KaiwuDB 3.0发布:以“开物成务”之器,洞见数据未来

“开物成务,冒天下之道,如斯而已者也。”
浪潮KaiwuDB副总经理陈磊在3.0产品发布会的开场,引用了这句源自《易经》的哲言,它揭示了这款产品的初心与雄心:通过洞见和驾驭万物运行的规律,来成就事业的根本法则。在数据洪流奔涌的物联网时代,掌握规律的前提,是拥有能够管理和理解海量数据的工具。这正是KaiwuDB作为一款面向AIoT场景的分布式多模数据库的使命所在。
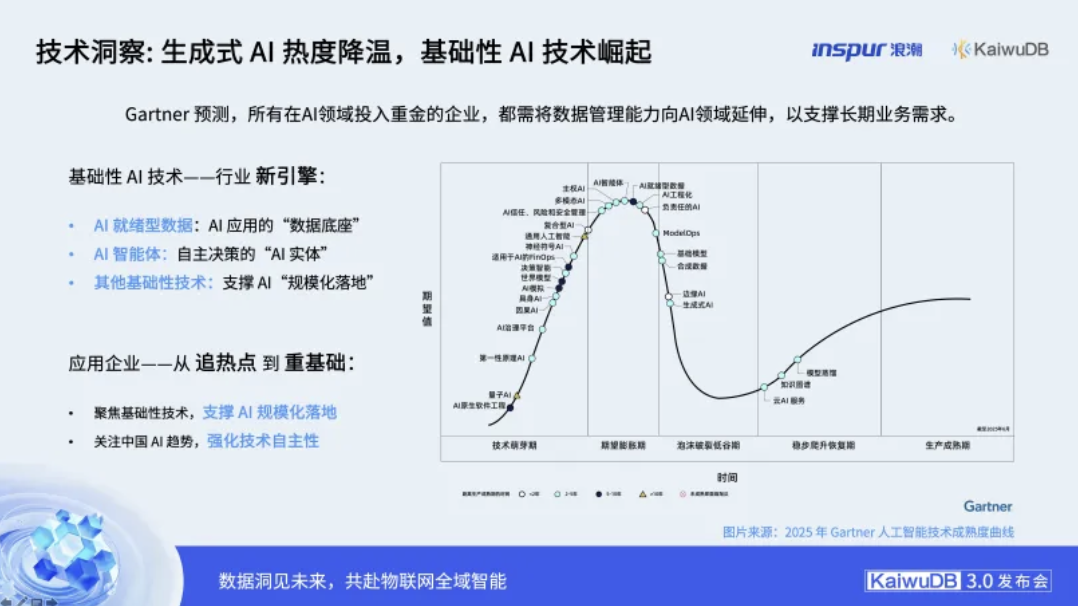
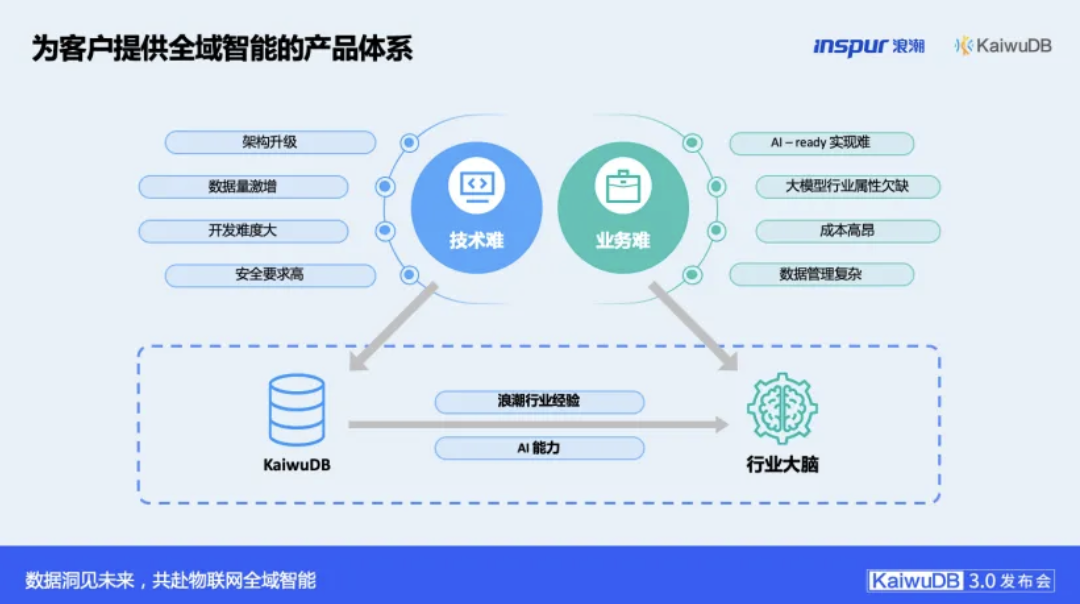
当前,企业正身处一个关键的转折点。Gartner预测:所有在AI领域投入重金的企业,都必须将数据管理能力向AI领域延伸。然而,市场的焦点正从喧嚣的生成式AI,回归到支撑其长期发展的基础性技术。企业AI落地之路,面临着技术与业务的双重挑战:在技术侧,数据激增对现有系统构成压力,系统集成复杂且技术门槛高;在业务侧,合适的场景难觅、投入产出比难以评估,而高质量的“AI就绪型数据”更是稀缺资源。
面对这些根本性的挑战,KaiwuDB的选择是回归根基,强化核心。其全新发布的3.0版本,正是一次立足现实的战略升级。本次升级坚定地将重心置于物联网数据基座本身——通过在多模融合、时序性能和实时处理能力上的关键提升,首先解决“AI就绪”的数据基础问题,进而为企业提供坚实的“AI+”产品及服务,赋能业务未来。
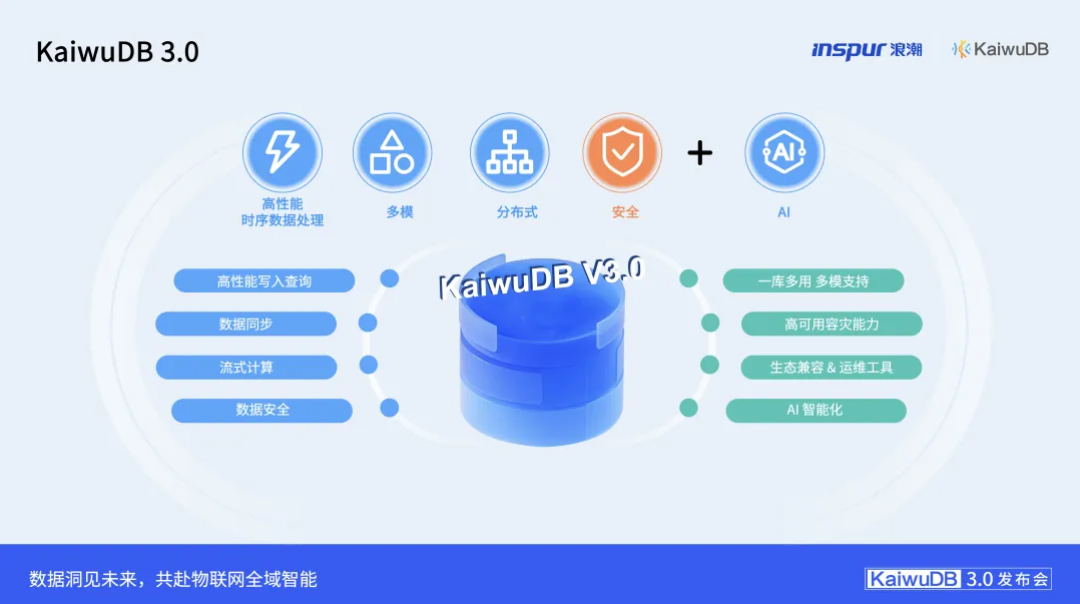
性能跃升:打造物联网数据处理的效率标杆
对于物联网场景而言,数据库的性能,尤其是时序数据的处理能力,直接决定了业务的实时性与成本效益。KaiwuDB 3.0在此方面的突破,是其作为数据基座最坚实的证明。
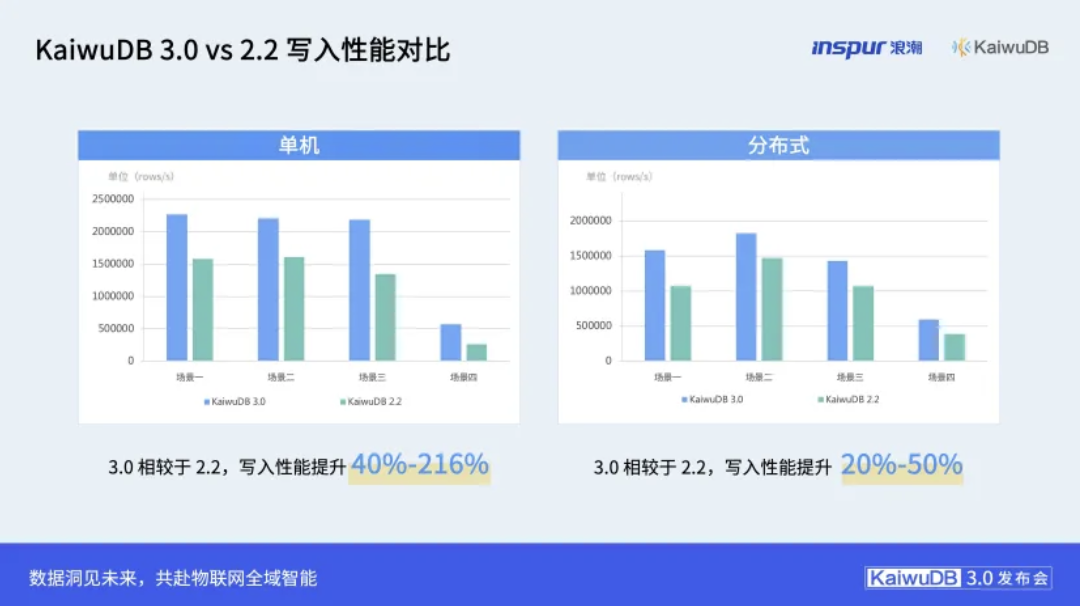
显著的性能指标提升是本次升级最直观的体现。根据陈磊公布的数据,KaiwuDB 3.0的单机写入性能较上一版本(V2.2)提升高达40%至216%,分布式写入性能提升20%至50%。在查询方面,性能平均提升50%,在部分复杂场景下,性能跃升甚至达到600%。这些数字的背后,是应对智能制造、智慧能源等领域中日均TB级数据吞吐的硬核实力。
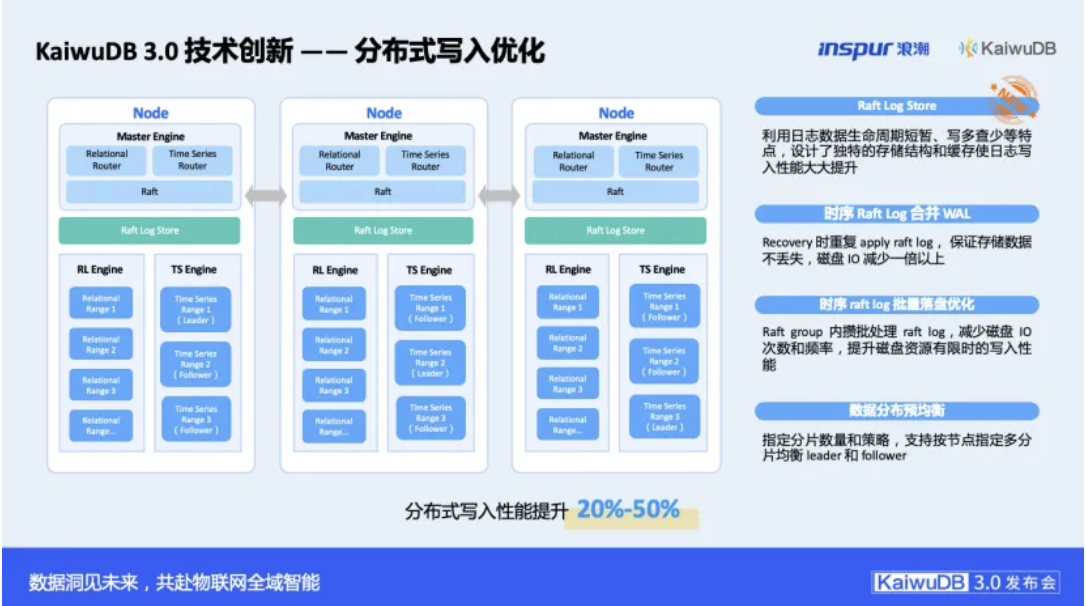
这一性能飞跃源于其内核的深度优化。在分布式写入层面,KaiwuDB 3.0版本通过将时序Raft Log与存储引擎的WAL(预写日志)合并,显著减少了系统的“写放大”效应。同时,自研的Raft Log Store针对日志数据“写多读少、生命周期短”的特点,设计了独特的存储结构与缓存,大幅提升了日志写入性能。结合Raft Group内的批次缓存和数据预分布等机制,共同构筑了高并发、低延迟的写入能力。在此基础上,结合自研的“主键标签”机制,从根本上优化了时序数据的物理组织,为后续的高效检索奠定了结构基础。
在查询层面,3.0版本的时序执行引擎优化:在原有火山模型基础上,根据计算复杂度和数据汇总程度划分为多个Pipeline任务,使得调度更灵活,并发性能更优。同时引入的 Block Filter 技术,能将过滤条件下推到存储层,使其能基于数据块的统计信息预先过滤掉大量无效数据,从而在查询伊始就极大提升了效率。此外,在不同节点的时序执行引擎(TS Engine)之间增加的BRPC高速网络通信,专为节点间传递计算中间结果设计,进一步提升了分布式查询的执行力。
多模融合:从“架构简化”到“价值释放”的质变
物联网数据天然是多模的:既有设备产生的海量时序数据,也有关联的设备信息、业务订单等关系数据。传统方案通常采用“时序库+关系库”的混合架构,这不仅带来了高昂的运维成本,更导致了数据孤岛,使得跨类分析变得异常复杂。
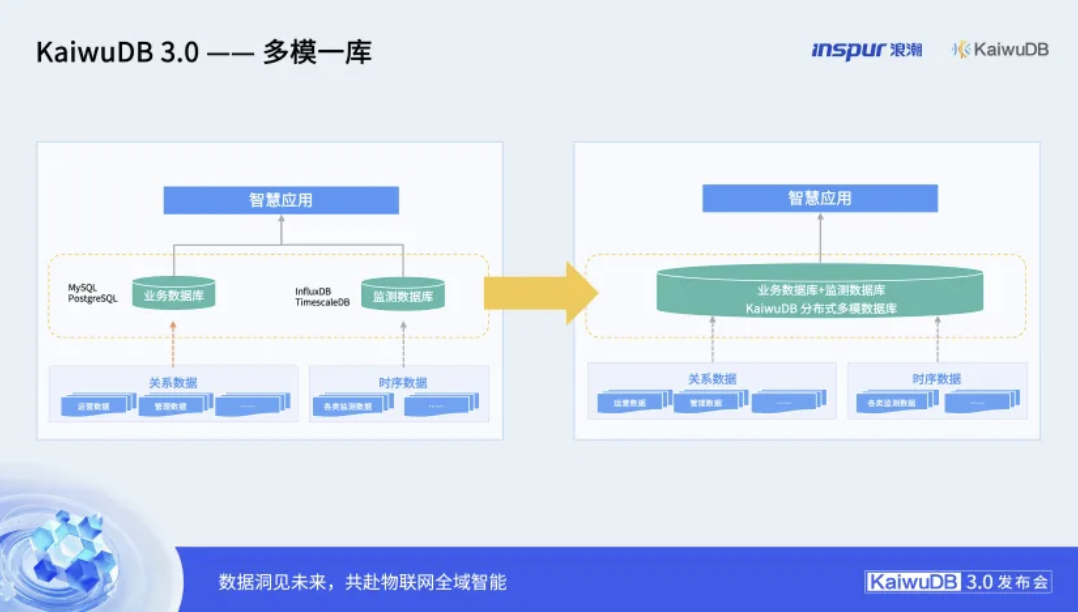
KaiwuDB 3.0增强的“多模一库”能力,正是破解这一难题的利器。它在一个数据库实例内原生统一了时序与关系数据模型,通过增加高效跨模连接算子,时序算子并行处理优化,跨模查询性能提升5-10倍,这标志着其从“能用”到“高效好用”的关键跨越。
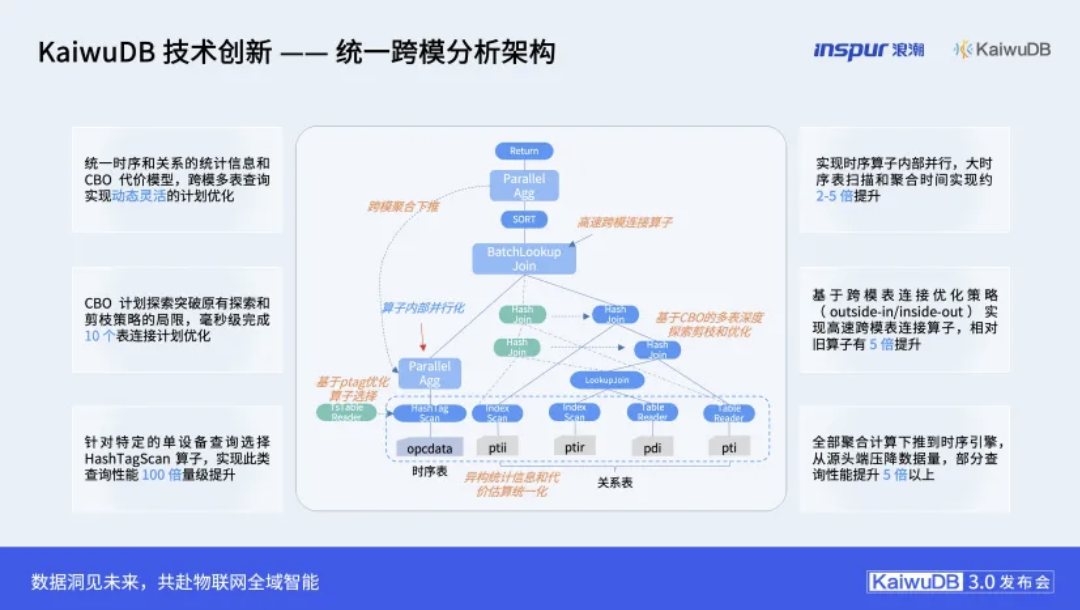
其卓越的跨模查询性能,源于在数据库核心引擎上进行的一系列深度、协同的优化。首先,在优化准备阶段,统一了时序数据和关系数据的统计信息与CBO(基于成本的优化器)代价模型,为查询优化器提供了准确的决策依据。在此基础上,通过“算子下推”技术,将计算任务尽可能下沉到靠近存储的引擎端执行,从源头减少了数据移动与中央处理器的压力。继而,增强的CBO计划探索能力能够在毫秒级时间内完成多达十个表的连接计划优化。
在执行层面,革新同样关键。通过增加时序数据扫描的算子并行度,并引入基于跨模表连接优化策略实现的高速跨模表连接算子,大幅提升了数据关联的效率。此外,针对特定查询模式优化的“特定设备扫描算子”也发挥了重要作用。这一系列从优化到执行的系统性升级,共同构成了跨模查询性能提升5-10倍的技术基石。
这意味着,在智慧工厂中,分析人员可以直接、快速地将生产线上传感器(时序数据)的实时抖动,与设备的维护工单(关系数据)进行关联分析,瞬间定位问题根源。这种实时、高效的跨模查询能力,为业务系统的实时分析与精准决策提供了坚实的数据支撑。
战略延伸:从坚实基座到“AI+”产品及服务
在夯实性能与实时能力这一数据基座“主体”之后,KaiwuDB 进一步将战略重心拓展至智能化领域,这一演进并非技术的自我衍生,而是紧密围绕用户在实际业务中对“数据驱动智能”的迫切需求展开。 其战略思考清晰而务实:一个强大的多模数据库可以解决“AI就绪”的数据基础问题,但要实现真正的“AI业务赋能”,还必须提供“AI+数据服务”的完备体系。
这一战略延伸具体呈现为三个层次清晰的支撑:
第一级,坚实的“AI-Ready数据底座”。这正是KaiwuDB 3.0的核心使命。其优异的性能可以保证海量的数据采集、治理、模型训练和预测等需求。客户的架构在底层数据层采用KaiwuDB就可以稳定有效地支撑,这种简化的架构,兼容传统SQL与开发框架的特性,显著降低了开发难度与升级成本。
第二级,开放的“数据管道生态”。与EMQ等伙伴的深度合作,确保了数据能从边缘到云端无缝、实时地流动起来,为AI模型提供源源不断的“活水”。
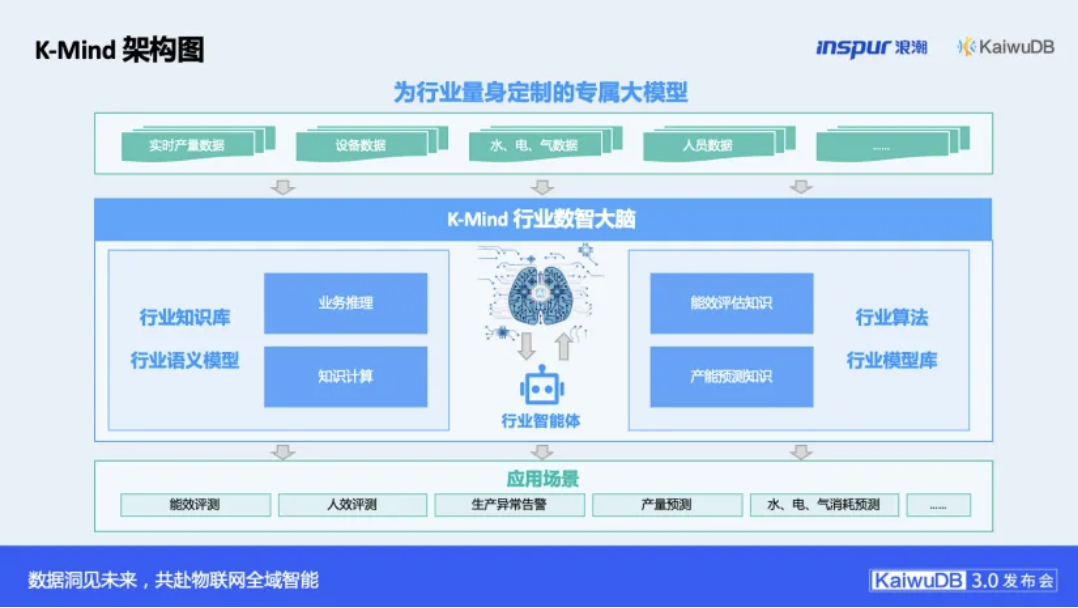
第三级,聚焦的“行业大脑”。浪潮集团在各行业积累的丰富经验与AI能力相结合,最终沉淀为 “行业大脑K-Mind” 。这以开箱即用的AI服务形式,将行业知识封装成可调用的智能体与模型,直接赋能能源、水利等垂直领域的核心业务场景。
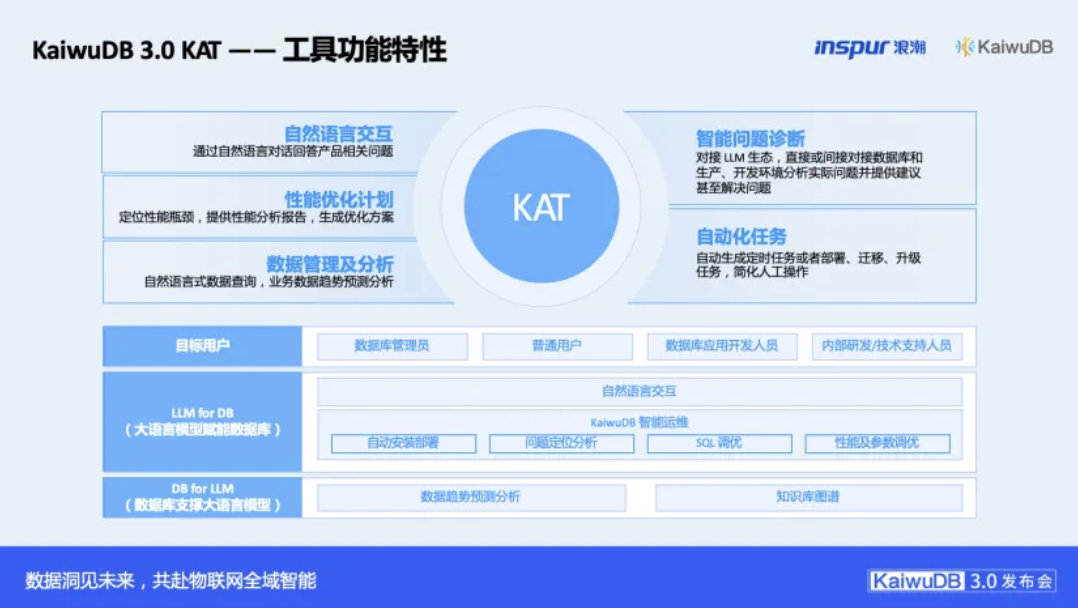
在这个体系中,本次发布的KAT(KaiwuDB智能体)工具也是一个重要的交互入口。它基于Model Context Protocol(MCP)协议,允许用户通过自然语言完成数据库部署、运维与复杂查询。这并未改变数据库高性能的核心,而是大幅降低了使用其强大能力的技术门槛,是“AI+服务”理念的直观体现。
从“驾驭数据”到“唤醒智能”,数据库的终极使命是成为业务伙伴
在发布会圆桌讨论的尾声,一个看似尖锐却直指核心的问题被抛出:“在AI时代,DBA会被取代吗?”这场讨论最终达成的共识,或许正揭示了数据库未来的演进方向:短期内,AI更多的是辅助,长期看DBA的角色必然转型。陈磊认为,“未来的DBA,将不再是忙于优化参数和编写脚本的技术员,而是‘AI运维的管理者’——负责制定规则、校验结果与处理边界情况,从重复劳动中解放出来,专注于更具价值的战略决策。”
这实际上指向了一个更根本的行业之问:在智能时代,数据库的终极形态究竟是什么?
从KaiwuDB 3.0的布局中,我们看到了一个清晰的答案:它正从一个静默的“数据容器”,演进为一个懂业务的“智能伙伴”。这个伙伴的价值,不再仅仅体现为性能报告上提升了百分之几的数字,而是它能如何理解你的业务。它能通过KAT理解你的自然语言指令,能通过流计算主动监控并响应业务状态,能通过“行业大脑”将物联网各个垂直行业的领域知识转化为直接的决策建议。
回溯开篇,“开物成务”的初心,正是通过揭示规律来成就事业。在数字文明的时代,“规律”深藏于海量的数据轨迹之中。KaiwuDB 3.0的实践表明,我们需要的已不仅仅是管理数据的“工具”,而是能够帮助我们洞见规律、激活数据潜能的“伙伴”。
当坚实的数据基座能够承托起万物互联的庞杂,当原生的智能能够理解每一行代码背后的业务意图,企业才真正获得了通往物联网全域智能的钥匙。这把钥匙,开启的不仅是效率的提升,更是一个业务自驱动、决策自优化的全新未来。而这,正是夯实物联数据基座最深刻的战略意义所在。

