PostgreSQL“平替”Oracle:应用和基础架构改造技巧经验分享
【摘要】数据库替换已经是很多企业必须面对或者正在面对的问题,在数据库迁移替代工作中,能够“平替”肯定会大大节约迁移的成本,但是我们不能因为两者业务代码和迁移的高兼容性,忽视和轻视应用和基础架构、运维改造工作,否则就会为今后的长期应用与运维埋下不稳定的因素。本文作者总结了PostgreSQL替换Oracle过程中,一些常用的应用的改造技巧和PostgreSQL索引的选择场景,以及二者运维中的差异,希望能为大家提供参考。
【作者】董爱军 银行系统架构师
一、引言
Oracle数据库是商业专用多模型数据库管理系统,也是世界上最大的关系数据库管理系统(RDBMS)。尽管Oracle依旧是市场上排名靠前的数据库,但是2013年以来,开源数据库势不可挡的崛起。尤其是PostgreSQL开源数据库,导致了Oracle市场份额的大幅度下降。和Oracle比较,在应用和基础架构的运维方面,PostgreSQL有很多的不同之处。很多企业在系统改造的时候,越来越多的采用PostgreSQL数据库替换Oracle数据库。
在数据库迁移替代工作中,能够“平替”肯定会大大节约迁移的成本,但是我们不能因为“平替”能力的不足而放弃优化工作,否则就会为今后的长期应用与运维埋下隐患。特别是平替过程中,应用和架构的改造必须与实际的企业场景和生态相结合。
二、应用和基础架构的平滑替换
数据库平滑替换的时候不仅仅要考虑数据库本身的兼容性,还要考虑二者之间的一些技术差异,要想办法弥补PostgreSQL数据库的缺陷。
例如Oracle应用开发时候,很少考虑技术细节,全部交给数据库做都是可以的。但是在PostgreSQL使用中,就需要有所考虑了,不能完全把PostgreSQL当作Oracle的性能使用。
比如对于PostgreSQL数据库来说,一些WHERE 条件带or的SQL,如果以前Oracle上的执行计划使用HASH JOIN效果很好,到了PostgreSQL数据库上,就只能走NESTED LOOP了。如果JOIN的表数据量很大,返回的结果集也很大,那么平替时就必须对SQL进行改写,否则平替后的性能必然是无法接受的。此类SQL数量不多,如果在平替之时做些测试,在迁移时把这些SQL改写好,那么平替工作也就顺利多了。
除此之外,我们还需要充分利用开源PostgreSQL数据库的优势方面。例如PostgreSQL数据库的索引种类比Oracle要丰富得多,如果选用得当,那将会事半功倍。这时候如果应用能够进行索引的优化设计,将会让平替后运行更加顺利。此外另外如果我们的某些数据的写入和访问带有时序特性的,那么平替到PostgreSQL的时候设计好分区的策略和老数据压缩的策略,那么这部分的数据访问效率也会大大的提高。
以下是我常用总结的一些常用的平替过程中应用的改造技巧和PostgreSQL索引的选择场景。
2.1 设计技巧
1)灵活运用NF,但是不拘泥于NF,对数据库而言,单表的查询性能一定是强过多表关联查询的效率。所以在表设计的时候,对表保留一定的冗余。
例如下面的例子. 客户号是主键,根据三要素查询出最近1个月内拜访的次数
tb_cust_info (cust_no,cust_name,cust_code_type,cust_code,cust_age,cust_saley)
tb_cust_vist(cust_no,cust_name,cust_code_type,cust_code,vist_date,vist_targt)
考虑到拜访业务可能并不知道客户的变化,只知道客户的属性信息,所以在设计vist表时候,将客户的属性信息作为表的字段冗余设计进来,增强查询性能。
2) 灵活使用PostgreSQL的特殊数据类型
有这样的一个需求,给客户画像。一个客户身上有很多的标签。最初的设计的时候,设计的是这样的表:
tb_cust_label (cust_no, label_no,label_desc)一个人一个标签一条记录。 不光占空间同时查询效率和索引效率都比较低。
后续改成了:
tb_cust_label (cust_no, label) label是jsonb的数据类型,在上面建立GIN索引,优化查询的速度。
但是这不是一成不变的。
首先jsonb 的查询速度也受到数据表中jsonb 数据的大小和数量的影响。当 jsonb 数据较大或者数量较多时,查询速度可能会变慢,因为需要进行更多的解析和比较操作。
另外如果是要对 JSON 中的某些字段进行数值比较或者日期比较时,jsonb 需要将 JSON 中的数据解析出来,进行类型转换,然后再进行比较。这样的过程可能会比直接使用数字或日期类型的列进行比较要慢。
3) 有所取舍,将数据库性能不足的地方由应用完成
多表关联影响查询速度时候,这种在报表分页展示时候特别明显。但是主表可以决定总的数据量和排序的顺序的时候。只在主表上查询出需要的数据,然后应用中根据主表分页查询出的数据,查询副表得到相关的数据,最后将数据拼接起来。从而达到与多表关联一样的效果。
2.2 根据场景选择合适索引(如表1所示)

2.3 分库分表
PostgreSQL由于单库性能不如Oracle,单个数据库无法承载较高的访问压力,一般应用中的设计方式,是使用分库策略。将一个数据库的压力分散到多个数据库执行。
分库分表自己在代码中实现的话,需要管理对各数据源,执行一次查询,需要定位到数据保存在哪个数据源上;当执行插入操作时,又需要确认需要将数据保存在哪个数据源中。
分库分表不仅有 SQL 解析和路由的问题,同时还会有 SQL 改写、并行执行、结果集合并等问题;所以应用经常会使用分库分表的组件,来屏蔽这些复杂的功能,最常见的是Proxy 代理模式,在应用程序和数据库中间,单独部署一个代理层,所有的连接和数据库操作都发给这个代理层,由代理层去做底层的实现。
这样做对应用人员来说,是完全不需要知道下面做了什么的,甚至不需要做任何的代码改造,就可以完成接入,如图1所示。
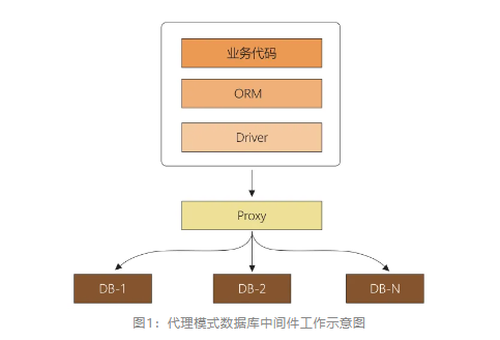
图1:代理模式数据库中间件工作示意图
常见的框架有:MyCat、sharing-sphere等等。
2.4 存算分离架构
随着数据的快速膨胀,用户对海量数据的分析需求越来越明显,传统的方式在做海量数据统计汇总的时候,比老黄牛还慢,分析过诊断结果无一例外:磁盘转速不够、网络传输不够、CPU处理能力不够。总而言之,系统需要扩容。
在这方面Oracle通过内存融合技术在两个计算节点间,共享对方节点的内存数据,来减少磁盘读取带来的IO,从而提高性能。为了在替换之后,依旧能够实现计算、存储的能力弹性扩展,按需分配,这里就不得不提及PostgreSQL的存算分离。存算分离的本质在IO,技术核心在减少网络传输的IO。
存储层:PostgreSQL可以使用对接外置存储来实现存储层和计算层的分离,例如PolarDB for PostgreSQL,将数据文件、Redo Log等存储于远端的共享存储节点。这样解决了主从(Master-Slave)异步复制所带来的备库数据非强一致的缺陷,使得整个数据库集群在应对任何单点故障时,可以保证数据零丢失,同时大大降低扩容成本。
计算层:PostgreSQL利用扩展和插件,可以实现大规模数据计算,例如使用PL/Python来实现自定义的数据处理和计算操作。同时,也支持基于流的数据处理,可以使用Citus、TimescaleDB等扩展来实现流式数据分析。
最后在存算分离接口:PostgreSQL提供如libpq、JDBC等接口,将存储层和计算层连接起来,实现数据读取和写入操作。同时,PostgreSQL还支持外部表的概念,可以将外部数据源映射为表,然后进行查询和处理。这样可以在不同数据源之间进行数据传输和计算操作。
总之PostgreSQL是一个非常适合实现存算分离的数据库,上一章的分库分表其实也是存算分离的一种表现形式。通过存算分离达到平替后了与Oracle相同的处理能力。
三、运维的平滑替换
PostgreSQL与Oracle架构相比,运维过程中还是有很多差异的,总结归纳如表2所示:

表2:PostgreSQL与Oracle运维差异
PostgreSQL是开源数据库,无原厂支持,第三方服务水平较低,与拥有原厂标准化补丁和服务的Oracle相比,PostgreSQL数据库这方面相对较弱,需要第三方服务或者自己解读源码来加以支持。
对于运维监控与优化而言,PostgreSQL数据库提供了同样丰富的监控接口和指标体系,不过部分监控接口需要安装插件,包括一些十分重要的监控采集内容,比如动态统计视图,都需要安装插件来实现。另外一方面,PostgreSQL数据库和操作系统结合得十分紧密,运维工作与OS关联紧密。
与Oracle数据库不同的是,PostgreSQL数据库的大版本升级对运维细节影响较大,甚至很多运维细节都是颠覆性的。因此需要PostgreSQL的运维人员不断地更新版本信息,否则很容易出现认知错误。
最后一方面,PostgreSQL开源的第三方工具和第三方生态产品较多,而且这些工具与Oracle的第三方工具、生态产品不同,如果不能很好地掌握这些工具和生态产品,会对PostgreSQL数据库的运维产生比较大的影响。运维Oracle数据库,由于Oracle数据库自身构成了一个十分完善的体系,周边工具与OracleRDBMS之间是紧密集成,而且从底层是贯通的。而PostgreSQL数据库则不同,PostgreSQL社区仅仅提供了一个RDBMS和一些必要的外围工具,剩下的应用所需要的功能都是其他的开源项目提供的。因此PostgreSQL周边的生态工具数量庞大,功能也存在差异,与PostgreSQL数据库的集成也是应用级的,没有在RDBMS底层进行打通。
最后也是最大的问题是用户在选择PostgreSQL产品的时候也比较随意,不同系统可能会选择不同的高可用解决方案,选用不同的读写分离集群方案,使用不同的第三方插件来解决一些数据库的功能问题。因此PostgreSQL数据库运维平替,需要全面地掌握这些第三方生态工具,才能够真正把PostgreSQL数据库的运维服务做好。
最后总结PostgreSQL运维工作中相对Oracle的事项:
1) 架构优化、OS参数优化、文件系统优化、数据库参数调整;
2) 升级频繁,PostgreSQL版本升级更新周期短,需要常学习关注,了解最新版本的异常点。数据库的更新主要靠版本升级解决;
3) 日常维护中索引重建、碎片整理、表分析容量预测这些工作会比Oracle多。
四、结语
PostgreSQL的平滑替换Oracle之路虽然漫长,但是已经有很多企业进行有益的尝试和取得了较大的进展,相信不久将来PostgreSQL技术路线的应用会在核心系统中占有越来越重要的地位。

