Intuit公司拥有1亿多客户,收入接近100亿美元,有大规模的数据处理需求,也有大规模的挑战。如果为每个大数据项目建立独立架构,这将加剧数据孤岛的问题,Intuit采取了统一的方法,利用Lakehouse作为整个企业的数据标准。
Intuit公司以TurboTax和QuickBooks闻名,这是有史以来最成功的两个消费金融产品。但随着最近机器学习的发展以及对Credit Karma和Mailchimp的收购,Intuit正在推进将自己改造成一个AI巨头。
“Intuit正在转型为一个人工智能驱动的专家平台,”该公司产品管理副总裁Alon Amit在Databricks的数据+人工智能峰会上说。“我们正在帮助人们走向繁荣,曾经希望帮助你完成你的税收和账目的工作。但现在它意味着更多。”
例如,该公司正在使用机器学习来帮助对QuickBooks中的交易进行分类,将客户从手动分类的繁琐工作中解救出来。这需要机器学习非常个性化,就像Credit Karma服务一样,根据输入的信息自动推荐个人如何提高他们的信用评分。
开发这些新的数据驱动的产品需要有一个可靠的数据架构来构建。该公司希望避免为每个项目构建不同的数据系统,而是让成千上万的分析师、数据科学家和软件工程师在同一个页面上使用统一的数据视图。
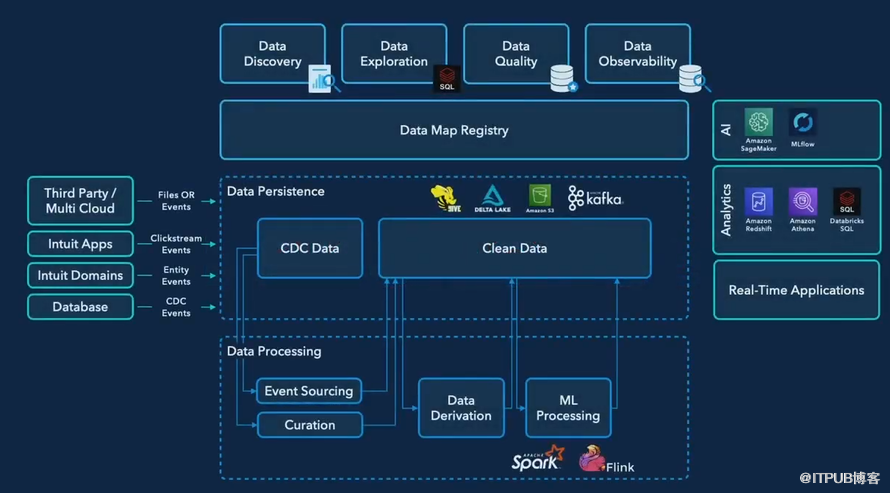
Intuit的数据架构包含了许多部件(图片来源:Intuit)
三年前,当Amit和Manish Amde(现在是Intuit的工程总监)一起加入公司时,Intuit还没有这种架构。Amit和Amde都曾在Origami Logic工作,该公司被Intuit收购,帮助建立数据和AI架构。
“我们的数据之旅开始于一个在座的许多人都会熟悉的地方,”Amde在数据+人工智能峰会的主题演讲中说。“我们的数据生态系统很大,很复杂,很混乱。我们需要一个战略,为消费者和小企业客户释放这些数据的全部潜力。”
Intuit面临的一大挑战是存在多个数据孤岛。几十年的历史信息包含在数十万个数据库表中,这些信息对于帮助Intuit公司的分析师和数据科学家洞察客户需求和建立新产品至关重要。但是,这些信息分散在企业的各个角落,这使得它们很难被访问。复制数据是最主要的解决方案,但这也会带来延迟和正确性方面的问题。
“为了加速我们的数据之旅,我们需要一个统一的架构,能够打破数据孤岛,加速整个公司团队的生产力,”Amde说。“这个架构需要能够大规模地支持不同的工作负载,包括存储和计算;通过流数据支持实时应用;它需要建立在开源的基础上,让我们有机会使用一流的工具,并有机会回馈社会。”
数据之旅
当Amit和Amde来到Intuit时,就像大多数成功的、价值100亿美元的公司那样,他们面临着一定的技术包袱。首先,Intuit是在AWS的上面,它在云上运行一个大型的 "Parquet集群"。是RedShift和Athena客户,而且没有理由离开它们。应用了Apache Flink,因为它可以为流数据提供低延迟。
Amit和Amde需要在这些限制条件(以及其他限制条件)下工作,并找到解决方案。两人在Oragami Logic工作时已经熟悉了Databricks,并知道该平台的能力。Amde还曾与Databricks的创始人合作过,当时Spark还是加州大学伯克利分校AMP实验室的一个相对陌生的计算项目。
“我们在开源方面进行了合作,”Amde说。“我当年为机器学习库做出了贡献。所以我们知道对方是如何编码的。这就是信任的来源。”
数据负责人对新的数据架构有几点要求。首先,内部用户需要能够快速获得查询结果并创建数据管道,以促进实验文化。他们还希望有一个能够处理事务的存储库。
“我们有Parquet,我们的数据湖中有大量的数据。”Amde说。“但我们希望有类似ACID的事务,这样我们就可以开始做几乎实时的处理,无论是写还是读,当有业务需求时。”
最重要的是,Intuit需要的是一个单一的数据架构,可以为多种使用情况提供数据。
“当我们加入Intuit并开始考虑这个数据架构时,我们并没有想过,哦,我们需要为数据科学家建立一个数据架构,为分析建立另一个数据架构。这从来不是我们的计划,”Amit说。“因为我们两个人都在这里呆了很久,知道当你有多个架构时,你就有多个数据。人们读到的数据会不同。而我们不希望这样。”
直观展示
Intuit决定将其新的数据架构建立在Databricks的Delta Lake之上。通过结合传统上与数据仓库相关的元素(如ACID事务和质量保证)以及数据湖的可扩展性和灵活性优势,Databricks声称已经在不可治理的数据沼泽和缓慢适应的数据仓库之间找到了媒介。
Intuit公司战略的一个关键因素是称为数据地图的东西。数据地图由三类数据组成,包括物理层(包含数据和产生数据的代码的位置信息);操作层(包含关于所有权、系统依赖性和数据分类的信息);以及业务层(捕获业务背景并暴露数据与其他实体的逻辑模型)。
“所有这三个层次结合在一起,帮助我们回答我们的生产者或消费者对Lakehouse数据的所有可能问题,”Amde说。“有了这些,我们已经能够建立一个令人愉快的数据发现体验,使用户能够搜索和浏览数据,并探索其他商业实体的关系。”
新的数据项目进行了两年,事情的发展似乎与Intuit的预期差不多。数据工作还没有完成(数据工作永远不会完成),但已经开始有所回报了。
Intuit的Lakehouse架构可以容纳Spark Streaming以及Flink的实时处理。其分析师能够使用Redshift和Athena以及Databricks SQL和Photon驱动的数据科学笔记本访问相同的数据集。该公司能够继续使用Sagemaker作为其主要的数据科学开发工具,并在MLFlow的支持下实现机器学习工作自动化。
但Lakehouse架构最重要的方面是,Intuit公司的不同数据角色对同一数据集都有一致的看法。Amit说,这是一个不容低估的关键成就。
“[我们]更深刻了解到让公司开始有大规模生产具有逻辑和商业意义的数据文化是多么困难,所以你不想要求人们做两次--一次给分析师,一次给数据科学家,”Amit说。“这样做更好,因为每个人都在看同样的数据。”
Amit和Amde还高兴地看到,Databricks已经承诺将其Delta Table的其余部分开源。技术专家们曾鼓励Databricks这样做,而该公司这样做的事实消除了Iceberg的核心优势之一,Iceberg是该公司竞争的另一种开放表格式(此外,还有Hudi)。

