无论是传统运维还是智能运维,最核心的都是经验
三十年期我们用Oracle数据库的时候是盲目用,那时候用得就很不好,甚至把重启数据库都当成一件恐怖的事情来做。如果不是高手,都不敢轻易重启数据库,生怕数据库重启后起不来了。当时江湖中这种传闻也是很多的,我有一次重启了二十多分钟还没起来,只能眼巴巴地看着空空荡荡的日志,最后一次日志输出还是十多分钟之前。后来我对Oracle了解一些了,知道了每一行启动日志的含义,也就知道了当时系统在清理临时段,因为数据库好几年没重启过了,所以打扫工作很耗时。再后来了解了REDO和CHECKPOINT的原理,知道数据库重启时一个没风险的活,就再也不怕去给客户重启数据库了。
运维最大的恐惧来自于未知,你不理解数据库的原理,没有相关的运维经验,那么使用数据库还是一件十分恐怖的事情。最大的问题是心里没底,当系统出问题的时候无法定位问题,解决问题。后来有了MOS,一切好了很多,大多数问题借助MOS都能搞定了。
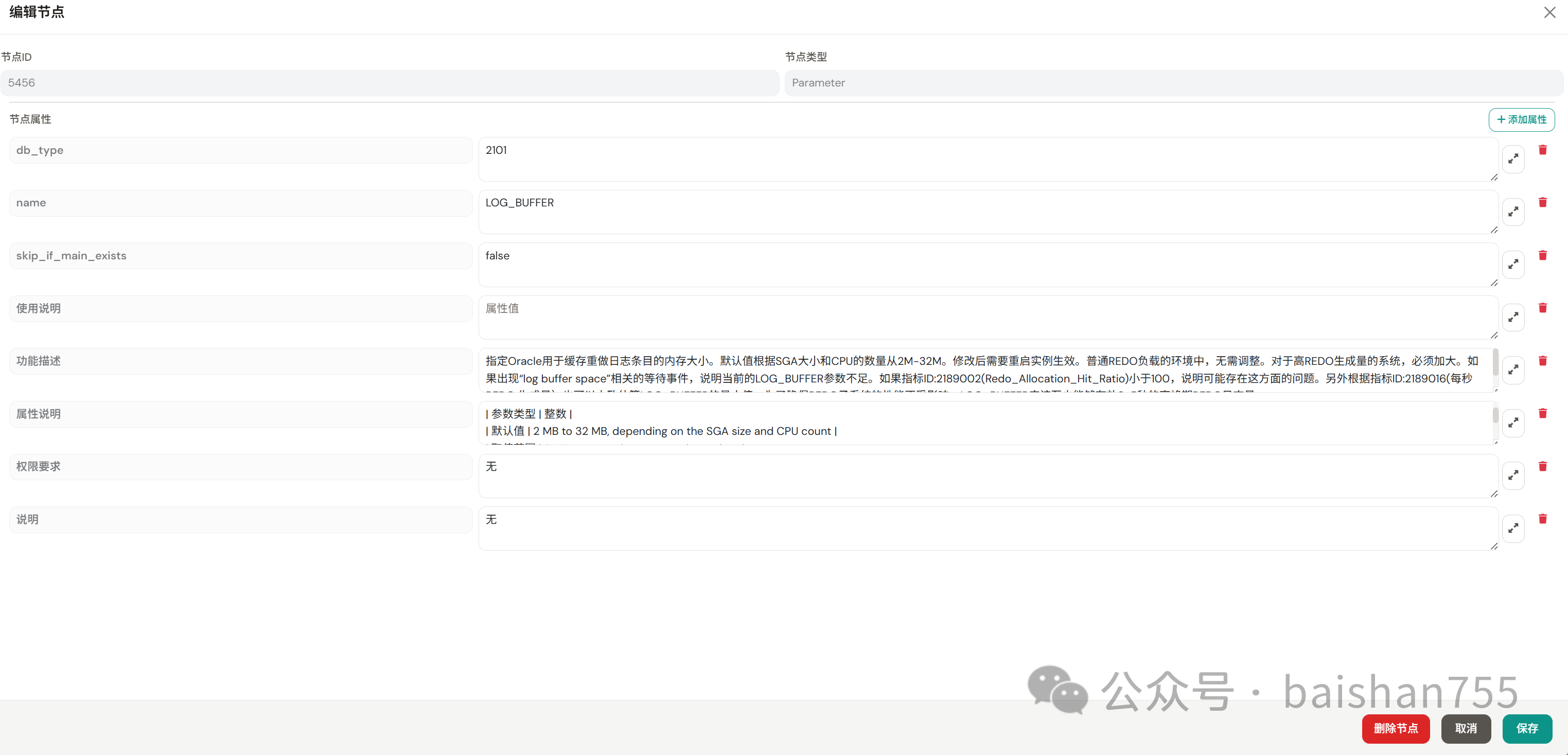
前几天我说我在标注国产数据库的运维知识,怎么标注呢?实际上说简单也简单,说复杂也够复杂。就像我标注的Oracle LOG_BUFFER参数这个案例,仅仅从官方文档中把Oracle关于LOG_BUFFER的参数描述复制到这个地方是不够用的,因为这里仅仅包含了“知识”,知识是正确而无法直接用于运维实践中的东西。我们必须把“经验”标注进去,才真正有用。“经验”不一定百分百准确,甚至还可能有一定的局限性,远没有“知识”的准确性高,但是经验能发挥的作用远超“知识”。在关于LOG_BUFFER的标注中,不仅要列出官方的知识,还要把LOG_BUFFER与log buffer space 等待与每秒REDO生成量指标之间的关系讲清楚,AI才能真正理解这个参数的定义与使用方法,才能在AI诊断中准确地对与此参数相关的问题分析清楚。
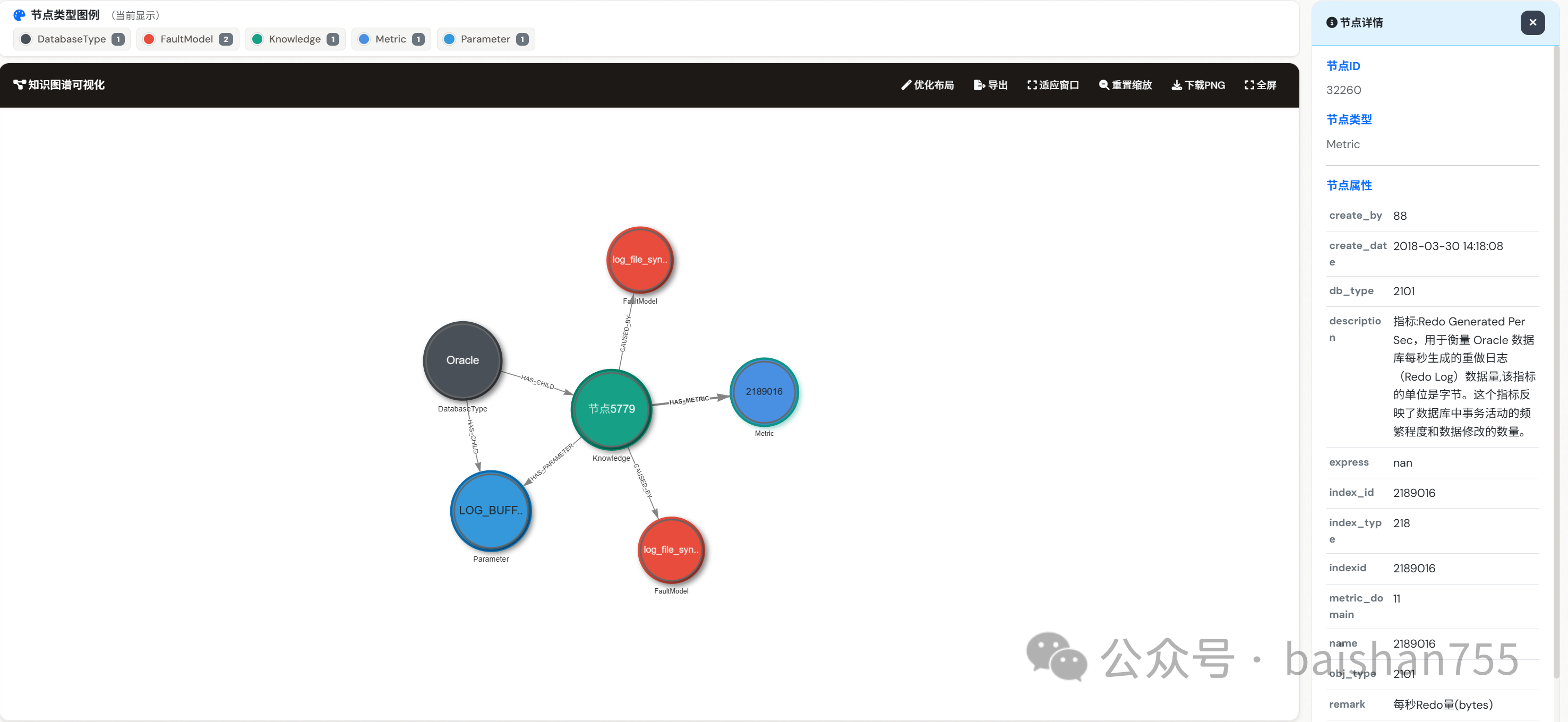
这是一个系统工程,Oracle数据库的关键参数有200多个,指标有四五百个,等待事件有1500左右,如果能把这些知识都标注准确了,那么对Oracle数据库的诊断分析能力也就相当高了,超越某些中等水平的专家应该还是可能的。如果只做Oracle还好,如果说还要做20多款国产数据库,那么这个工作量就是很庞大了。目前我们标注过的实体节点已经超过6万个,还没有覆盖所有的国产数据库。
当然最后AIOPS的能力也受限于标注知识的团队的整体能力,如果能力不足,最后做出来的产品能力也就有限了。这也是AI Machine Labs才不到50人,还没推出任何产品,就能融到20亿美金,估值一下子高达120亿美金的主要原因。
目前在进行国产库的知识图谱的标注的时候,我们遇到了很多瓶颈,那就是国产数据库的知识不透明,经验积累极少,从基层运维案例中提炼知识和经验的成本太高。等国产数据库厂商搞出自己的MOS不知道要猴年马月了,甚至我都看不到在未来的5-10年里,某个国产数据库厂商能打造出一款水平达到20年前Oracle Metalink水准的知识库。依托生态可能是一条更好的路子,去年这一年我也不断在和各个数据库厂商沟通,能不能一起来做这件事。虽然略有成果,但是还是太少。要想打造出与商业产品类似的知识库,光凭我们这种合作是远远不够的。在中国,缺乏这方面的战略投资,因此在这个领域无法做得更好。
目前一切只能依托企业用户自身和第三方合作伙伴,靠着企业用户花钱来做这些事情了。但是地主家也没有余粮的时候,想让企业在这方面花大钱也是不现实的。前阵子一个客户说他们手头有某国产数据库的1万多个故障告警的案例,从中应该能够提取出不少运维经验,不过这个提取谁来做?谁出钱,做出来产权归属是什么?往下一深谈,问题还是一堆。有朋友感叹道:只能让时间来解决了。我的观点有些不同,没有钱,光耗时间,是解决不了这个问题的。

