这个话题总是让大家有点困惑。我的意思是如何记住每个规范化形式的作用?每次查找它时,都会看到这些复杂的定义。所以我决定一劳永逸地解决这个问题,并分享一种有用的理解方法。
在规范化数据库中,数据以表格形式组织,这样数据库查询或更新的结果始终清晰明确且符合预期。我们可以将规范化视为多层保证,每一层都确保查询或更新数据时有一定的安全性。
什么是冗余
规范化可以消除冗余。它强制数据库不被不必要地复制。例如:
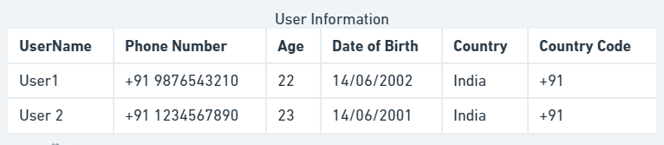
假设我们想在上面的表格中存储用户的信息。您可能已经注意到,同时存储出生日期和年龄是不合逻辑的,因为年龄可以通过出生日期计算出来。这是冗余数据。如果我们犯了一个错误,输入了错误的用户出生日期值,那么他们的年龄列也需要更新。
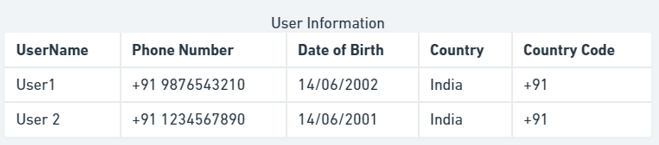
但事实并非如此。假设印度决定将其国家代码从 +91 更改为 +911,现在需要更新此表中的所有行。更好的方法是为每个表建立一个单独的表来存储国家代码,并在获取用户信息时执行连接操作以获取国家代码。

第一范式(1NF)
列中的每个单元格仅包含一种类型的值
大多数基于模式的数据库甚至不允许这样做。
单元格只能保存一个值
如果单个字段有多个值,最好将每个值表示在单独的行中。

数据排序不应该传达任何含义
除非另有说明,否则查询返回的数据的顺序不应具有任何意义(如果我们在查询中使用 ORDER BY 子句,那么返回数据的顺序当然具有一定意义)。

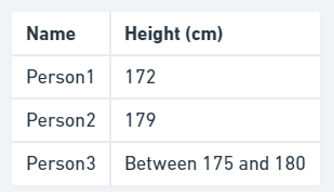
这里,在第一个表中,我们期望以相同的方式返回结果以获取存储的信息(在本例中为高度)。对表的插入、更新和删除操作也成为一项任务。我们必须重新排列现有值。单独存储高度为这些操作提供了灵活性,我们不必依赖存储信息的顺序。
不应有重复的组
假设我们正在创建一个游戏,需要创建一个表来存储每个玩家的库存。存储这些值的一种方法如下。

但是,相同的数据会重复出现(物品名称、物品数量)。假设游戏中有 50 种不同的物品,我们就必须在表中添加 100 个不同的列,而对于那些物品不多的用户来说,这会浪费空间。向游戏中添加更多物品也成为一项任务,因为我们必须执行架构迁移,甚至可能进行数据迁移。
我们可以按如下方式展平表格。
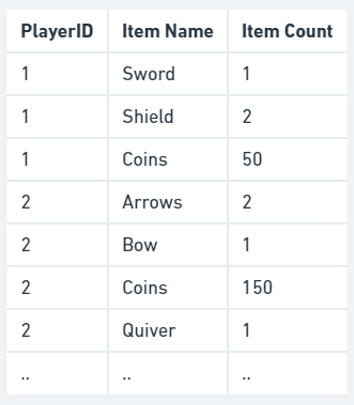
现在,添加新物品变得非常简单,只需在表中添加另一行,并且我们只会使用所需的空间。如果我们想知道玩家拥有的每个物品的数量,我们只需查询包含该玩家 ID 的所有行,其余物品的数量为 0。
表中的每个条目都应该是唯一的
假设我们有一张存储某人身高的简单表。从逻辑上讲,同一个人有两个条目是错误的。一个人的身高不能不同。每个表都需要一个主键。主键对于每行都是唯一的。它可以是单个列或列的组合。对于身高表,人的名字可以是主键。对于上例中的库存表,(PlayerID, Item Name) 可以是主键。
第二范式(2NF)
让我们重新审视库存示例并存储另一个值,即玩家评分。
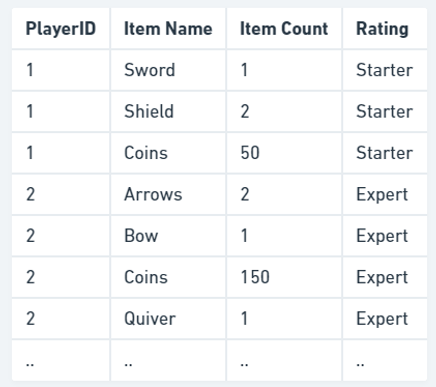
该表遵循第一范式的所有规则。
它有一个主键(PlayerID,Item Name)
没有重复的组
每列只存储一种类型的值
每个单元格仅存储一个值
然而,我们遇到了一些问题:
如果玩家丢失了所有物品,则无法存储他们的评级,因为无法在表中输入任何条目。当然,我们可以添加一个物品计数为 0 的行,但这更像是一种黑客行为。这被称为删除异常。
如果玩家 1 的评级从首发变为中级,我们需要更新所有 3 行的评级。但如果在更新这些值的过程中出现系统问题,玩家的评级就会不知何故同时是首发和中级。这被称为更新异常。
如果我们有新玩家,他们就是新手。但是,由于他们没有物品,我们也无法存储该玩家的评分。这是一个插入异常。
让我们看看物品数量和玩家评级列。物品数量列取决于玩家 ID 和物品名称。因为数量是针对特定用户库存中的物品。但是,评级列仅取决于玩家 ID,与物品名称无关。
我们可以将这些函数依赖关系显示为
{玩家 ID,物品名称} → {物品数量}
{玩家 ID} → {玩家评分}
这种符号表示左边的每个值都与右边的一个值相关联。
确保表几乎总是符合 2NF 的一个简单规则是确保每个非键属性(不属于主键的列)都依赖于整个主键,即不存在部分依赖关系。2NF 的实际定义比这更微妙。但是,这个定义在大多数情况下都有效。对于完整的定义,应该对所有候选键(而不仅仅是主键)遵循此部分依赖规则。
为了使我们的表符合 2NF,我们可以将部分依赖的列移到另一个表中。
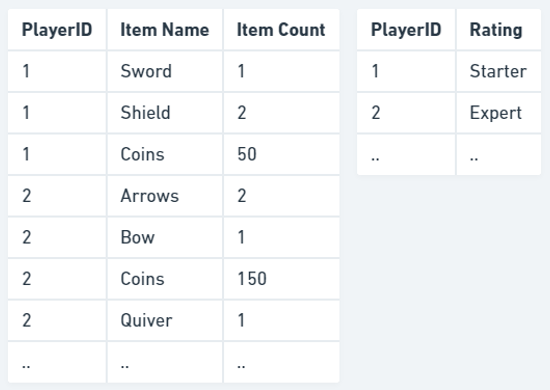
注意:由于 2NF 形式取决于这样一个事实:如果非键属性部分或完全依赖于键(如果键仅为单个列值),则 1NF 中的表将自动变为 2NF。
第三范式(3NF)
让我们再次查看我们在 2NF 部分中创建的 PlayerID、Rating 表。假设我们还想使用以下规则在此表中存储玩家的技能等级:
技能等级 1–3,评级为入门级
技能等级 4–6,评级为中级
技能等级 7–9,评级为专家
该表现在如下所示:
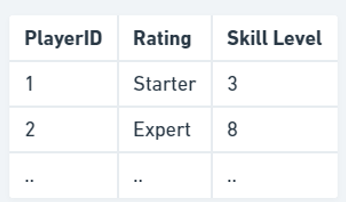
此表符合 2NF,因为此表的主键是 PlayerID,并且评级和技能等级都取决于 playerID。但是,评级仅取决于通过玩家技能等级获得的玩家 ID。评级取决于技能等级,技能等级取决于 playerID,即评级间接取决于 playerID。{PlayerID} → {Player Skill Level} → {Player Rating}如果玩家 1 将其技能等级从 3 升级到 4,则其评级需要从 Starter 更新为 Intermediate。如果在此更新过程中发生故障,则技能等级为 4 的玩家的评级可能为 Starter,这在逻辑上是不正确的。
这个问题的解决方案是将传递依赖列分离到不同的表中。简而言之,每个非键属性都应该只依赖于整个主键。
博伊斯-科德范式 (BCNF)
这是 3NF 的扩展。当表符合 3NF 时,它不符合 BCNF 的情况非常少见。定义表明,对于每个函数依赖关系 A→B,A 应该是一个超级键(可以唯一标识一行的列组合)。
第四范式和第五范式
在大多数情况下,如果我们能够按照第三范式 (3NF) 设计表,那么就可以避免不良关系设计中常见的大多数问题。三种更高的范式:Boyce Codd、第四范式 (4NF) 和第五范式 (5NF) 处理偶尔出现的特殊情况。
第四范式(4NF)
4NF 形式不允许数据库具有多值依赖关系。让我们看一个例子来了解什么是多值依赖关系。
想象一下一个网站,它记录了披萨店销售的披萨种类和送货区域。每个披萨店都可以通过多种方式销售披萨,并且可以送货到多个地点。披萨店和送货地点之间以及披萨店和披萨之间存在一对多关系。但是,披萨类型和送货地点是完全独立的(假设他们将所有的披萨都送到所有地点)。他们销售的每种披萨类型都会为他们送货到的每个送货区域创建一个条目。如果一家披萨店销售 2 种类型的披萨并送货到 3 个地区。他们将在这个数据库中有 6 个条目。
我们可以说
{Pizza Place} ↠ {Pizza} 和,
{ Pizza Place } ↠ {Delivery Area}
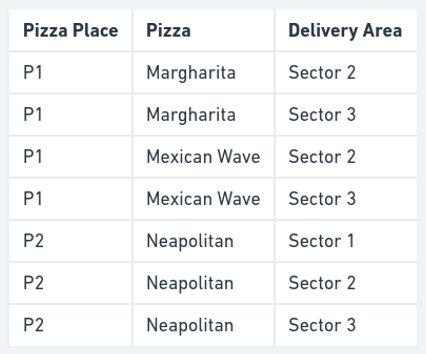
这里,我们被告知三次,披萨店 P2 出售那不勒斯披萨,如果他们决定将 Deep Dish 添加到菜单中,我们将不得不添加多行。每个送货区域各一行。如果未能为其中一个送货区域添加一行,将违反多值依赖关系,{Pizza Place} ↠ {Delivery Area}。
为了消除这种不一致的可能性,我们必须将所提供品种的事实与交货区域的事实放入不同的表格中,如下所示。
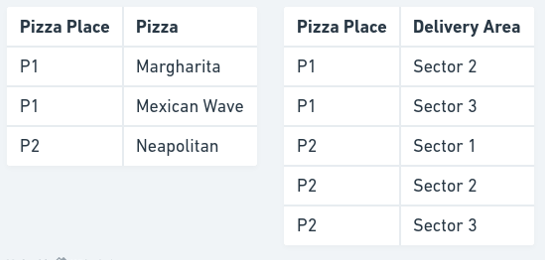
现在,要添加新的披萨类型,我们只需添加一个条目。要添加新的送货区域,我们也只需添加一个条目。
注意:多依赖关系只能发生在具有 3 列或更多列的表中
第五范式(5NF)
让我们通过一个例子来理解这一点。假设有三家冰淇淋公司,Ben&Jerry's、Haagen Dazs 和 Baskin Robins。每家公司都提供以下产品。
Ben&Jerry's:巧克力片、薄荷、软糖Haagen Dazs:薄荷、软糖、香草Baskin Robins:巧克力片、软糖、香草、薄荷
现在,假设有两个人,PersonA 和 PersonB,他们的喜好如下:PersonA:软糖、薄荷、Ben&Jerry's、Baskin RobbinsPersonB:薄荷、香草、哈根达斯、Baskin Robbins
现在,让我们看一下名为“人、冰淇淋公司和口味喜好”的表格。
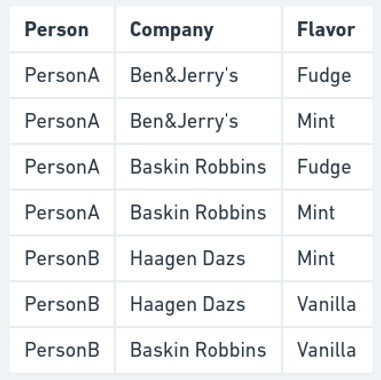
现在,假设 PersonB 最终也开始喜欢 Fudge 口味。我们将必须为此添加两行。(PersonB、Baskin Robbins、Fudge),(PersonB、Haagen Dazs、Fudge)。如果失败,我们只添加一行。这在逻辑上是错误的。如果 PersonB 喜欢 Fudge,并且喜欢 Baskin Robbins 和 Haagen Dazs,那么他们一定喜欢这两种口味的 Fudge。
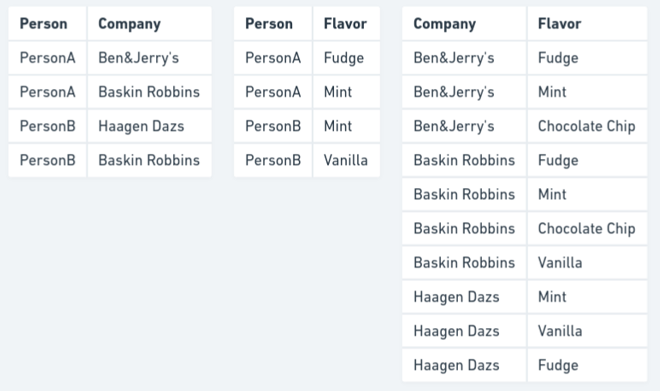
为了避免这种不一致,我们一开始就不应该创建这个表。我们可以简单地将该表拆分为其组成事实,并在需要上述信息时执行连接操作。
过度规范化
过度规范化数据库的主要缺点之一是,它会降低访问数据的查询和事务的性能。这是因为过度规范化会创建过多的表和连接,从而增加磁盘操作的数量、网络流量和内存使用量。此外,过度规范化还会降低索引、缓存和分区的效率。
然而,有时需要达到所需的数据完整性水平。因此,考虑每个数据库的要求并在两者之间找到平衡点非常重要。
小结
在本文中,我们通过示例研究了规范化的不同形式,为什么规范化数据库很重要以及过度规范化可能导致问题。

