时序数据库是一种专门面向时序数据进行优化的数据库管理系统。
主要用于处理带时间标签(按照时间的顺序变化,即时间序列化)的数据,带时间标签的数据也称为时间序列数据,具有下面特征之一的时序型特征的数据可以考虑使用:
大量高性能的写入;
聚合实时分析;
数据实时可视化分析;
数据量巨大,需要压缩存储;
历史数据需要高效地删除;
2022年12月时序数据库排行榜
https://db-engines.com/en/ranking/time+series+dbms

业界常见时序数据库
1、 Influxdb
在 https://www.influxdata.com/ 可以看到有三个产品:
InfluxDB Cloud 云模式。
InfluxDB OSS 独立部署集群版。
InfluxDB OSS 独立部署单机版,开源。https://github.com/influxdata/influxdb 官方数据单机性能27W,
star 24.6K

https://awesome.influxdata.com/docs/part-1/introduction-to-influxdb/
TICK 架构 是 InfluxData 平台的组件的集合首字母缩写,该集合包括 Telegraf、InfluxDB、Chronograf 和 Kapacitor。
TICK 架构以及各组件分工情况如图所示:
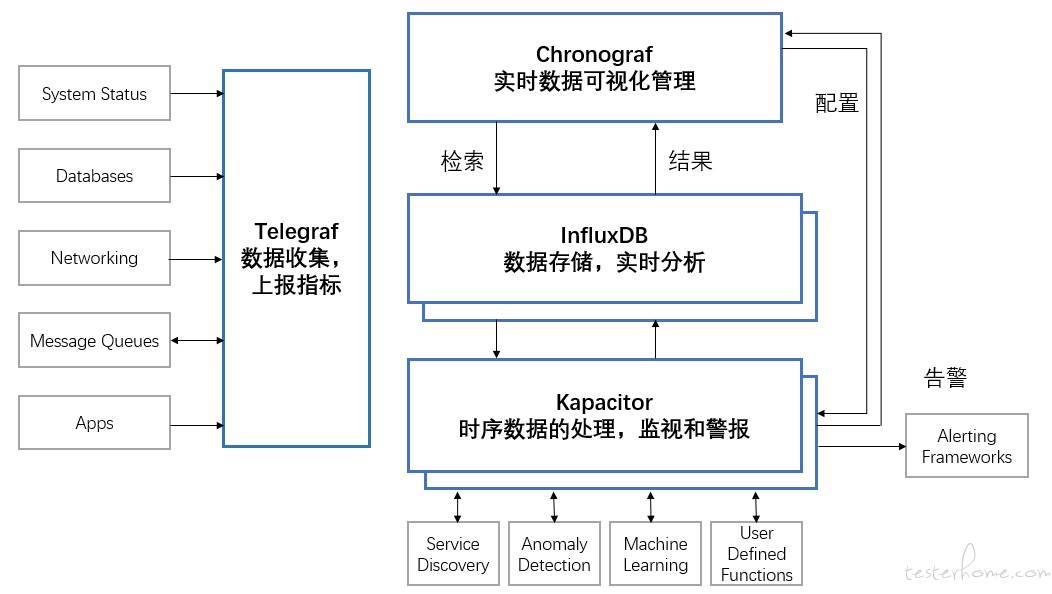
目前业界大厂(阿里、360...)的做法基本上是基于influxdb做二次开发, 实现分布式的集群方案。
部分互联网公司会基于proxy方案实现高可用和容灾能力
相关开源的:
https://github.com/influxdata/influxdb-relay
https://github.com/shell909090/influx-proxy
https://github.com/chengshiwen/influx-proxy
https://github.com/Qihoo360/influx-proxy https://www.infoq.cn/article/IcvfEmGM8WzS8PO72ZwR
2、Kdb+
1998年,Kx Systems(https://kx.com/)发布了kdb。
Kx Systems在2003年发布了64位版本的kdb+。
它是用q语言写的。Kdb+是为处理金融、物联网等领域的大量时间序列数据而构建的。
kdb+时间序列数据库是世界上最小(只有几十KB)和最快的。它的单一集成平台使其非常有效地分析超大型数据集,并加快了基于我们的高性能核心技术构建的Kx解决方案的开发和部署(官方描述)。
特点:
内存数据库(In Memory Database),将数据放置在内存中
解释型语言(Interpreted)
有序列表(Ordered Lists), 实现高速处理数据的关键,区别于传统数据库。
赋值顺序(Evaluation Order)
面向表编程(Table Oriented)
面向列编程(Column Oriented)
强类型(Types)
3、Graphite
根据官方文档(http://graphite.readthedocs.io/en/latest/overview.html#about-the-project),它只做两件事:
存储数字时间序列数据
呈现此数据的图形
4、Prometheus
Prometheus是由SoundCloud开发的开源监控报警系统和时序列数据库(TSDB)。Prometheus使用Go语言开发,是Google BorgMon监控系统的开源版本。
根据其官方文档(https://github.com/prometheus/prometheus/blob/master/README.md),Prometheus因具备如下的特征而得以将自己与其他监控系统区别开来:
多维数据模型,其时序数据由指标名称和键/值维度定义;
灵活的查询语言;
自治的单服务器节点,不依赖于分布式存储;
通过HTTP之上的pull model进行数据收集;
时间序列数据推通过中介网关传送到其他数据目的地和存储介质;
服务发现和静态配置来发现目标节点;
对图表和仪表板的多种支持模式;
垂直和水平上支持Federation。
开源 https://github.com/prometheus/prometheus
star 45.8K

5、 TimescaleDB
https://www.timescale.com/
基于时序优化
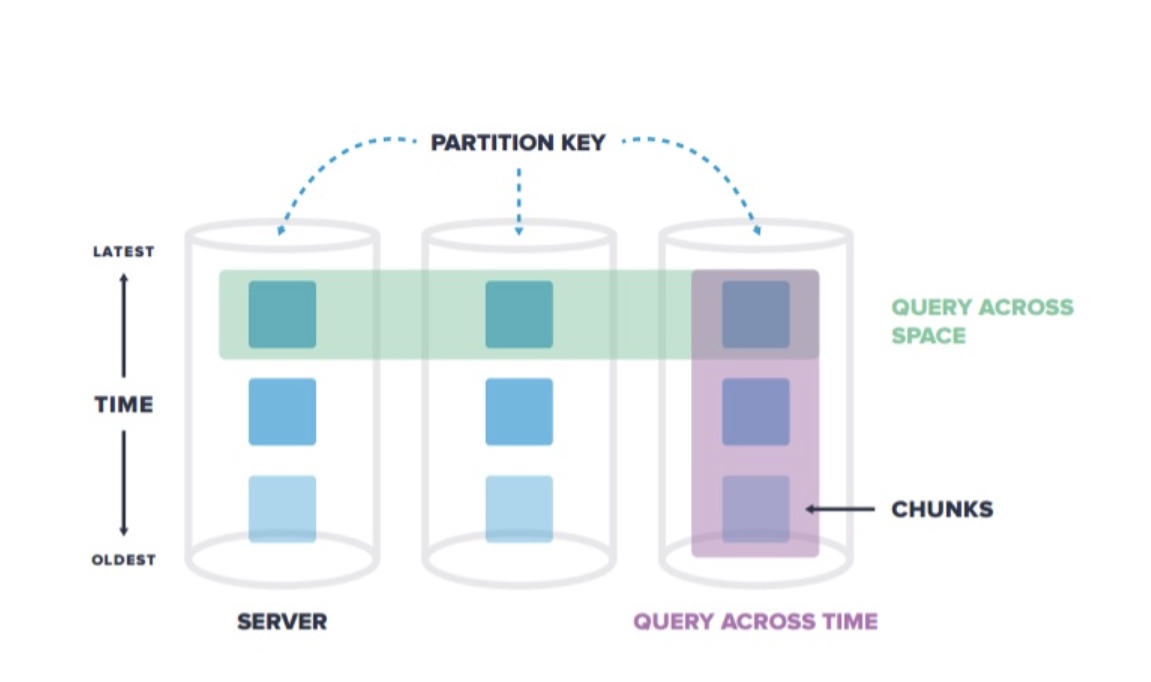
自动分片(自动按时间、空间分片(chunk)),自动调整 CHUNK 的大小
全 SQL 接口
支持垂直于横向扩展
支持时间维度、空间维度自动分区。空间维度指属性字段(例如传感器 ID,用户 ID 等)
支持多个 SERVER,多个 CHUNK 的并行查询。分区在 TimescaleDB 中被称为 chunk。
内部写优化(批量提交、内存索引、事务支持、数据倒灌)。
内存索引,因为 chunk size 比较适中,所以索引基本上都不会被交换出去,写性能比较好。
数据倒灌,因为有些传感器的数据可能写入延迟,导致需要写以前的 chunk,timescaleDB 允许这样的事情发生(可配置)。
利用已有的 PostgreSQL 特性(支持 GIS,JOIN 等),方便的管理(流复制、PITR)
6、DolphinDB
DolphinDB是由浙江智臾科技有限公司研发的一款高性能分布式时序数据库
7、Monarch
来自Google的闭源内存时序数据库,全局配置,靠分zone来实现大规模的监控管理。
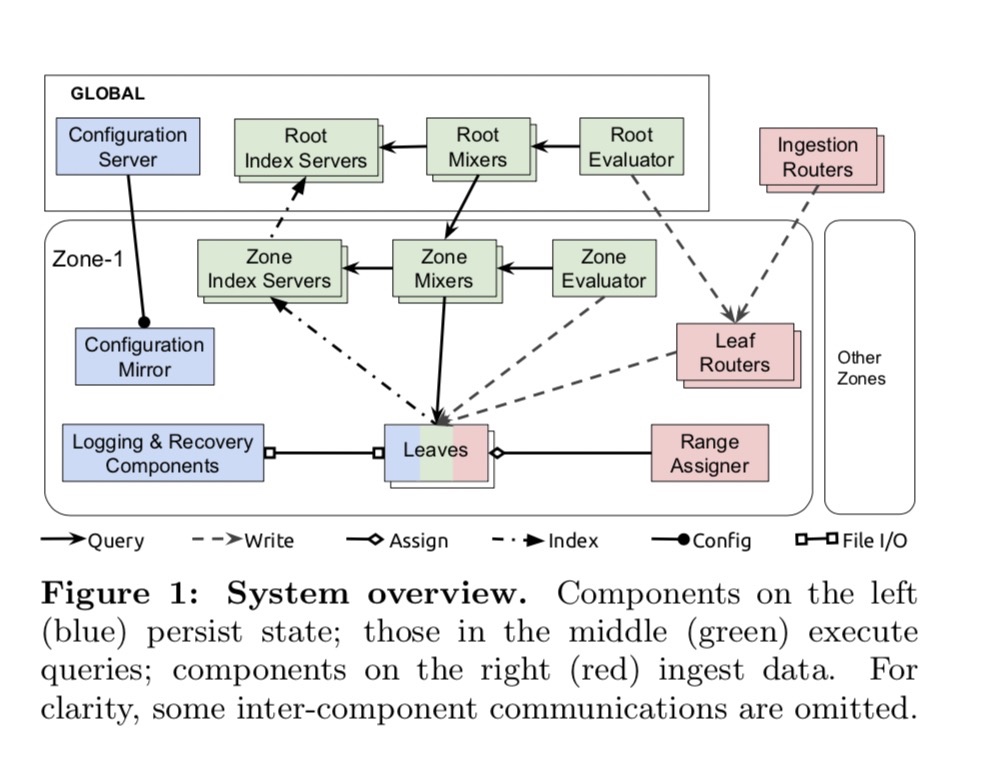
参看:时序数据库 | Monarch: 谷歌的内存时序数据库
8、beringei
来自facebook的开源内存时序数据库。
https://github.com/facebookarchive/beringei
star 3.1K
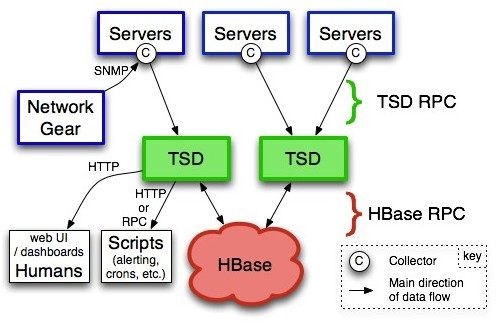
9、 OpenTSDB
来自 SoundCloud 开源
https://github.com/OpenTSDB/opentsdb
star 4.8K
基于Hbase数据库作为底层存储,向上封装自己的逻辑层和对外接口层。这种架构可以充分利用Hbase的特性实现了数据的高可用和较好的写入性能。但相比Influxdb,OpenTSDB数据栈较长,在读写性能和数据压缩方面都还有进一步优化的空间。 整体架构如下:
10、 涛思数据 TDengine
来自 涛思 开源
https://github.com/taosdata/TDengine
star 20.2K
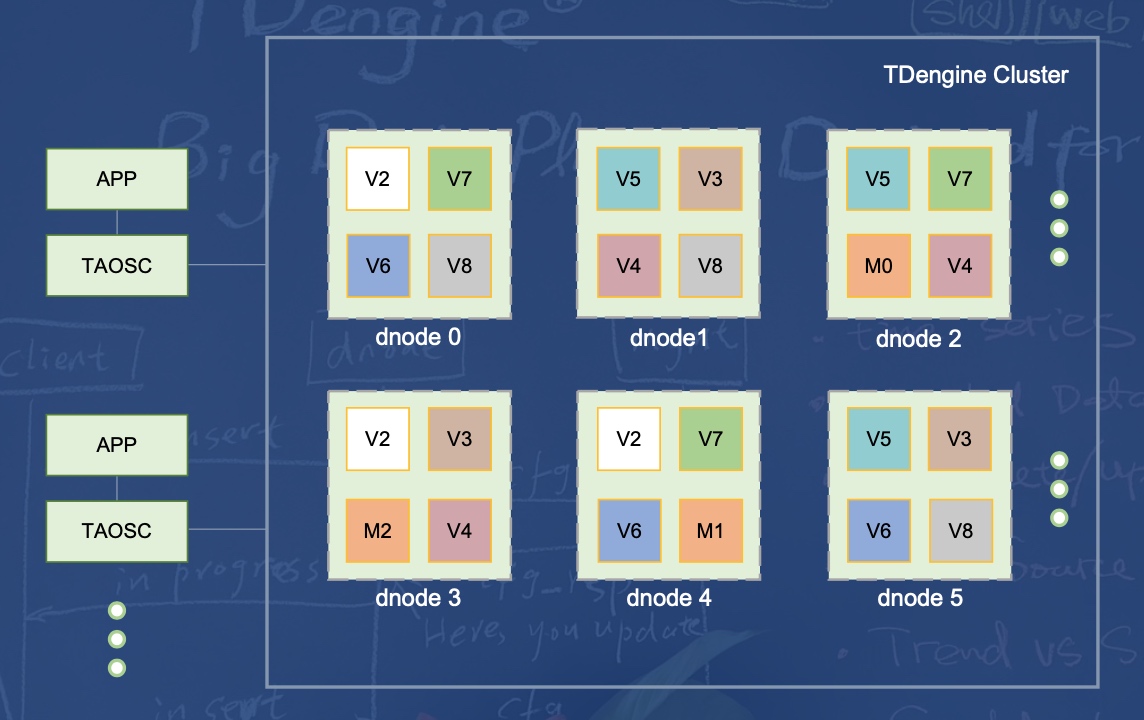
一个采集点是一个表,根据表维度做分片,根据时间维度做分区。
每个物理节点上可有多个分片,一个分片的副本分布在不同的机器上。
meta data 协调分片,以及存储存储表、超级表、节点信息。
11、阿里云 时序数据库 TSDB
来自 阿里云 闭源
https://help.aliyun.com/product/54825.html
自研+提供influx版本

和官方集群版描述的一样,任意数据节点可以承接流量然后通过meta节点来协调,转发部分请求到其他的数据节点,
最后汇总结果信息,将最终结果返回给client。
12、 腾讯云 CTSDB
来自 腾讯云 闭源 基于influx版本自研
https://cloud.tencent.com/product/ctsdb

和官方集群版描述的一样,任意数据节点可以承接流量然后通过meta节点来协调,转发部分请求到其他的数据节点,最后汇总结果信息,将最终结果返回给client。
13、 GaussDB(for Influx)
来自 华为云 闭源
https://www.huaweicloud.com/product/gaussdbforinflux.html
基于influx版本自研
http://www.opengemini.org/(计划开源)
14、 Apache Druid
来自 Apache 开源, 更侧重于多元分析
https://github.com/apache/druid
star 12.2K
15、 饿了么 LinDB

broker更像一个proxy,storage是数据节点,并且通过etcd作为媒介进行沟通,broker收到请求后根据分片配置。
生成执行计划,然后在etcd里面生成查询任务,数据节点watch etcd的task相关的key进行查询并更新task状态机。
整个task的执行都是etcd进行异步处理的,有点儿像k8s的调度策略,broker最终汇总结果返回给client。
InfluxDB 更适合的用途:
需要 logging 监控;
需要精细的时间尺度;
需要 TICK 生态的易用性;
LinDB 更适合的用途:
需要查询速度更快;
需要解决海量数据的时序场景;
对时序数据时间精度不敏感,比如监控领域;
总结
Influxdb在各个大云厂商里面已经被广泛使用,并且社区活跃度比较高,产品的稳定性经过了充分的验证,值得推荐。
主要风险为,influxdb官方只开源单机版本,分布式版本是闭源的,各大厂商都自行扩展了集群版本。

