图存储技术一览
引言
图存储作为近年来图数据管理领域的核心技术,已在社交网络分析、推荐系统、知识图谱等场景中展现出强大的应用价值。随着图数据规模的迅速增长以及复杂查询需求的多样化,传统关系型数据库在处理图计算任务时的性能瓶颈愈发明显。因此,图存储系统逐渐成为研究热点。
本调研首先对常见的图存储方式进行了介绍,之后对当前具有代表性的图存储工作进行了简要的介绍。
图存储的基本方式
本节我们将详细介绍这图的常见存储方式以及其优势和特点。
邻接矩阵
邻接矩阵(Adjacency Matrix) 是一种常用的图表示方法,通过一个二维矩阵存储图的拓扑结构。对于一个具有 n 个顶点的图,其邻接矩阵是一个 n×n 的矩阵 A,其中 A[i][j]表示顶点 i 和顶点 j 之间的边。矩阵元素的值通常具有以下含义:
非0值表示存在边:如果 A[i][j]>0,则表示存在从顶点 i 到顶点 j 的边,且值为该边的权重。
0值表示不存在边:如果 A[i][j]=0,则表示顶点 i 和顶点 j 之间没有边。

图1 邻接矩阵示例
在图1中,左图是一个有向图的例子,其边上的数字表示边的权重,右图则是根据左边的图生成的邻接矩阵,其中值为0表示不存在边,值非0则表示存在边,且值为该边的权重。例如,v2和v3之间存在边(v2,v3),且其权重为2,因此在矩阵的第2行第3列中的值为2,v2和v4之间不存在任何边,因此矩阵的第2行第4列和第4行第2列中的值均为2。
优点:
快速边查找:能够快速查询任意两点之间的边的数据,查询的时间复杂度为 O(1)。
易于实现矩阵运算:邻接矩阵便于进行矩阵的相关操作,适合某些图算法。
缺点:
空间复杂度较高:邻接矩阵需要n*n的空间来存储图的拓扑信息,其中 n 表示图中顶点的数量。 这对于稀疏图(即边的数量远小于顶点数量平方的图)来说,存储大量不存在的边的信息显得非常低效,导致了严重的空间浪费。
难以支持动态图存储: 当图的顶点数量发生变化(新增或删除顶点)时,邻接矩阵的大小以及数据也会改变,为了支持图的变化则需要重新分配内存并拷贝数据,其操作成本较高。
邻接表
邻接表(Adjacency List) 邻接表以”顶点序列 + 顶点对应的邻居顶点列表“的形式存储图的信息。具体来说,每个顶点对应一个列表,记录了与该顶点直接相连的所有顶点。对于有向图,仅在起点的列表中记录终点。这种方式不必为不存在的边分配存储空间,因此十分适合稀疏图的存储。

图2 邻接表示例
图 2 展示了一个基于链表实现的邻接表,其中右图中的邻接表记录了左图所示图的拓扑结构。例如,在左图中,顶点 v2有两条出边,分别为 (v2,v3) 和 (v2,v4)。因此,在右图的邻接链表中,以 v2 为头节点的链表包含了 v3 和 v4 两个节点。
优点:
空间复杂度低:邻接表只为实际存在的边分配存储空间,而不需要考虑不存在的边,因此其空间复杂度为 O(n+m),其中n为顶点数量,m为边的数量。相比邻接矩阵的O(n2)的空间空间复杂度,采用邻接表可以大幅降低空间开销,尤其是对稀疏图的存储开销的降低更为明显。
边插入操作方便:在邻接表中插入一条边只需要将对应结点添加到相应的邻接列表末尾,实现上相对简单。
缺点:
遍历效率较低:邻接表通常由链表来实现,一个顶点的边的存储空间往往是不连续的,因此遍历一个顶点的所有边时的效率会低于连续存储的数组的数据结构。
对稠密图不友好: 在使用链表存储邻接表时,每个节点不仅需要存储相邻顶点的信息,还需要额外存储一个指针用于指向下一个节点。因此,对于边数较多的稠密图,指针的存储开销会显著增加,占用大量空间。
CSR
CSR (Compressed Sparse Row,) 是一种常用的稀疏矩阵压缩存储格式,通过多个紧凑的数组来存储邻接矩阵中的非零元素。如图 3 所示,CSR 通过以下三个数组来表示图结构:
偏移数组(Offset Array):记录每个顶点的第一条边在边数组中的起始位置。
边数组(Edge Array):连续存储每个顶点的所有关联边,即目标顶点。
属性数组(Property Array):存储边数组中每条边对应的属性信息,例如权重等。

图3 CSR示例
优点:
空间复杂度低: CSR 采用紧凑的数组存储图的拓扑结构,仅记录非零元素,避免了存储无关的零值或额外指针,显著节省内存,非常适合稀疏图的高效存储。
读取性能好: CSR通常使用数组来存储数据,因此数据会存储在连续的内存空间中,在顺序访问时可以充分利用 CPU 缓存和预取机制,从而提高读取性能。
缺点:
写操作效率低: CSR在插入或删除边时为了保证其紧凑性,需要调整整个边数组和属性数组,并更新偏移数组。这些操作可能导致大量数据移动,开销较大,因此对动态图存储并不友好。
邻接矩阵 VS CSR VS 邻接表

当前的代表性工作
LSMgraph
LSM-tree( Log-Structured Merge-tree)是一种紧凑且有序的结构,以其优异的写性能而闻名,它通过将最近的写操作缓存在内存中,然后以顺序写入的方式写入持久化存储来实现。 然而,由于更新边到达的顺序是随机的,顶点的边可能分散存储在整个日志结构中,这会在访问顶点的所有边时降低读性能。
CSR是一种经典的图存储结构, 因为它具有高效的索引和顺序读取能力而具有出色的图查询性能。然而,CSR需要进行大量的数据移动以保持其紧凑性,因此在插入或删除边时会带来显著的开销。

图4 MemGraph结构示例
LSMGraph[1]是一个结合了LSM-tree的写优势和CSR的读优势的动态图存储系统。在内存中,该系统设计了一个高效的图存储结构——MemGraph,它不仅能够快速写入图更新,还能有效地将数据持久化到磁盘中。 LSMGraph 的 Memtable 设计如图 4 所示,其内部通过数组和跳表相结合的方式存储图更新。其中,数组用于存储度数较小的顶点,而跳表则专门存储度数较大的顶点。在磁盘中,如图5所示,LSMGraph将图数据组织成类似 LSM-tree 的多层结构,其中每一层以 CSR 格式维护部分图数据。当第 𝑖 层存储已满时,在后台执行一次压缩操作,将第 𝑖 层的 CSR 异步合并到下一层。通过这种方式,CSR 的在线连续数据移动开销被 LSM-tree 的离线周期性压缩开销所取代。需要注意的是,尽管每层的 CSR 中顶点的边是连续存储的,但这些边可能跨越不同层的多个 CSR,这需要定位它们在多个文件中的位置,进而降低了读取性能。为提高读取性能,LSMGraph设计了一种名为multi-level index的索引结构,用于记录每个顶点边在各层中的位置,从而避免了大量的随机查找。

图5 LSMGraph架构示意图
GART
GART[2]是一个基于内存的图HTAP系统。该系统针对图在线分析处理进行了优化,使其既能够高效支持图数据的更新和查询,以满足对性能的需求。Gart的架构如图6所示,其中txn为事务,日志中的t为表ID,k为主键,v为值,op表示操作类型,ts为时间戳。GART通过事务日志将关系型 OLTP 系统与OLAP系统进行了松散耦合,在GART中,事务在 OLTP 节点提交并生成日志,为灵活高效地支持复杂的工作负载,GART 进行了数据模型转换,将日志中的关系型数据转换为图数据,并存储在 OLAP 节点的动态图存储(GStore)中。
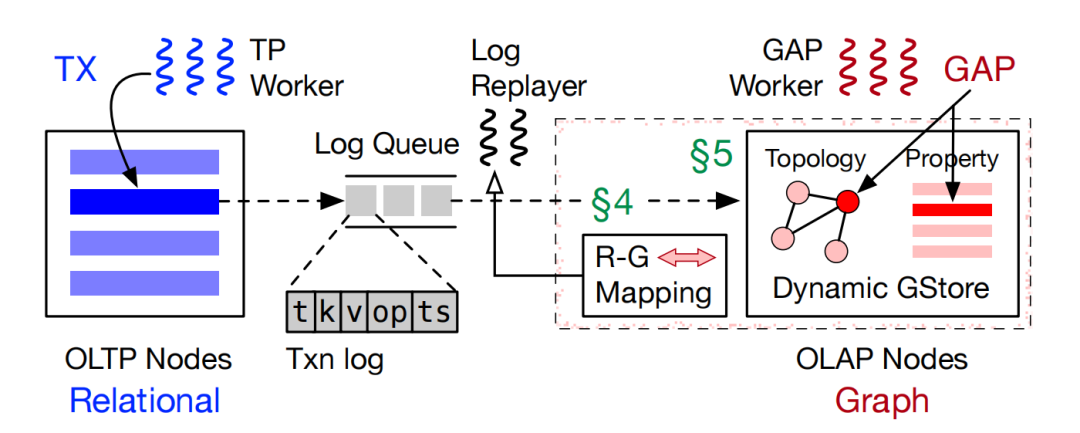
图6 Gart架构示意图
如图7所示,GART设计了一种高效且可变的CSR结构,能够在图拓扑的扫描和更新中提供高性能,并保证类似于不可变 CSR 的数据局部性。每个边段(Edge Segment)具有固定的初始大小,并存储一定数量顶点的边(即邻居顶点的ID)同时为新增边块(Edge Block)预留了空位,每个边块有一个头块(hdr)用于存储边的元数据,例如块大小、有效边的数量,以及指向同一顶点的前一个边块的指针(prev)。在该结构中,每个顶点对应一组边块,新边将插入到尾部的边块中。图 7 展示了一个GART图存储的示例,其中epoch table指向了在同一个epoch插入的边,每个边段存储两个顶点的边。在初始阶段,同一顶点的边在一个边块中连续存储,因此不同顶点的边在一个边段中不会重叠。随着边的不断插入,顶点会分配新的边块,这些边块形成一个链表(如顶点 0 的情况)。

图7 Gart图存储结构示意图
为了更高效地支持不同的 GAP 工作负载,GART 提出了灵活的属性存储机制,允许系统用户根据应用的内存访问模式定义存储模型。为了在不同场景下提升属性扫描性能,用户可以通过 attr_merge 接口预先将多个高度相关的属性组合成一个列族,如图 8 所示。以 Person 顶点为例,其包含三个属性:Bal、Pay 和 Age,如果在长期的 GAP 工作负载中需要同时访问 Bal 和 Pay 属性,用户就可以使用 attr_merge 接口将Bal 和 Pay 属性合并到同一个列族中。

图8 Gart属性存储方式
GalaxyBase
GalaxyBase[3]是一个高性能、原生分布式的图HTAP数据库。 在GalaxyBase中,数据以分区(Partition)为基本单位来存储。每个分区使用日志结构邻接表(Log-Structured Adjacency List)来存储图数据以支持磁盘的高效读写。邻接表实现了顺序读取的高效性,而日志结构解决了读写放大问题。每个分区专门用于存储某一特定类型的顶点及其边。在分区中,顶点及其属性被一起存储,而每个顶点的边被存储在边页(Edge Page)中。每个顶点都分配了一个唯一的 ID,使得能够通过存储的偏移量高效检索该顶点的属性或其所有边。如图9所示,该分区存储类型为 Person的顶点以及其边,顶点的属性存储在VertexData中,与顶点相关的边(如 Alice follows Bob、Bob follows David等)被存储在对应顶点的的边页中。

图9 Gart属性存储方式
在每个分区内,每个顶点通过边偏移量(Edge Offset)来精确定位到对应的边页。在边页内,邻接表被用来存储该顶点的所有邻居边。如果要遍历某顶点的所有邻居,只需遍历边页中的边集合,而无需频繁的磁盘查找。边页的具体设计如图10所示,边页根据边的类型、方向等对边进行组织存储。例如,在这个页中,边按照类型为 follows 且方向为 In 的、类型为 follows 且方向为 Out 的以及类型为 locatedIn 且方向为 Out 的这几种形式进行存储。为便于定位这些边,GalaxyBase还在边页内引入了偏移量(Offset),并设计了一个用于定位特定边的边 ID(Edge ID)。
边 ID 由以下参数构成:
fromId:起始顶点的唯一 ID。
direction:边的方向,二进制整数表示(例如,0 表示 In,1 表示 Out)。
typeIndex:边的类型索引,对应于 follows、locatedIn 等不同边类型。
toId:目标顶点的唯一 ID。
edgeIndex:边的序列索引,表示具有相同 fromId 和 toId 的边中的唯一编号。
在每个边页内,GalaxyBase基于上述边 ID 提出了一种多维排序方法,确保边按照 fromId、direction、typeIndex、toId 和 edgeIndex 的优先顺序排列。通过这一排序方式,边能够自然地按照相同类型和方向进行分组,不仅在每种类型和方向的局部范围内有序,也在整个边页的全局范围内有序。

图10 Gart边表存储方式
TuGraph
TuGraph[4]的整体架构如图11所示,其图存储分为两层,属性图存储层(Property Graph storage layer,PG 层)和键值存储层(key-value storage layer,KV 层)。PG层将图操作映射到键值操作中,同时对边的源顶点和目的顶点信息进行组织。KV 层包含一个支持 ACID 的键值存储,并针对图工作负载中的常见读写模式进行了优化。

图11 TuGraph整体架构
如图12所示,在Tugraph中,顶点和边使用唯一标识符VertexUid和EdgeUid来排序。VertexUid 是从 0 开始自增的整数,EdgeUid 由源顶点的 VertexUid(SrcVid)、目标顶点的 VertexUid(DstVid)、边的标签标识符(LabelId),时间标识符(TemporalId),以及在特定标签和源/目标顶点对中唯一的边标识符(Eid)组成。此外,如图13所示,TuGraph将所有属性紧凑地混合在拓扑布局中,属性紧邻其对应的顶点或边。

图12 TuGraph图拓扑存储方式

图13 TuGraph图属性存储方式
然而,当数据较大时,这种方法在更新时效率较低。尤其是当添加一条边时,需要重新组织所有数据。为了解决这一问题,TuGraph使用了一种自适应映射方法,通过设置阈值,将一个顶点的数据映射为多个键值对。如图 14 所示,图拓扑和键值之间存在两种映射方式,即混合映射和分割映射。在总大小小于设定的阈值(2KB)时采用混合映射,所有数据都被打包在一个键值对中,而总大小大于设定的阈值(4KB)时采用分割映射,在这种方式下,顶点属性、出边属性和入边属性被分配到不同的键值对中存储。

图14 图数据与底层键值存储之间的自适应映射
LiveGraph
如图 15 所示,在LiveGraph[5]中,图存储的核心包括顶点块(Vertex Block, VB)和事务边日志(Transactional Edge Log, TEL),其中顶点的数据存储在顶点块中,边数据存储在TEL中,不同版本的 TEL 通过previous指针链接在一起。顶点块和 TEL 通过顶点索引(Vertex Index)和边索引(Edge Index)实现访问。

图15 图数据与底层键值存储之间的自适应映射
TEL的结构如图 16 所示,TEL是一个固定大小但可动态扩展调整的内存块,用于存储与顶点相邻的所有边及其操作记录,其内部设计空位以应对边的插入,与传统邻接表仅存储当前边不同,TEL 将所有边的插入、删除和更新记录为日志条目。下面我们详细介绍TEL的组成:
边日志条目(Edge Log Entries):边日志条目记录了目的顶点的ID以及对应的属性条目(Property Entries)的大小,其具有固定大小,并采用缓存对齐字段,每个日志条目还包含两个时间戳,分别表示创建时间和失效时间。在追加时,边日志条目从最左边进行追加,扫描时从左向右顺序读取日志条目,这种设计利用了时间局部性,使得最近添加的元素优先被读取。
属性条目(Property Entries):属性条目记录了边的属性,其大小可变并记录于边日志条目中。属性条目与边日志条目分开存储,能够提升事务处理性能。

图16 TEL存储结构
参考文献
[1] Yu S, Gong S, Tao Q, et al. LSMGraph: A High-Performance Dynamic Graph Storage System with Multi-Level CSR[J]. Proceedings of the ACM on Management of Data, 2024, 2(6): 1-28.
[2] Shen S, Yao Z, Shi L, et al. Bridging the Gap between Relational {OLTP} and Graph-based {OLAP}[C]//2023 USENIX Annual Technical Conference (USENIX ATC 23). 2023: 181-196.
[3] Tong B, Zhou Y, Zhang C, et al. Galaxybase: A High Performance Native Distributed Graph Database for HTAP[J]. Proceedings of the VLDB Endowment, 2024, 17(12): 3893-3905.
[4] Lin H, Wang Z, Qi S, et al. Building a High-Performance Graph Storage on Top of Tree-Structured Key-Value Stores[J]. Big Data Mining and Analytics, 2023, 7(1): 156-170.
[5] Zhu X, Feng G, Serafini M, et al. LiveGraph: A transactional graph storage system with purely sequential adjacency list scans[J]. arXiv preprint arXiv:1910.05773, 2019.

