如果你听说过一个叫做“现代数据栈”的东西,那么你并不孤单,谷歌为该搜索返回了4.89亿条结果。虽然现代数据栈似乎并不像以前的计算堆栈那样有明确的定义,但这个术语持续存在促使我们做了一些调查。
在过去,如果你说“哦,我们运行的是LAMP堆栈”,那么你可以迅速传达这样一个事实:你的公司在Linux操作系统、Apache HTTP服务器、MySQL数据库和PHP(或Python或Perl)编程语言上运行应用程序。
现代数据栈背后的想法是类似的,但涉及的部分更多。有数据工程师(ETL工具、转换工具和pub/sub系统)、数据分析师(BI工具、数据仓库)和数据科学家(AI工作台等)的工具。你可以根据受众和需求,很容易地增加一系列其他类别--数据库、数据目录、治理工具、数据协调、实时数据流等。
这个列表很快就会失去控制。然而,现代数据栈存在的核心理念仍在我们的脑海中扎根。我们不得不承认,数据工具确实是一脉相承的。这似乎是Datanami所接触的数据业内人士的共识。
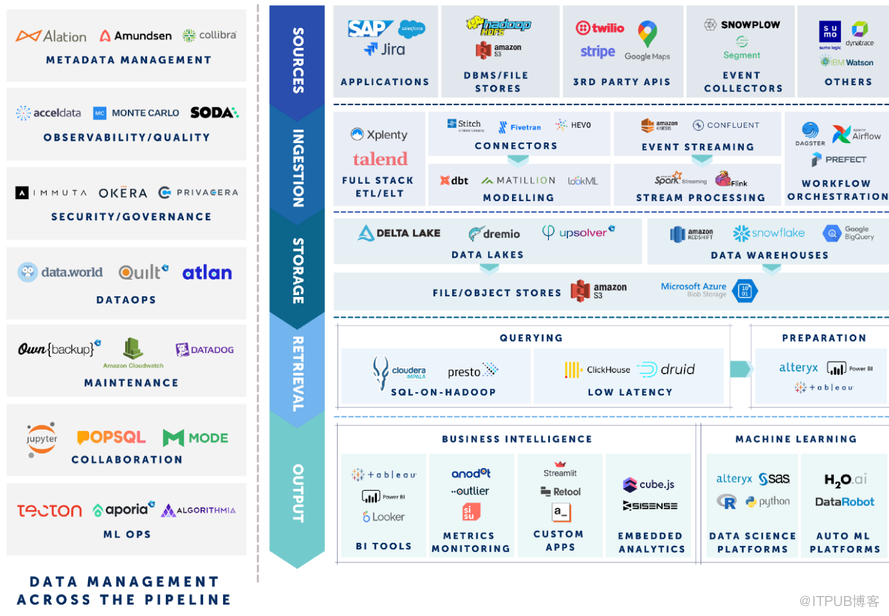
Vertex Ventures描述的现代数据栈视图
“我认为对于某些具有一定规模的公司和某些团队来说,存在着可重复的模式。”数据目录和治理供应商Alation的首席执行官兼联合创始人Satyan Sangani说。“这种东西被称为现代数据栈,有一套特定的工具--我们当然是其中之一,用例具有可重复性,我们倾向于使用的产品也具有可重复性。”
Sangani指出,Alation往往与其他几个产品一起使用,包括用于数据仓库的Snowflake,用于BI工具的Tableau,以及用于数据转换的Fivetran,或者有时是Informatica。
“购买分析工具往往有这些模式,”他说。“有业务分析师的公司,我刚才提到的堆栈往往是很普遍的。在数据工程领域,例如,你可能有一个像Matillion这样的产品,或者你可能有一个像Looker这样的产品。”
Sangani说,对公司来说没有一个万能的现代数据栈。不同的组织有不同的堆栈和不同的工具。如果只有一种方法,那么为什么今天的分析工具公司比10年前多了5到10倍?他问道。
“这不是因为每个人都在做同样的事情,”他说,“这是因为分析基本上是将人类的思想系统化,而这真的很难做到,有很多不同的方法可以做到这一点。”
大数据研究所的Jesse Anderson在Cloudera公司构建第一批大数据栈时,就亲身经历了Hadoop之战。虽然Hadoop不再像以前那样是大数据领域的大象,但Anderson肯定看到了一个确定的堆栈正在出现,它部分由曾经包含在Hadoop发行版中的项目组成(即“堆栈”)。
“我们已经有了Spark,我们已经有了S3或S3风格的存储桶。在pub/sub中常用的Kafka、Pulsar等技术。我们有一些相对标准化的东西用于实时处理,如Flink。然后,当我们开始进入数据库世界时,它就真的爆炸了。我们有寒武纪的大爆发。”

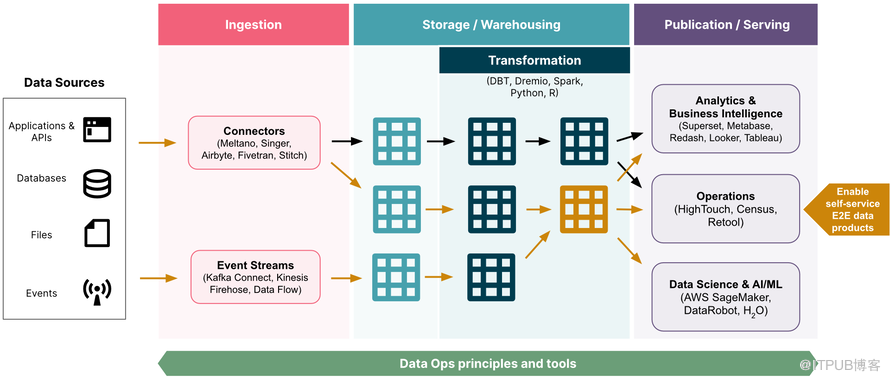
这是一个由Datafold发布的开源现代数据栈图
现在出现的现代数据栈其决定性特征之一是能够快速地用更新的东西取代旧的东西。“领导者应该知道,我们的技术堆栈不会再有20年的寿命了。”Anderson说,“事实上,Hadoop有20年的寿命--我们不会在其他技术上看到这一点,我认为这真的很关键。”
现代数据栈的各种组件在被替换之前的寿命会更短。想出管理这种变化的最佳方法将是工程师和产品开发人员的一大焦点。“如果你有100种不同的技术,而且每个人都在使用它--坦率地说,这对数据网络(data mesh)来说是一个问题。”他说。
数据观测工具提供商Soda的首席执行官兼创始人Maarten Masschelein认为,现代数据栈是用一种新的原则组合在一起的。
“10年前我们对数据的处理方式是非常不同的。”他说,“例如,现代数据栈对我来说是多利益相关者,从非常技术的利益相关者到非常精通业务的利益相关者,它对每个人都有效。”
管理变化的能力,特别是在一个快节奏的环境中,是构成现代数据栈工具的一个重要方面,Masschelein说,“它受到软件工程的影响,因此更有弹性,更快,更敏捷,”他说。“它是构成现代数据栈的各种事物的组合。但我也认为,一年后,我们会说,‘哦,是的,我们说过这个吗?我们用过这个词吗?’”
ThoughtSpot联合创始人兼执行主席Ajeet Singh列出的六条数据新规则中的第一条规则是在堆栈的每一层使用最佳产品。当然,ThoughtSpot的人认为他们的产品是数据体验层的最佳选择,他们在这里与PowerBI、Looker和Tableau等公司竞争。
ThoughtSpot对现代数据栈的看法
“我们正在与现代数据栈中的几乎所有最佳供应商合作。”Singh说,“因此,我们的策略是与其他最好的合作伙伴合作,使客户更容易无缝地获得完整的堆栈。”
在最近的Beyond 2022展会上,许多ThoughtSpot的客户说他们正在使用ThoughtSpot与Snowflake或AWS数据仓库或数据湖,以及Matillion或dbt一起用于ETL或数据转换。
ThoughtSpot首席执行官Sudheesh Nair说,在构建与现代数据堆栈和现代数据生态系统中其他产品共存的产品时,遵循三个核心原则。首先,机器对机器的API体验必须是无缝的。
“当Sean[Zinsmeister ThoughtSpot的营销高级副总裁]展示演示时,他点击一次,dbt就进来了,搜索就发生了,”Nair在最近的Beyond 2022会议上说。“我们正在努力,dbt也在努力,以确保它是无缝的。”
第二个原则是,客户不能掉进两个供应商之间的整合深渊。如果有问题,供应商必须进行沟通,以确保客户的关切得到满足。最后,他说,允许客户将他们的公有云信用额度用于你的产品,会让他们更有可能购买你的产品。
NoSQL数据库供应商Aerospike的首席战略官Lenley Hensarling对现代数据栈有不同的看法。他认为它是一种 数据编织(data fabric),在边缘有快速和灵活的数据库,连续地吸收、处理和移动数据。
“你想在尽可能接近实时的情况下利用数据,”他说,“我们看到客户一次又一次地把我们作为边缘的增强和实时数据系统,然后把这些交易过滤回那些可能发生监管的地方,那些不感兴趣的东西。”
Hensarling认为,实时数据存储必须是灵活和快速的,并支持变化数据捕获和流式数据要求。
“我们看到的是对Spark连接器、Spark SQL、Spark Streaming、Pulsar、Kafka、JMS的需求。”他说,“这提供了人们正在构建的新结构,(以)一种新的程序风格,它是非常分解和解构的,但一直在一起工作....我们认为,拥有这种完整的结构是一个很大的胜利。”
作者:Alex Woodie

