微调 LLM 性能:知识图谱如何帮助避免失误
微调是优化预训练 LLM 性能的关键过程。它包括在针对特定任务或领域定制的更小、更具体的数据集上进一步训练模型。这一过程允许大语言模型(LLM)调整其现有的知识和能力,以便在回答问题、总结文本或生成代码等特定应用中表现出色。微调可以纳入特定领域的知识和术语,而这些知识和术语在原始预训练数据中可能没有被充分涵盖。微调还有助于使 LLM 的输出风格和格式符合特定要求。
然而,传统的微调方法有局限性。它们通常需要大量高质量的标注训练数据,而获取或创建这些数据可能既昂贵又耗时。即使在微调之后,如果训练数据不够全面或基础模型存在固有偏差,模型仍可能容易产生误差。微调过程本身也会耗费大量计算资源,尤其是对于大型模型而言。
也许最重要的是,传统的微调可能无法有效地在 LLM 中灌输深入的结构化知识或强大的推理能力。例如,有监督的微调包括对问题-答案对进行训练,以优化性能。虽然这可以提高模型回答问题的能力,但不一定能增强其对主题的基本理解。
尽管传统的微调在针对特定目的调整 LLM 方面非常有用,但它往往无法提供必要的深层事实基础,从而在需要广泛知识的领域中实现真正可靠和精确的性能。仅仅提供更多的问答对可能无法从根本上解决这些模型缺乏结构化知识和推理能力的问题。
通过知识图谱实现增强型 LLM 微调
利用知识图谱(KGs)提供了一种强大的方法来增强 LLM 的微调过程,有效解决了与传统方法相关的许多局限性。通过整合知识图谱中的结构化知识和语义知识,企业可以创建更准确、更可靠、更了解上下文的 LLM。有几种技术可以促进这种整合。
知识图谱改进 LLM 微调的一个重要方法是增强训练数据。知识图谱可用于生成高质量、知识丰富的数据集,而不仅仅是简单的问题-答案对。一个显著的例子是 KG-SFT(知识图谱驱动的监督微调)框架,该框架利用知识图谱为训练数据中的每一对问答生成详细解释。KG-SFT 背后的核心理念是,通过在微调过程中为 LLM 提供这些结构化解释,模型可以更深入地理解与问题和答案相关的底层知识和逻辑。
KG-SFT 框架通常由三个主要部分组成:
提取器:用于识别问答对中的实体,并从 KG 中检索相关推理子图;
生成器,使用这些子图创建流畅的解释;
检测器,通过识别潜在的知识冲突来确保生成的解释的可靠性。
这种方法具有多种优势,包括提高准确性(尤其是在缺少标注训练数据的情况下),以及增强 LLM 的知识操作能力。通过提供源于知识图谱的结构化解释,微调可以超越单纯的模式识别,而侧重于灌输对知识及其背后推理的真正理解。传统的微调可能会教给 LLM 一个问题的正确答案,但知识图谱驱动的方法可以利用知识图谱中的结构化关系和语义信息,帮助 LLM 理解为什么这个答案是正确的。
结合知识图谱嵌入
另一项强大的技术是将知识图谱嵌入纳入 LLM 微调过程。知识图谱嵌入是知识图谱中实体和关系的向量表示,以密集的数字格式捕捉其语义。在微调过程中,这些嵌入可用于将图中的结构化知识直接注入 LLM。
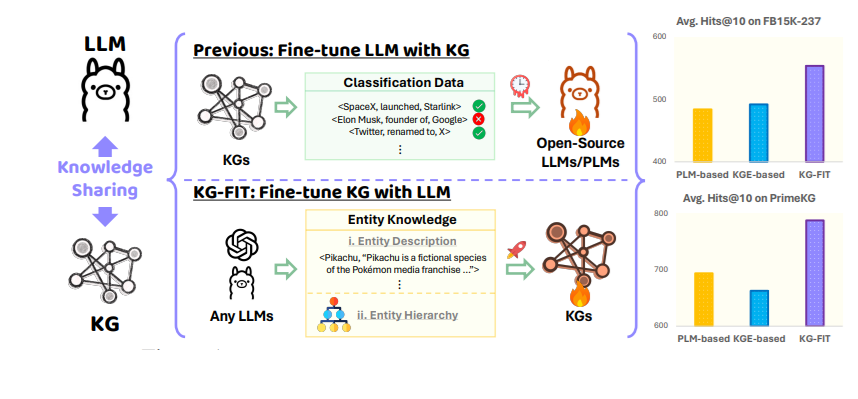
“用 KG 对 LLM 进行微调” vs “用 LLM 对 KG 进行微调”(来源:KG-FIT)
KG-FIT 就是这种技术的一个例子。它利用 LLM 引导的细化,从知识图谱中构建实体簇的分层结构。然后,在对 LLM 进行微调时,将这种分层知识与文本信息结合起来。这种方法既能捕捉 LLM 擅长理解的广泛的上下文语义,也能捕捉知识图谱固有的更具体的关系语义。
通过嵌入图中的知识,与简单处理知识的文本描述相比,LLM 可以更高效、更细致地访问和利用关系信息。这些嵌入可以捕捉 KG 中实体之间错综复杂的语义联系,并以 LLM 可以轻松处理和集成到其内部表示的格式呈现。
图形对齐语言模型(GLaM)微调
GLaM(图对齐语言模型)等框架是利用知识图谱对 LLM 进行微调的另一种创新方法。GLaM 的工作原理是将知识图谱转换为另一种文本表示法,其中包括根据图谱结构和内容得出的带标签的问答对。转换后的数据将用于微调 LLM,从而有效地将模型直接建立在知识图谱中。这种与基于图的知识的直接对齐,增强了 LLM 基于 KG 中存在的结构化关系进行推理的能力。
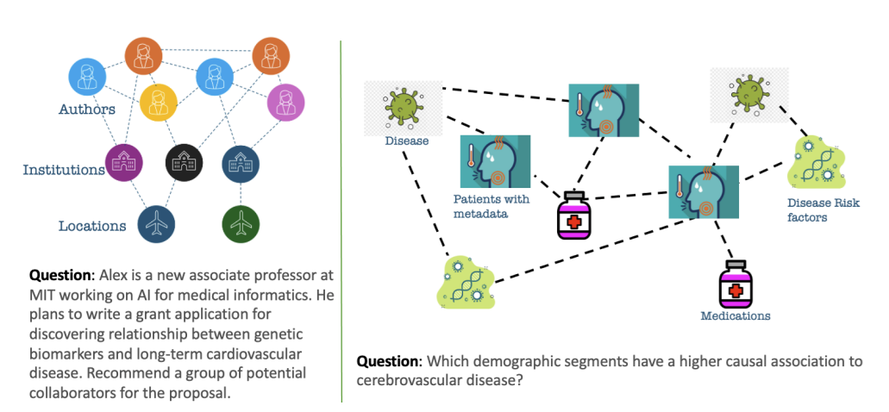
图 1:将基础模型与特定领域知识图谱对齐的激励示例。左图展示了一个查询,在这个查询中,需要将 LLM 与来自社交网络的知识图谱整合在一起。右图展示了一种需求,即需要将 LLM 与从电子医疗记录数据库中提取的从病人档案到疾病的网络整合在一起(资料来源:GLaM:通过邻域划分和生成子图编码微调用于领域知识图谱对齐的大型语言模型)
对于某些严重依赖结构化知识的任务,这种方法可以有效替代基于检索增强生成(RAG)的方法。通过在微调阶段将 LLM 与知识图谱的结构直接对齐,可以实现更深入的知识整合并提高推理能力。这种方法的目的不是在推理时检索知识图谱中的信息,而是将图谱的结构信息内化到 LLM 的参数中,使其能够更有效地推理实体之间的关系。
知识图谱交互的指令微调
还可以对 LLM 进行指令微调,以提高它们与知识图谱交互的能力。这包括根据特定指令训练 LLM,引导其完成任务,例如用 SPARQL 等图查询语言生成查询,或从知识图谱中提取特定信息。此外,还可以提示 LLM 从文本中提取实体和关系,然后用于构建知识图谱。在此类任务中对 LLM 进行微调,可以进一步增强其对知识图谱结构的理解,提高信息提取的准确性。
经过微调后,LLM 可以更有效地用于从非结构化数据中自动创建知识图谱,并对现有知识图谱执行更复杂的查询。这一过程使 LLM 具备了有效浏览和利用知识图谱中包含的结构化信息所需的特定技能,从而使两者之间实现了更无缝的集成。
实现卓越的 LLM 性能和可靠性
知识图谱增强的 LLM 微调能力为企业投资这项技术提供了一个令人信服的新理由,尤其是在 GenAI 时代。这种方法具有显著优势,可直接解决传统 LLM 和传统微调方法的局限性。利用从经过验证的知识图谱中获得的知识对 LLM 进行微调,可显著减少幻觉的出现,并提高其输出结果的事实准确性。知识图谱是可靠的真相来源,它为 LLM 提供了经过验证的事实基础,使其能够做出正确的反应。
例如,知识图谱可以提供真实世界中经过验证的事实,使人工智能能够在生成文本之前检索到准确的信息,从而防止信息被捏造。在准确性至关重要的关键应用领域,如医疗保健、金融和法律领域,这种能力至关重要。通过大幅减少错误信息的生成,企业可以在这些敏感领域部署由 LLM 驱动的解决方案,从而获得更大的信心和信任。
作者Andreas Blumauer 是图人工智能提供商 Graphwise 的高级发展副总裁,该公司是 Ontotext 与 Semantic Web Company 近期合并后新成立的公司。

