AI正在颠覆传统数据架构,Databricks认为LTAP是解决之道

在近期举行的“数据与AI峰会”上,Databricks发布了湖式事务分析处理(LTAP)架构,该架构旨在将运营和分析工作负载统一到单一数据副本上。
此次发布旨在解决Databricks认为企业正面临的一个日益严峻的挑战:让AI应用能够同时访问运营数据和分析数据,而无需依赖日益复杂的数据管道。
传统架构通常依赖运营数据库、分析平台和数据管道协同工作——但它们仍是彼此独立的系统。
据Databricks称,随着AI代理和应用对事务数据和分析数据访问速度的要求越来越高,这种方法正变得越来越难以实现。
“几十年来,复杂的数据基础设施一直是团队被迫承受的负担,”Databricks联合创始人兼首席执行官Ali Ghodsi表示。“随后,智能代理应运而生。短短数月内,企业的‘ workforce’实际上翻了一番,只不过这些‘ workforce’并非人类。智能代理编写代码、发起调用并执行循环的速度,是人类团队无法企及的。支撑上一代计算的基础设施,如今已成为无人可承受的瓶颈。LTAP消除了这一瓶颈。”
在接受BigDATAwire采访时,Databricks Lakebase和Neon产品管理总监Brian Clark解释了该公司为何认为,运营系统与分析系统之间的更紧密集成已成为AI时代的必要条件,而不仅仅是一种架构偏好。
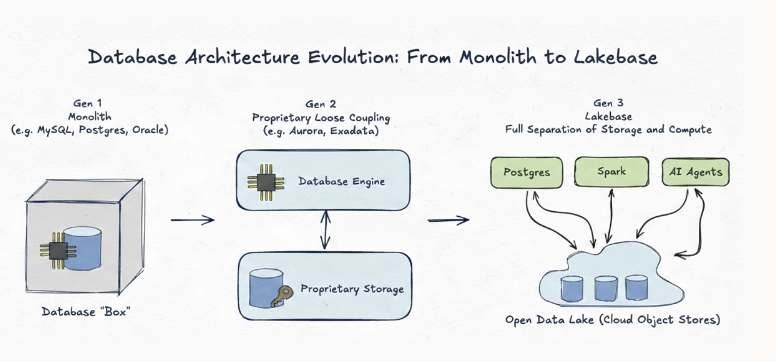
在漫长的历史中,Databricks一直专注于分析和数据工程。最近,公司将大量精力投入到AI领域。然而,运营数据库一直处于平台之外。它们通常由第三方系统处理,这些系统通过管道和集成将数据输入分析环境。
Clark表示,随着客户将AI应用投入生产,Databricks越来越意识到这种模式的局限性。
“如果数据库始终存在于合作伙伴的领域中,这种模式是行不通的,”Clark说道,他指的是运营系统与分析系统之间所需的更紧密集成。
据Clark介绍,随着企业从仪表盘和批处理分析转向生产级AI工作负载,运营数据库的重要性日益凸显。为此,Databricks通过更深入地拓展应用基础设施领域作出回应。该公司推出了服务级别协议(SLA)、机器学习端点以及专门用于支持运营用例的功能。
“整个技术栈正在成为生产环境,”Clark说道。
(来源:Databricks)
因此,Databricks得出结论:运营数据库不能再仅仅作为一个松散连接的外部组件存在。相反,它们需要成为更广泛平台架构的一部分,特别是随着AI应用越来越依赖事务数据和分析数据。
挑战不仅仅在于运营系统和分析系统是分离的,更在于连接它们的复杂性日益增加。
“管道等组件往往会生成大量用于数据传输的管道,”Clark说道。
当企业需要在运营数据库、分析平台、机器学习系统及其他应用程序之间传输数据时,这些连接的管理难度会日益增加。
据Clark介绍,随着AI加速开发周期,这一挑战变得更加严峻。
“当你将数据从Lakebase传输到湖仓,再回传到其他系统或机器学习管道时,就可能会面临各种不同的情况:当开发人员介入并加速开发进程时,数据模式会发生变化,数据管道会中断,而且中断的速度比以往更快,”Clark说道。
Databricks认为,LTAP可以通过最大限度地减少不同系统之间数据迁移的需求来帮助解决这些问题。Clark表示,目标是创建“无需管道的默认模式”。
“我们将提供无需管道的默认模式。例如,这些数据会自动存储在你的Lakehouse中,你无需进行任何管理操作,”Clark说道。
Clark表示,AI 代理还催生了新的基础设施需求,包括在隔离的数据库环境中运行的能力。
“代理非常喜欢分支功能,因为这本质上是一个隔离的环境,”Clark说道,“你可以从数据库中创建一个分支,这实际上是一个完整的副本。”据Clark介绍,这些隔离的环境使代理能够在不影响生产工作负载的情况下进行实验。
Clark认为,AI可能会从根本上改变企业对数据基础设施的认知。
他提到了与一位客户的一次对话,该客户正在评估Lakebase的跨云灾难恢复能力。虽然该功能最初是为增强弹性而设计的,但客户发现了另一个用例:将数据库迁移到更接近可用且价格实惠的GPU的位置。
“他们说,这太完美了,因为我们正在寻找廉价的GPU,”Clark说道,“有时其他云平台能提供价格低廉且可用的GPU资源。因此,我们希望能够将数据库迁移到GPU价格最低的地方。”
这次对话凸显了AI如何重塑基础设施决策。没有谁想要将数据库束缚在单一云环境中,企业越来越希望拥有根据计算资源的可用性灵活迁移工作负载的能力。
“我认为,正因如此,情况会变得更加灵活,”Clark说道,“如果你无法迁移到GPU价格低廉的地方,要么就得花更多钱,要么就只能放弃使用它们。”

