Snowflake可直接运行Apache Spark,与Databricks竞争加剧

Snowflake 宣布推出 Snowpark Connect for Apache Spark 的公开预览版,这是一款新产品,可让客户在 Snowflake 云上直接运行其现有的 Apache Spark 代码。此举使 Snowflake 更接近其主要竞争对手 Databricks 所提供的服务。
Snowpark Connect for Apache Spark 允许客户在 Snowflake 的向量化查询引擎上运行其 DataFrame、Spark SQL 和 Spark 用户定义函数(UDF)代码。这些代码可能与一系列现有的 Spark 应用程序相关联,包括 ETL 作业、使用 Jupyter 笔记本编写的数据科学程序,或使用 Spark SQL 的 OLAP 作业。
Snowflake 表示,借助 Snowpark Connect for Apache Spark,它会自动处理 Spark 代码的所有性能调优和扩展工作,从而让客户能够专注于开发应用程序,而不必管理其底层技术复杂的分布式框架。
“Snowpark Connect for Spark 兼具两者的优势:既有 Snowflake 引擎的强大功能,又有 Spark 代码的易用性,同时还能降低成本并加快开发速度,”Snowflake 产品经理Nimesh Bhagat和Shruti Anand在今日的一篇博客文章中写道。
Snowpark Connect for Spark 基于 Spark Connect,这是一个 Apache Spark 项目,于 2022 年首次亮相,并在 Spark 3.4 版本中正式发布(GA)。Spark Connect 引入了一种基于 gRPC 和 Apache Arrow 的新协议,允许使用 DataFrame API 远程连接到 Spark 集群。本质上,它允许将 Spark 应用程序拆分为客户端和服务器组件,终结了 Spark 在此之前一直使用的单体结构。
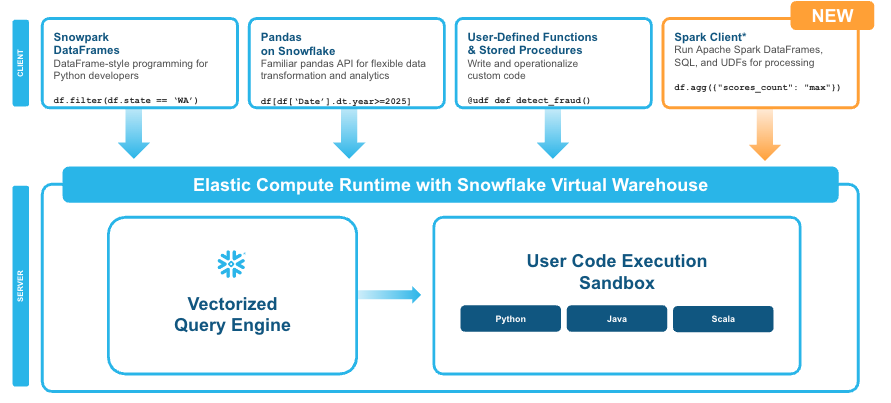
Snowpark Connect for Apache Spark 让 Snowflake 客户能够无需修改即可运行 Spark 工作负载(图片由 Snowflake 提供)
这并非 Snowflake 首次让客户能够在其云上运行 Spark 代码。它已经提供了 Spark Connector,允许客户使用 Spark 代码处理 Snowflake 数据。“但这带来了数据迁移问题,导致额外的成本、延迟和治理复杂性,”Bhagat和Anand写道。
Snowflake 表示,虽然将 Spark 迁移到 Snowflake 提高了性能,但这通常仍然意味着需要重写代码,包括转换为 Snowpark DataFrames。产品经理们写道,随着 Snowpark Connect for Apache Spark 的推出,客户现在可以使用其 Spark 代码,而无需转换代码或迁移数据。
该公司表示,客户可以通过其 Snowpark Connect for Apache Spark 应用程序访问存储在 Apache Iceberg 表中的数据,包括外部管理的 Iceberg 表和目录链接表。该产品仅在 Spark 3.5.x 上运行;该公司称,Spark RDD、Spark ML、MLlib、Streaming 和 Delta API 目前不属于 Snowpark Connect 支持的功能。
此次发布表明,Snowflake 急于与 Databricks 竞争,并争夺其大量的 Spark 工作负载用户群。
Databricks 由 Apache Spark 的创建者创立,其云平台旨在成为运行 Spark 工作负载的最 佳场所。另一方面,Snowflake 最初的定位是为那些对 Hadoop 时代平台的技术复杂性感到不满的客户提供易于使用的云服务。
虽然 Databricks 以 Spark 起家,但多年来其产品范围已大幅扩大,现在正准备成为运行 AI 工作负载的平台,而Snowflake 也在关注 AI 工作负载,双方围绕着Data+AI打得难舍难分。

