数据仓库系列文章的第十篇,本文关键词:数据仓库;累积快照事实表;日期分区表
在文章《扫盲系列(9):数据仓库实践之表的分类》中,我们对数据仓库中的表做了详细的分类和介绍。本文将介绍累积快照事实表的实现方式。
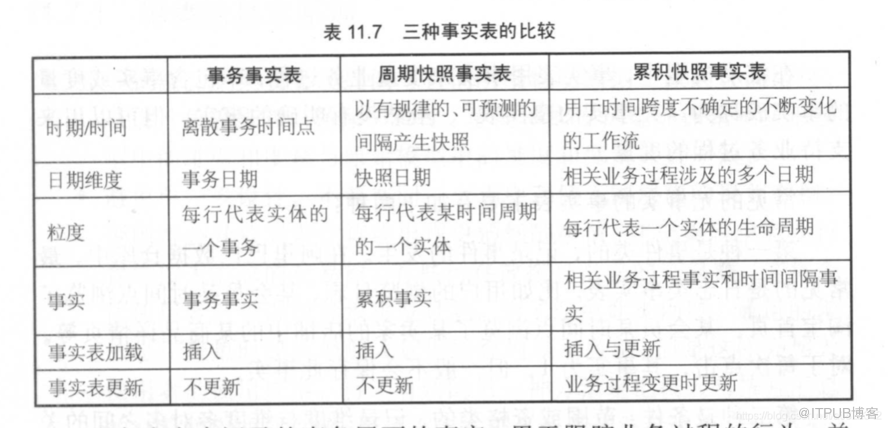
三种事实表的比较
什么是累计快照事实表
首先来快速回顾一下什么是累积快照事实表。
在数据仓库中,事实表是存储与业务对象相关的数据的主表。根据数据的生命周期和特点,数据仓库中的事实表可以分为不同类型,主要包括事务事实表、周期快照事实表和累积快照事实表。
累积快照事实表是指对业务对象生命周期内的数据进行累积统计的事实表,例如订单状态表。这类事实表通常包含多个时间字段,用于记录业务对象生命周期中的关键时间点,也包含各种状态度量,例如订单数量、金额、状态等。通常,每个业务对象只会对应一个记录,但是该记录会被随时更新。
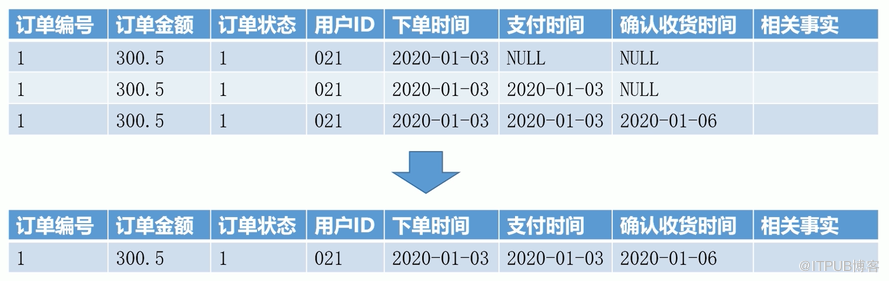
累积快照事实表示
实现方式一
使用日期分区表实现累积快照事实表是一种比较常见的实现方式之一。通过日期分区表实现累积快照事实表时,每个分区代表了一个时间段,通常以天为单位。每天的分区存储昨天的数据以及当天的增量数据的结果,并且不断累积所有的历史状态。
日期分区表实现累积快照事实表的优点在于方便实现和维护,同时也方便数据查询和分析。如果对查询性能要求不是很高、数据量不是很大的情况下,这种实现方式会很有效。
数据量增大时,使用这种实现方式会导致全量表膨胀,并且会存储大量永远不更新的冷数据,严重影响性能。因此这种实现方式更适合于数据量较少的情况,对于数据量较大的场景,需要结合其他技术手段进行优化。
需要注意的是,为了保证查询的效率,应该合理定义分区策略,并对数据进行定期的归档和清理,以避免分区过多、分区无序、分区重叠等问题。同时,也需要对分区表建立适合的索引,以提高查询性能。
实现方式二
使用日期分区表实现累积快照事实表的另一种方式是,通过推测数据的最长生命周期来分区,周期内的数据存储在分区表中,周期外的冷数据存储到归档表中。
这种实现方式相比于全量记录的方式,可以避免存储冷数据的开销,提高存储利用率,并且降低查询时的数据量,从而提高查询效率。
但是,这种方式需要在实际业务中推测数据的最长生命周期,这可能会导致一些数据丢失或记录不全的情况发生,需要仔细权衡业务需求和数据的可靠性。另外,由于需要保留多天的分区数据,存储消耗依然较大,需要对存储进行适当的优化。
需要注意的是,为了保证查询的效率和准确性,应该对分区定义进行科学合理的优化,并对数据进行定期的归档和清理,以避免数据的过度冗余。同时,也需要对分区表建立适合的索引,以提高查询性能。综合考虑,这种实现方式更适合于数据量更大、业务需求更复杂的场景。
实现方式三
使用日期分区表实现累积快照事实表的另一种实现方式是,以业务实体的结束时间作为分区的依据,每天的分区存放当天结束的数据。设计一个时间非常大的分区,例如9999-12-31,存放截止当前未结束的数据。这样,已结束的数据存放到相应分区,而存放未结束数据的分区数据量也不会很大,ETL性能好。
通过这种方式,可以保证数据的全局唯一性,无存储浪费。同时,这种方案还可以通过使用其他相关业务系统的结束标志或最长生命周期时间来解决无法标识业务实体结束时间的问题。
需要注意的是,业务系统可能无法标识业务实体的结束时间,可以用其他相关业务系统的结束标志作为此业务系统的结束,也可以使用最长生命周期时间或前端系统的时间归档时间。因为将数据按照业务实体的结束时间进行分区,而不是按照时间进行分区,因此需要在设计时仔细考虑业务实体生命周期的定义。同时,对于某些没有严格意义的业务实体,可能需要进行额外的处理来保证数据的正确性。
此外,需要注意合理定义数据的归档时间,以保证分区表的性能和存储效率。同时,也需要对分区表建立适合的索引,以提高查询性能。综合考虑,这种实现方式是比较优秀的一种解决方案,特别是对于需要处理大量历史数据的场景。

