第3个十年,国内互联网用户数量基本见顶,叠加持续三年的黑天鹅事件影响,增量市场转为存量市场,很多企业不约而同将“降本提效”提上日程。
在数据库领域,分布式数据库和云数据库进入百家争鸣的时代,不论是从架构还是从设计上,以及从众多用户的实际使用情况上来看,均优于“分库分表”。在这样的形势下,以“降本提效”为目标,二维火也开始了新数据库的选型。
目前,国内市场上的分布式数据库主要有两种:分布式中间件再增强产品和原生分布式数据库。考虑到使用 Cobar 的过往经历,为了彻底摆脱分库分表的束缚,二维火着重调研了后者,并最终选择 OceanBase。总的来说,二维火最终选择 OceanBase 的主要原因如下:
· 首先,原生支持多副本数据强一致,保障数据安全。OceanBase每个节点均支持读写,分区的数据副本根据规则设置在多个节点同步。同一个分区的多个副本基于Paxos一致性协议保证副本的强一致。主分区拥有数据最新版本,具备强一致性读和写能力,备分区具备弱一致性读能力。
· 其次,大集群多租户模式在保留隔离能力的同时又能提高资源利用率,方便管理且降低运维成本。OceanBase采用原生多租户设计,支持将多个传统数据库合入一个集群,租户间数据相互隔离,可设置各自资源占用,并支持平滑扩展收缩。

OceanBase 多租户
· 最后,OceanBase 存储层基于 LSM-Tree 架构,写入先进内存,磁盘上基线 SSTable 相对静态,为数据编码/压缩的实际应用打下良好基础。通过在变长 16K 微块上应用字典、RLE、差值、常量等编码方式,行列混存,编码后的数据进行 ZSTD 压缩,可以大幅节约存储空间,对海量数据场景非常友好。配合Block/Row/BloomFilter多级缓存,降本提效双管齐下。
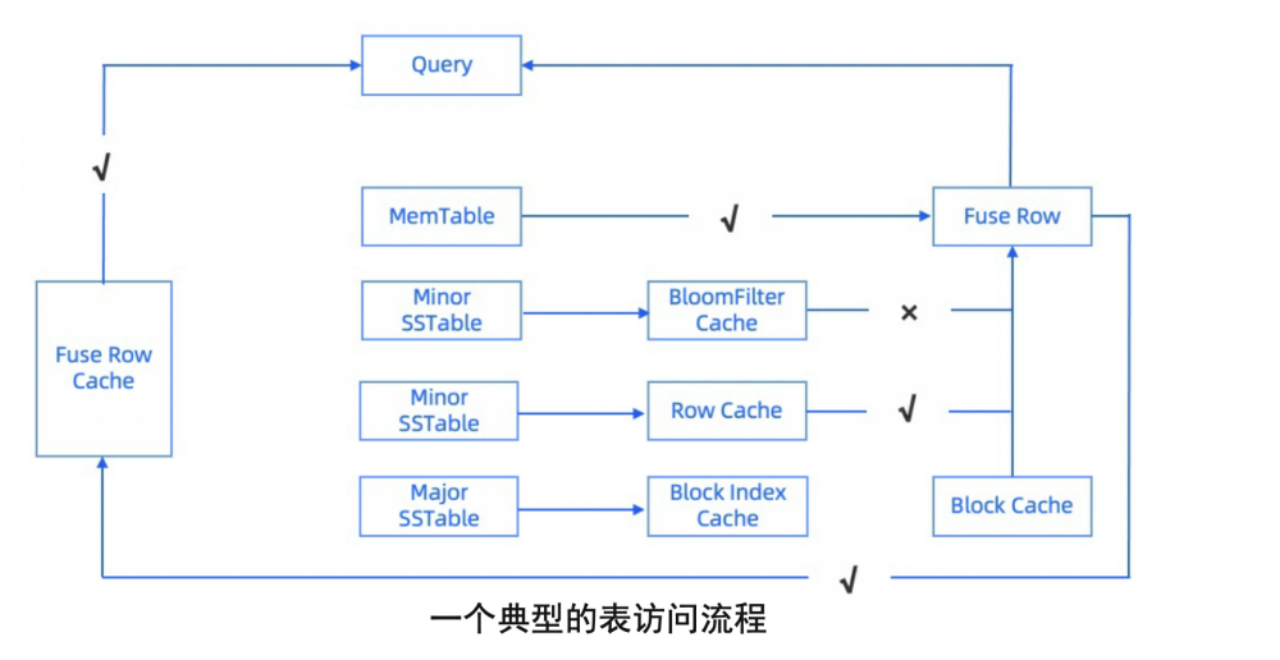
一个典型的表访问流程
业务初探:成本显著降低,归档性能提升
在决定和实践之间有一项关键能力需求:出于对服务高可用性的坚持,避免不必要的停机,二维火需要整体的迁移切流方案面对基于 Cobar 的应用系统支持灰度切流和反向增量。
· 从业务上来看,有了这项保障,假设更换系统后出现任何短时间无法解决的问题,都可以切回源端,最大限度降低对业务的影响;
· 从技术上来讲,这意味着当业务流量已经部分切流的情况下,迁移程序能够区分在目标端上的业务增量和同步增量,并准确的把业务增量通过 Cobar 中间件层回写至源端,以时刻保持两边的同步。

从 Cobar 迁移至 OceanBase
可惜的是,OMS(OceanBase Migration Service,OceanBase 数据迁移工具)一开始并不具备此项能力,我们只好等待。可喜的是,短短数月后再次沟通,OceanBase 团队已经将此项功能开发、验证、打磨完毕,产品迭代发展速度出乎我们的意料。
扫清了切流障碍,二维火选择存储量大、写多读少的归档库作为试点迁移至 OceanBase,迁移/切流过程顺利:对源端每个 MySQL 物理实例建立正向链路迁移/同步数据至目标端 OceanBase,同时建立一条 OceanBase 至源端中间件层的反向链路,OMS 的数据校验功能也确保了数据的无损和一致。
在 OceanBase 侧验证各项业务操作后,应用服务器通过滚动重启的方式切换数据源,实现业务无感在线切换。
归档库切换 OceanBase 后,凭借 OceanBase 的高级压缩技术,所需存储空间缩减至原有的 1/5,降本效果立竿见影;同时,得益于原生分布式架构,数据归档和历史信息查询的性能也有了明显提升。
从理论分析到切流验证,整个过程一气呵成,这给了二维火将变革向其他应用推动的信心和决心。目前,二维火正在将点餐、营销、管理、供应链等餐饮服务进行数智化升级,以期为商家提供更高效、智能的服务,助力商家成功。同时,我们也期望 OceanBase 公有云产品早日上线 binlog service 服务,让现有业务系统的迁移免去适配的成本,为二维火的产业升级持续助力。

