时序数据库, 实时数据库, 实时数据仓库, 此三者,差之毫厘,失之千里。若弄不清楚它们之间的差别,实时场景中与客户交流, 就容易出现鸡同鸭讲,驴唇不对马嘴。
最近在很多项目中, 客户点名要求做实时数仓?但是当讨论到细节需求的时候, 用户往往会拿出支持实时数据压缩存储, 支持时间窗口计算, 要求上千个点位的数据支撑, 然后瞬间一口老血喷出, 这不是时序数据库的需求吗?是我弄错了?还是客户弄错了?
带着这个疑惑, 我开始了新一轮的各种Google 和学习, 其间还咨询了当红的GPT,所以才有了这篇文章。
为满足实时响应而生的实时数据库
实时数据库(Real-time Database)是一种能够实时处理数据查询和更新的数据库。这类数据库的目标是在数据产生或更新后尽快地提供数据访问。实时数据库具有低延迟和高并发性能,通常应用于需要实时查询和数据分析的场景,如交通控制系统、在线游戏或者金融交易系统等。
一般而言, 实时数据库因为对响应有极高要求, 所以使用全内存的架构比较多,所以也有不少内存数据库也可以看作是实时数据库。
◆ 实时数据库典型场景
交通控制系统:
需求:交通控制系统需要实时监控交通数据,如车辆位置、速度和路况信息,并根据实时数据进行智能调度和优化。
性能指标:数据读取延迟、数据更新延迟、查询并发能力、分布式事务性能。
在交通控制系统场景中,实时数据库的数据读取延迟、数据更新延迟、查询并发能力和分布式事务性能是关键指标。这些指标能确保实时数据库能够满足高并发、低延迟的实时数据处理需求。
以高铁的列车控制系统来说, 列车时速超过200km/小时, 司机已经难以辨别地面信号进行控制, 所以所有的突发情况, 都需要通过对路况,车辆运行情况等进行实时判断,然后快速做出响应。
在线游戏:
需求:在线游戏需要实时处理大量玩家数据,如角色状态、游戏排行榜和虚拟物品交易等,以保证游戏体验和公平性。
性能指标:数据读取延迟、数据更新延迟、查询并发能力、分布式锁性能。
◆ 实时数据库主要代表产品
Redis:一款开源的、高性能的内存数据结构存储,支持多种数据结构,并可用作实时数据库。
Amazon DynamoDB:一款完全托管的NoSQL数据库服务,提供快速、可靠的性能和无缝扩展能力,适用于实时应用。
Google Cloud Firestore:一款基于Google Cloud的实时数据库,支持实时同步和离线访问。
Apache Cassandra:一款分布式、高性能的NoSQL数据库,适用于实时数据处理和大规模数据存储。
Oracle TimesTen:这是Oracle生产的一款实时数据库, 从名字可以看出来, 性能可以达到10倍速, 市场上主要用于通信,金融行业的实时信用控制等场景。
因IOT而大行其道的时序数据库
时序数据库(Time Series Database)是一种专门用于处理时间序列数据的数据库。时间序列数据是按照时间顺序进行存储和管理的数据,通常包括时间戳和相应的数据值。时序数据库具有高效的数据插入和查询性能,以及良好的数据压缩能力。它们通常用于存储和分析时间序列数据,如金融市场数据、物联网传感器数据或系统性能指标等。
例如下图是某支股票一天的实时走势图,纵坐标是股价,横坐标是时间,这条线就是一条时间序列。可视化之后我们得以直观地观测股票价格。
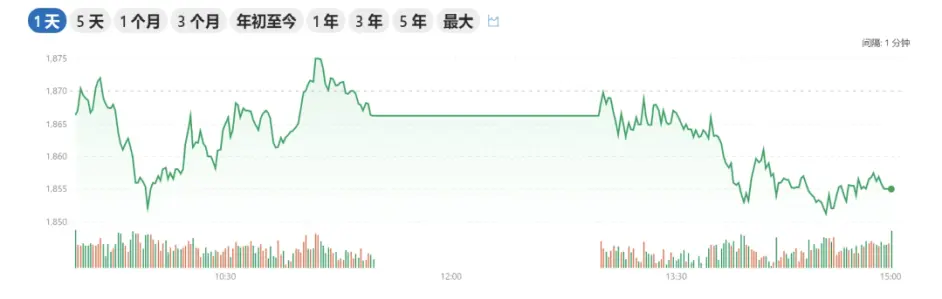
某支股票一天的实时走势图
时序数据库一般是无 Schema 的。类似于关系型数据库中的 table 被成为 度量数据集(measurement)。一个数据集包含如下概念:
1.数据点(point),类似于关系型数据库中的 row;
2.时间戳(timestamp),表征采集到数据的时间点;
3.维度列(tag),代表数据的归属、属性,表明是哪个设备/模块产生的,一般不随着时间变化,供查询使用;
4.指标列(field),代表数据的测量值,随时间平滑波动。
从概念上讲,你可以将 measurement 视为一个SQL表,其中主索引始终是时间。tags和fields是表中的有效列。tags一般采用倒排索引。
◆ 时序数据库典型应用场景
物联网传感器数据分析:
需求:物联网设备产生大量的传感器数据,需要进行实时存储、查询和分析,以监控设备状态、检测异常和优化设备性能。
性能指标:数据插入速度、数据压缩率、时间序列查询速度、时间窗口聚合性能。
在物联网传感器数据分析场景中,需要关注时序数据库的数据插入速度、数据压缩率、时间序列查询速度和时间窗口聚合性能。这些指标能帮助确保数据能够快速地存储和检索,并且占用较少的存储空间。
工业时序数据本身存在的特点。它不仅有传统大数据的特征,如数据量大(海量性)、数据上报频繁(高频性),对实时性、准确性的要求也越来越高。
某风能发电企业有超过 2 万个风能发电机,一个风机有 120 - 510 个传感器,采集频率高达 50 Hz,也就是每个传感器可达到 1 秒 50 个数据点的采集峰值,总量每秒采集 5 亿个点的数据,吞吐量极大,且因为有用数据做监控和报表等需求,实时性要求高。理想的数据库应做到写入及聚合查询低延迟,例如查询某段时间内的风速。此外,这些数据还具有价值密度低的特点,因此也应强调高压缩率,降低企业存储成本。
金融市场数据分析:
需求:金融市场产生大量的实时交易数据,需要进行实时存储、查询和分析,以进行市场监控、交易策略优化和风险管理。
性能指标:数据插入速度、数据压缩率、时间序列查询速度、滚动聚合性能。
◆ 时序数据库主要代表
InfluxDB:一款开源的、高性能的时序数据库,适用于存储和查询时间序列数据。InfluxDB由Golang语言编写,也是由Golang编写的软件中比较著名的一个,在很多Golang的沙龙或者文章中可能都会把InfluxDB当标杆来介绍,这也间接帮助InfluxDB提高了知名度。InfluxDB的主要特点包括:
schemaless(无结构),可以是任意数量的列;
可扩展(集群);
方便、强大的查询语言;
Native HTTP API;
集成了数据采集、存储、可视化功能;
实时数据Downsampling;
高效存储,使用高压缩比算法,支持retention polices;
数据采集支持多种协议和插件:行文本、UDP、Graphite、CollectD、OpenTSDB。
OpenTSDB:基于HBase的分布式开源时序数据库,适用于大规模时间序列数据存储和查询。
这是一个Apache开源软件,是在HBase的基础上开发的,底层存储是HBase,但其依据时序数据的特点做了一些优化。其最大的好处就是建立在Hadoop体系上,各种工具链成熟,但这也是它最大的缺点,因为Hadoop不是为时序数据打造的,导致其性能很一般,而且需要依赖很多组件,安装部署相当复杂。
OpenTSDB采用Schemaless模式,不用预先定义数据结构,因此写入灵活,但每个时间序列只能写入一个采集量,不支持多列写入。每个序列可以被打上多个标签,以方便聚合操作。
总的来讲,OpenTSDB的性能无论是写入还是查询,都很一般,而且系统的稳定性欠佳。但吸引人的是,它支持集群部署和支持水平扩展。
Graphite:一款用于监控和存储实时指标数据的开源时序数据库。Graphite是分布式时序列数据存储数据库,容易扩展,具备功能强大的画图Web API,提供了大量的函数和输出方式。主要功能包括:
存储数值型时序列数据
根据请求对数据进行可视化(画图)
Graphite本身不带数据采集功能,但是你可以选择很多第三方插件,比如适用于collectd、Ganglia或Sensu的插件等。同时,Graphite也支持Plaintext、Pickle和AMQP这些数据输入方式。
Graphite使用了类似RRDtool的RRD文件格式,它也不像C/S结构的软件一样,没有服务进程,只是作为Python library使用,提供对数据的create/update/fetch操作。Google、Etsy、GitHub、豆瓣、Instagram、Evernote和Uber等很多知名公司都是Graphite的用户。
TDengine:这是来自中国的开源软件,由涛思数据研发推出。它不仅是一款时序数据库,而且还提供缓存、消息队列、数据订阅、流式计算等系列功能,是时序数据的全栈技术解决方案。而且它不依赖任何第三方软件,安装包只有1.5MB,使系统设计、安装、部署和维护都变得极为简单。

为满足实时业务分析和决策而产生的实时数据仓库
实时数据仓库(Real-time Data Warehouse)是一种能够实时获取、存储和分析数据的数据仓库。与传统数据仓库不同,实时数据仓库支持实时数据处理和实时数据分析。实时数据仓库通常包含一组工具和技术,如数据集成、数据存储和实时分析引擎等。这类数据仓库适用于需要快速分析和决策的场景,如实时个性化推荐、金融风险管理或物联网分析等。
◆ 实时数据仓库典型场景
实时数据仓库典型场景 - 实时个性化推荐:
需求:实时个性化推荐系统需要实时获取用户行为数据,如浏览记录、购买记录和评价信息,并进行实时分析和模型更新,以提供精准的个性化推荐。
性能指标:数据导入延迟、数据查询延迟、实时聚合性能、实时模型更新速度。
实时数据仓库典型场景 - 金融风险管理:
需求:金融风险管理系统需要实时获取金融交易数据和市场数据,并进行实时分析和监控,以及时发现和预防潜在风险。
性能指标:数据导入延迟、数据查询延迟、实时报表生成速度、实时数据挖掘性能。
对于实时个性化推荐场景,实时数据仓库需要具备较低的数据导入延迟、数据查询延迟、实时聚合性能和实时模型更新速度。这些指标能确保实时数据仓库能够支持实时数据处理和分析,从而为用户提供精准的个性化推荐。
◆ 实时数据仓库主要代表
Google BigQuery:一款完全托管的、高性能的实时数据仓库,支持实时数据处理和大规模数据分析。
Amazon Redshift:一款完全托管的、高性能的数据仓库服务,支持实时数据处理和分析。
Snowflake:一款基于云的数据仓库平台,支持实时数据处理、分析和机器学习。
Azure Synapse Analytics:一款基于Microsoft Azure的实时数据仓库服务,提供实时数据处理和大规模数据分析能力。
Doris:Doris 是一个基于 MPP(大规模并行处理)架构的高性能分析型数据库,由百度公司开发。它具有高性能、低延迟、易扩展、高可用等特点。适用于实时数据仓库、报表分析和大数据分析场景。
StoneData:杭州石原子科技生产的实时数据仓库产品,提供实时数仓建设能力,卓越的单表和多表查询性能,百亿级多表数据查询秒级结果返回。
同时也有些其他开源技术和框架可以用于构建实时数据仓库。例如:
Apache Flink:一款分布式、实时的数据处理框架,支持实时数据流处理和批处理。虽然 Flink 并非国内独立开发的项目,但它在国内有很大的用户群和贡献者社区。
ClickHouse:一款分布式、列式的数据库,适用于实时数据分析和报表生成。ClickHouse 虽然是由俄罗斯的 Yandex 公司开发的,但在国内也有很多用户和贡献者。
三者之间的联系与区别
数据类型和处理:时序数据库主要关注时间序列数据,而实时数据库和实时数据仓库则关注实时数据处理和分析。实时数据库主要用于实时查询和数据更新,而实时数据仓库则是在数据仓库的基础上增加了实时数据处理和分析的能力。
应用场景:时序数据库适用于处理和分析时间序列数据的场景,如物联网数据分析和金融市场分析等。实时数据库适用于需要实时查询和数据更新的场景,如交通控制系统和在线游戏等。实时数据仓库适用于需要实时获取、存储和分析数据的场景,如实时个性化推荐和金融风险管理等。

技术架构:时序数据库、实时数据库和实时数据仓库在技术架构上也有所不同。时序数据库通常使用专门针对时间序列数据的数据结构和存储技术;实时数据库则关注低延迟和高并发性能;实时数据仓库则包含数据集成、数据存储和实时分析引擎等组件。
数据分析和查询能力:时序数据库主要针对时间序列数据的查询和分析,例如滚动聚合、时间窗口查询等。实时数据库注重实时查询和数据更新,例如实时查询在线用户的信息或实时更新游戏分数等。实时数据仓库则提供实时数据处理和分析能力,例如实时聚合、实时报表和实时数据挖掘等。
数据延迟:时序数据库通常对数据延迟的要求较低,因为其主要关注时间序列数据的长期趋势和模式。而实时数据库和实时数据仓库则注重数据的实时性,尽量减小数据产生和更新到数据访问之间的延迟。
扩展性:时序数据库、实时数据库和实时数据仓库在扩展性方面也有不同的考虑。时序数据库通常关注数据的高效插入和查询,因此在分布式系统中可能采用数据分区和数据复制等技术。实时数据库则注重低延迟和高并发,可能采用分布式事务和分布式锁等技术。实时数据仓库则关注实时数据处理和分析的扩展性,例如采用流式计算框架和分布式存储等技术。
写在最后
通过对实时数据库,时序数据库,和实时数据仓库的分析, 我想大家会对这三种数据库的使用场景有了更进一步的了解, 三者之间, 有相通之处在于, 都是和时间紧密耦合,但是针对不同的细分场景, 在细分场景下由于需求有细微差异, 从而导致了不同的技术路线。当然,之后随着技术发展和用户需求的变化, 肯定还会出现更多更新的融合场景, 也可能会有更多的新产品出现。

