解析Redis的“快”究竟适合哪些应用场景
【摘要】Redis之所以“快”,并不仅仅因为它是运行在内存里的数据库,而是因为很多维度的创新。本文结合保险行业电子保单业务场景来分析Redis是如何发挥其优势的,以帮助大家更好地评估Redis在自己业务中的潜在价值,更加明确对Redis应用场景的选择思路。
【作者】赵海,某保险企业高级主管。2007年参加工作,先后在IBM、HP、城商银行、半导体制造公司、保险公司等任职。先后从事过IT工程师、架构师、运营管理等职位,对IT基础架构建设以及运维管理有比较丰富的理论实践经验。目前在保险公司从事数据中心运营管理相关工作。
引言
提及Redis,大多数从事IT工作的都知道它是一种非常快的数据库。如果进一步问它为什么那么快,可能大多数人会回答“它是运行在内存里的数据库,所以快”。其实Redis是因为很多维度的创新才支撑了“快”的评价。如果我们了解了它在数据模型、处理模式等方面的特点,就会更加了解它的“快”适合哪些应用场景。本文从Redis的技术剖析维度结合保险行业电子保单业务场景来分析Redis如何发挥其优势。
一、什么是Redis?
Redis,英文全称是Remote Dictionary Server(远程字典服务),是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、KEY-Value数据库,并提供多种语言的API。
从以上对Redis的概念诠释来看,它是数据库,它的数据模型为健值数据结构。
接下来我们再从其他几个维度对比方式来认识一下Redis。
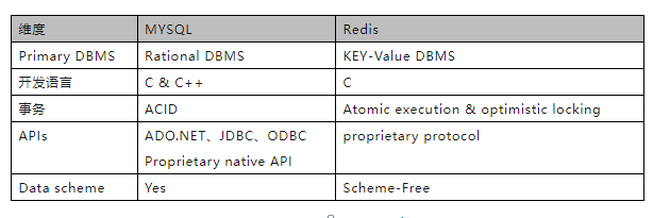
从以上对比来看,我们发现Redis与通常的MSQL相比较而言,数据结构类型不同,并发控制机制不同,API接口不同,数据管理模式也不同。从数据类型以及其访问速度之快(根据Redis官方测试基准数据,可以达到十万QPS)的特点出发,多数情况下它会被应用在大型缓存的场景下。
接下来我们从几个维度来看Redis的性能是如何发挥出来的。
二、内存操作
2.1 数据库的基本操作
Redis的基本操作除了基本的增删改查之外还有以下几种常规操作:

Reids中数据过期策略采用定期删除&惰性删除策略。
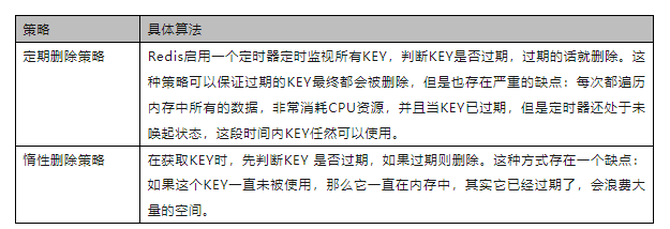
这两种策略天然的互补,结合起来之后,定时删除策略就发生了一些改变,不在是每次扫描全部的KEY了,而是随机抽取一部分KEY进行检查,这样就降低了对 CPU 资源的损耗,惰性删除策略互补了为检查到的KEY,基本上满足了所有要求。但是有时候就是那么的巧,既没有被定时器抽取到,又没有被使用触发惰性删除,同样会占用大量内存,于是内存淘汰机制就会上场。
Redis 内存淘汰机制有以下几种策略:
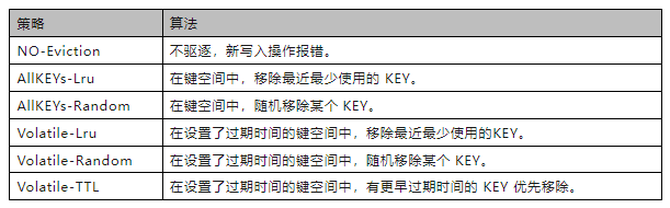
从Redis的基本操作本身来看,与其他的关系型数据库的增删改查以及数据换入换出的相关操作及操作相比较而言,在数据量级上、读写特点上并没有特别奇特之处。
2.2 硬件读写速度
内存是电脑中与CPU直接相连的存储设备,它通过总线与CPU进行数据交换。DDR3和DDR4内存的读写速度大约分别为10GB/s和50GB/s。硬盘是一种机械式存储设备,其内部通过磁头和盘片进行数据读写。机械硬盘的读取速度通常在100MB/s至200MB/s之间,写入速度通常在50MB/s至150MB/s之间。固态硬盘(SSD)的读取速度通常更快一些,大约在300MB/s至550MB/s之间,写入速度通常在200MB/s至350MB/s之间。基本上内存的读写速度要远超硬盘的读写速度,就算是与SSD硬盘相比,速度也是其几十倍。
三、线程模式
3.1 单线程模式
所谓单线程是指对数据的所有操作都是由一个线程按顺序挨个执行。单线程处理模式的有点在于:
(1)不会因为线程创建导致的性能消耗;
(2)避免上多线程上下文切换引起的 CPU开销;
(3)避免了线程之间的竞争问题,不需要考虑各种锁的问题。
这几点优势当中,第二条是提升性能优势的最关键的一条。有优势就必然有劣势,大家一定会关心因为单线程模式导致的CPU资源浪费以及对并发业务的处理能力。对于CPU的问题,官方的答复“因为 Redis 是基于内存的操作,使用Redis时,几乎不存在CPU成为瓶颈的情况, Redis主要受限于服务器内存和网络。”其实这一点大家从Redis的数据结构和使用场景上也可以判断出来。那么对于并发问题,Redis是如何考虑的呢?
3.2 IO多路复用
Redis的并发处理是靠IO多路复用技术实现的。多路指的是多个 socket 连接,复用指的是复用一个线程。IO多路复用主要有三种技术:select,poll,epoll。epoll 是目前最新最好的IO多路复用技术,Redis就是采用这种技术。其基本原理为:内核不监视应用程序本身的连接,而监视程序文件描述符。当客户端运行时,它将生成具有不同事件类型的套接字。在服务器端,I/O 多路复用程序会将消息放入队列,然后通过文件事件分派器将其转发到不同的事件处理器。
一个基本的网络 IO 模型,当处理 get 请求,会经历以下过程:
(1)和客户端建立建立 accept;
(2)从 socket 种读取请求 recv;
(3)解析客户端发送的请求 parse;
当监听到一个客户端有连接请求 accept(),但一直未能成功建立起连接时会阻塞,导致其他客户端无法和服务器建立连接。类似的,当recv()从一个客户端读取数据时,如果数据一直没有到达,也会一直阻塞。但是IO多路复用技术实现了accept()、recv()和线程处理的分离,服务器端的线程不再与客户端的套接字完全对应,中间增加了事件机制。这就是它可以处理并发的原因。
四、数据结构
Redis主要的数据结构就是健值对,但是对于值(Value)来讲,对于数据库的性能是有着很大影响的。对于Redis的Value常用的数据结构包含:String、List、Hash、Set、Zset。他们都是基于基本的字符串、列表、哈希等基本类型进行改造了的高效数据结构。以String为例说明。
基本的String类型,通常使用长度为 N+1 的字符数组来表示长度为 N 的字符串,并且字符串数组的最后一个元素总是空字符 '\0'。Redis使用的SDS字符串,在通常字符串的基础上增加了几个字段,分别用来标识空闲空间和当前数据长度。
正因为这两个重要的字段,使得Redis有了非常重要的性能提升:
(1)它可以使得Redis以O(1)复杂度获取字符串长度:有len字段的存在,无需像C结构一样遍历计数。
(2)提高内存分配的效率,C字符串不记录已占用的长度,所以需要提前分配足够空间,一旦空间不够则会溢出。而有free字段的存在,让SDS在执行前可以判断并分配足够空间给程序。同时减少字符串修改带来的内存重分配次数,提高空间预分配和惰性释放的能力。
其他数据结构就不再详细列举,感兴趣可以查询官方文档仔细研究。
五、保单系统应用分析
某保险公司原来的电子保单采用传统的文件式存储、传输以及调阅方式。随着互联网渠道的不断拓展,越来越多业务系统会涉及到电子保单的传输及调阅,尤其在某些保险业务集中时间段,业务查询会变得非常慢。在公司的整体信息化战略下,电子保单的存储也进行了升级(Redis5、64G内存、5台云服务器成为支撑保单系统缓存数据的平台)。通过升级获取了三方面的价值:
(1)保单号作为哈希健,保单本身通过字符串、列表等丰富的数据结构实现了灵活展现。高性能哈希数据结构支撑了保单信息的高速查询。
(2)Redis的订阅发布机制支撑了电子保单在不同业务渠道之间的信息传输。
(3)Redis既支持数据在内存当中存储,同时也支持数据的持久化。这一点也与电子保单的高速并发查询以及可延时落盘的需求相契合。
简言之,Redis是一个使用内存做缓存的开源数据库管理系统,它支持多种数据结构,它的高性能、高可用性和开放性使得保险公司可以轻松实现电子保单的存储、管理和传输等功能,解决了传统以文件方式进行管理的灵活不足、性能不佳等问题。
六、总结
凡事必有缘由,通过以上分析,正是因为在硬件、线程模式以及数据结构等方面的优势,Redis天然成为一种非常快的数据库,在快的同时我们同时看到了它在数据模型方面的包容性和并发连接处理的先进性。理解这些之后,再来审视在保单业务当中的具体应用,就不难发现其技术的优势与应用场景的契合点,同时也更加明确了大家对Redis应用场景的选择思路。

