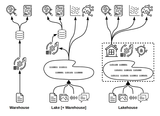
作为在云中进行大数据分析的首选方法, Lakehouse架构正获得越来越多的关注,因为它们将传统的数据仓库概念与当今的云技术相融合。但是,Lakehouse最终会不会像上一代专用数据仓库那样,把客户困在有限的专有建设中?数据管道公司Upsolver的首席执行官Ori Rafael认为,这很有可能发生。

Rafael介绍,Lakehouse架构的一大缺点是目前只解决了一个特定的用例,他在2014年与人共同创立了Upsolver公司。他说,今天,Lakehouse的主要用例是一个数据仓库,或者一个带有SQL查询引擎的列式关系数据库,它是在AWS S3或兼容S3的对象存储(如谷歌云存储)之上实现。
Rafael告诉Datanami,“Lakehouse是仓库的重塑,”。“我想采取这种用例,并在数据湖的基础上实施,所以如果我不使用数据仓库,我基本上是使用Lakehouse。”
但是,除了SQL之外,还有许多其他处理数据的方法,为了不断优化从原始数据获得洞察的能力,需要不同的数据存储模式和查询机制。Rafael说,客户将需要像Cassandra或Redis这样的NoSQL数据库方法,像Elastic这样的搜索引擎,以及像Trino和Presto这样的解耦查询引擎。
“数据有很多不同的用例,没有一个供应商能解决所有问题。”他说,“我可以算出至少有六、七种不同的模式,我想查询数据,所以我需要以多种方式存储它。我需要在我的架构中允许有多个数据库,而不是只有一个数据库。”
当AWS最初描述其Lakehouse概念时,其想法是一个枢纽和辐射的模型,提供许多不同的方式来处理湖中的数据。但多年来,其含义已经发生了一些变化,主要是指数据仓库模式,这是目前最成熟的数据访问模式,但不会是唯一的模式,Rafael说。
在共同创立Upsolver之前,Rafael曾担任Oracle数据库管理员。作为一名Oracle数据库DBA,Rafael努力学习有关RDBMS内部工作原理的一切,以便优化其性能。他看到同样的过程在新的Lakehouse上演,但它是在一个有许多移动部件的解构堆栈中进行的。
“那么,谁负责以正确的方式存储数据,正确的文件格式,正确的压缩,正确的文件大小,所有这些?”Rafael说。“现在,客户需要做这些,所以这就是我在Lakehouse世界需要做的额外数据工程。”
Databricks为采用Delta Lake的客户处理了这些实施细节,这对许多客户来说效果很好。Databricks和Snowflake已经成为除了云计算巨头本身之外,云计算中大数据工作负载的两个最大的独立竞争者。但这两家公司都没有接受开放数据生态系统,Rafael和其他人认为,开放数据生态系统符合那些想要利用数据处理引擎多样性的客户的最大利益。
虽然Databricks表面上比Snowflak拥抱开源的程度要高--实际上Snowflak几乎在一年前就开始反对开放数据平台(后来在Snowpark中提供了Python和Java支持),但现实中使用非Databricks产品的Delta Table还有一些“开放性”上的问题需要改进,Rafael说。
“我认为Databricks所做的是另一个数据仓库,因为用于查询Delta Lake的产品几乎都是Databricks的引擎,”他说。“从其他引擎去查询Delta Lake没有那么高性能或简单。所以我认为他们正在做的是数据仓库的重塑,我认为开源社区正在做的是一个真正的开放的Lakehouse。”
一年前,Databricks推出了Delta Sharing,使Delta Lake用户能够通过Pandas或Spark DataFrames与他人分享数据,或者直接加载到PowerBI。该公司的网站说,对其他目标的支持,如Presto、Trino、R、Hive和Tableau,也即将到来。
数据锁定?
Rafael认为,客户在新的云数据仓库产品中体验到了Oracle和Teradata对数据仓库的锁定。他说,与Oracle一样,你主要是在同一个地方存储数据和使用查询。
Rafael说,从概念上讲,Lakehouse的概念是一个好概念。但在现实中,它只是另一个数据仓库,他说。虽然使用非SQL引擎从一个简单的API轻松查询数据的能力仍然有点青涩,但这种能力很快就会成为在云中运行大数据工作负载的核心要求,而目前的Lakehouse还不能完全做到这一点。
“我认为Lakehouse[有]太多的品牌围绕着它,而没有足够的本质,”Rafael说。“我真的相信Lakehouse概念。这就是我们成立公司的原因,基本上在数据湖的基础上解构数据库是我们成立公司的原因,也是我们的愿景所在。”
Rafael和他的团队开发了Upsolver,以改善客户构建和运行数据管道的方式。该产品主要是用Scala编写,重点是将流式数据和文件自动转化为更容易被云查询引擎(如Presto、Trino和Athena)查询的数据格式。
Upsolver进程依赖于基于SQL的声明式数据管道,从Kafka和Kinesis等来源在S3存储中创建Parquet或Iceberg表。Rafael说,与Spark代码相比,它提供了更好的性能和更低的复杂性。该产品目前在AWS和微软Azure中运行,并通过认证可与Amazon Athena(一种无服务器Presto运行时)一起使用。
“在ETL中,转换通常是困难的部分,我们将这个问题从许多不同的独立步骤转化为一个步骤,”Rafael说。“所以我们称它为声明式管道,你基本上把管道定义为你的转换,就是这样。”
客户在SQL中构建数据转换,Upsolver产品处理其余部分。拉斐尔提供了一个Spark管道的例子,它包含487行代码,而Upsolver管道只包含9行代码。
“这就是声明式的区别,所以你在这里唯一的代码就是转换,”Rafael说。“你只是在写SQL,就像你做查询一样,但你得到一个管道。”
原作者:Alex Woodie