崖山数据库王南:“后战国时代”数据库技术与商业化出路和方向探索
国产数据库百花齐放,百家争鸣,竞争也很激烈。随着行业应用从探索和试点走向产业规模应用,未来市场的出路和方向有哪些可能?
在第15届中国数据库技术大会(DTCC2024)大会上,深算院首席产品官/崖山科技副总裁王南带来了题为《“后战国时代”数据库商业化出路和方向探索》的演讲,探索中国数据库的未来发展出路。

本文由ITPUB整理,经王南老师授权发布。以下为演讲实录。
“后战国时代”数据库如何大规模应用
《资治通鉴》开篇,是周威烈王三家分晋,这是春秋和战国的分水岭,春秋时代大家彬彬有礼,战国时代进入了群雄逐鹿,甚至尔虞我诈。战国时代最后秦统一六国,经历了很短暂的统一之后马上又陷入混乱局面,这和国内数据库产业有很大的相似之处。
从商业数据库对市场的统治地位,到国产数据库的蓬勃发展,大家对国产自主化在一段时间内抱了很高的期望,但是经历自主化的改造和应用试点之后,发现这件事情还是比较困难,到现在300多家数据库,大家都在思考一个问题:当前这个后战国时代,我们从商业和技术上要往什么方向走,出路是什么?
最近有一个热点话题《黑神话:悟空》,这是一款单机游戏。很多人讲单机游戏在网游和手游的时代已经没落了,为什么它能够火爆全网,甚至火爆全球?
这里面有两个关键要素:这款游戏的剧情、画面、音乐效果、关卡设置、武打动作以及故事的剧本都有非常高的品质,这样的游戏能够爆火,说明大家对高品质游戏的渴望;外交部发言人毛宁8 月 21 日记者会上,被问及该游戏爆火时表示“这反映了中国文化的吸引力”,也让大家欣慰看到中国的文化得到世界的认可。我想这两个要素和当前中国数据库行业面临的问题有异曲同工之处,用户对高品质的数据库有非常深切的渴望,我们也应该对数据库的自主创新充满自信,真正做出优秀和高质量的产品。
数据库不是新的行业赛道,已经经过数十年的发展,但用户诉求仍在不断变化,近几年随着云计算的发展,DBaaS、云原生数据库有了新的演进的方向。国内最近又有了数据安全和自主化等新的诉求,为国产数据库带来了新的挑战和机遇。
国产数据库发展了很长时间,经过多年探索和尝试,已经开始走向产业规模化应用,规模化应用和创新试点对于数据库的诉求有很大区别。
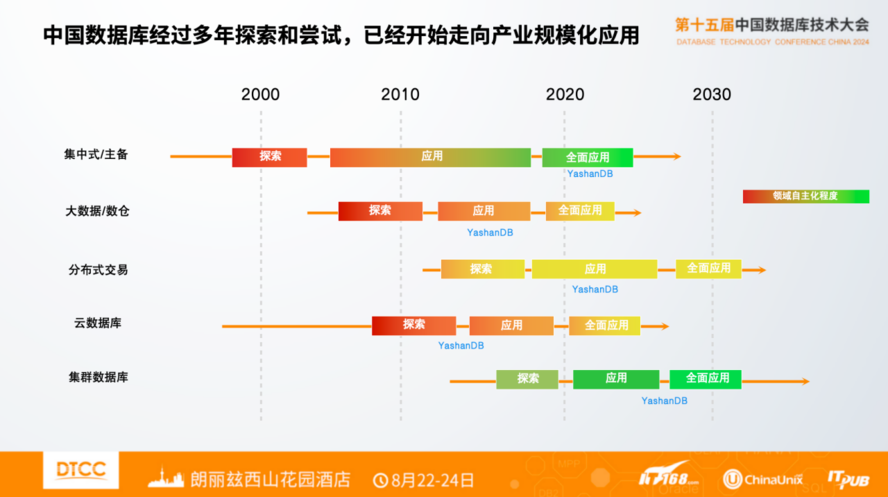
中国数据库市场分为几个领域:集中式数据库,包括主备以及共享集群数据库,以及大数据/数据仓库、分布式交易数据库、云数据库等方向。这里有两个维度的信息:
一是各个领域的自主化程度,颜色表明了自主化的程度。目前,集中式领域,主备和共享集群自主化程度比较高。可能在早期单机和主备经过这么多年的发展自主化程度已经相当高了,但共享集群是比较困难的,国内一些厂商已经开始布局共享集群,并且在一开始就走了完全自主发展的路线。大数据/数仓、云数据库有极强的生态依赖,最初是基于开源生态发展起来,自主方面整体上稍弱。
二是从应用阶段看,经过多年发展,我们看到所有领域都已经开始走向应用或者全面应用阶段,意味着规模化应用诉求不是单领域的,而是全场景都开始有了规模应用诉求。
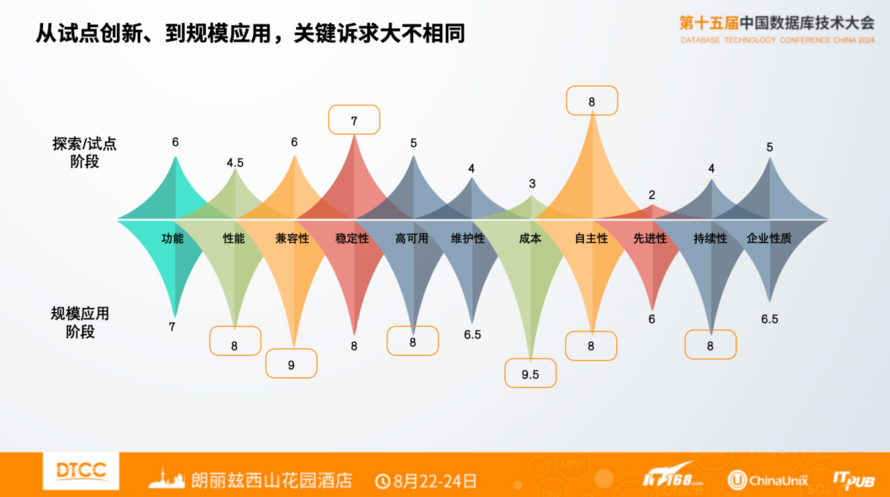
从试点创新到规模应用,对数据库的关键诉求大不相同。比如性能在试点阶段不是关键矛盾,但全行业业务系统有大量数据库需求,规模应用需要大量的机器、需要购买大量软件license,数倍的性能差距,意味着数倍的软硬件投入成本。兼容性方面,单个项目的试点可以不计成本投入,替换一个系统可以用数年的时间、花费数百人月来解决问题,中国有上万家金融机构,有数十万、百万家企业,这些场景都可以用这种方式解决吗?是有很大挑战的。
此外,对于自主以及企业长期可持续性的要求,试点创新阶段和规模应用阶段都有显著不同的诉求。
怎么解决这些问题?
我们去购买任何商品的时候都会有比较朴素的逻辑,会选择买好的、便宜的、耐心的、诚信的产品,这些问题解决掉才能解决通用产品大规模应用的问题。市场终会回归商业本质:选择好的、便宜的、耐心的、诚信的产品。
数据库是通用产品,也遵循同样的逻辑。但是什么是好的、便宜的、耐心的、诚信的数据库产品?
1、什么是好的?
做数据库,技术和架构选型非常困难,涉及很多问题,有不同的技术路线和流派,并不是哪个流派一定就好,哪个架构就是对的。
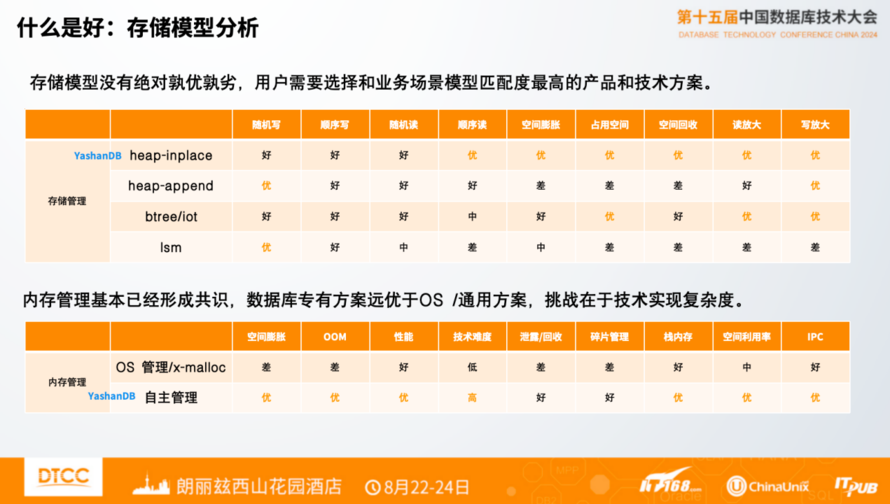
数据库存储引擎的存储模型有不同的方式,基于Heap、基于索引组织表或基于LSM。存储模型没有绝对孰优孰劣,用户需要选择和业务场景模型匹配度最高的产品和技术方案。比如,LSM对于大量随机追加写场景有很好的写入性能,但是可能有很多场景是大量的随机读写同时存在。
内存管理主要有两种模式。一种是使用操作系统内存管理的方案,其特点是可以快速把系统构建起来,但是会带来内存碎片化、以及大规模并发场景下分配内存的性能问题,可能操作系统没有办法很好解决。另一种是数据库自己管理内存,上面的问题能够很大程度上得到解决。但是要投入更多的技术精力,有更高、更难的技术复杂度。
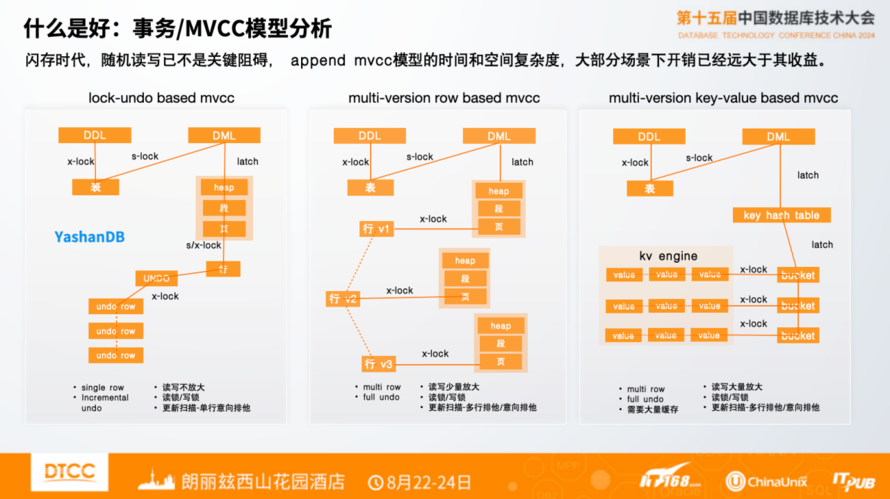
关系数据库的关键之一是事务处理,包括事务的隔离性和MVCC实现,最主要的是两类:第一类基于lock/行锁和undo实现的MVCC,第二类基于数据的多版本,根据时间戳和可见性实现的MVCC。其中基于Heap的多版本还是基于KV的多版本,本质上是一样的。
这两类事务模型的实现对于性能、用户体验和效果有极大的影响。在时间复杂度和空间复杂度两个维度来看,时间复杂度方面,基于多版本的扫描,匹配时间戳解决可见性问题,会带来读放大的问题,时间成本有很大的增长。空间复杂度方面,基于lock和undo的MVCC模型是增量的,数据冗余度远低于多版本,对于空间的利用较好,同时也会有较少的读放大和缓存消耗。在大量事务并发场景,叠加空间合并、回收,两类模型对于空间的消耗也有很大差距。
两种模型对于特定场景的问题各自有比较好的效果,大家需要根据自己的业务场景选择适合的事务模型会事半功倍。
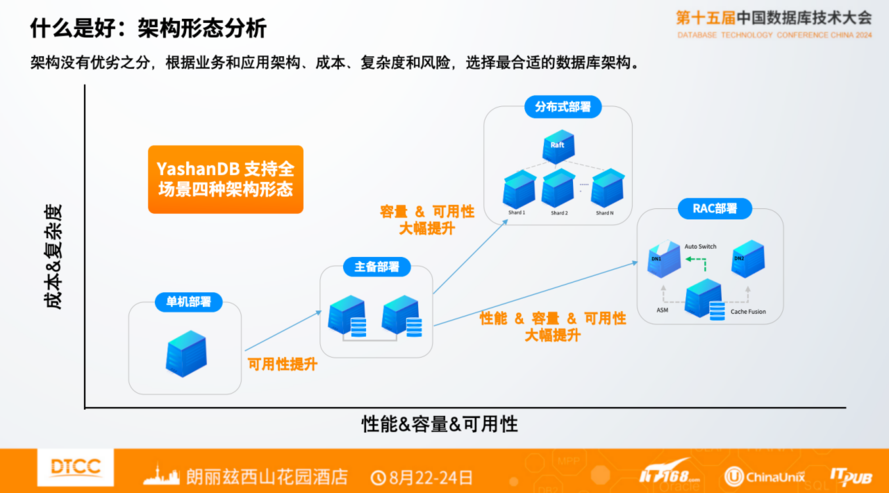
架构方面有单机、主备、分布式和RAC四种部署方式。上面这张图横轴的维度是更好的性能、扩展性、高可用能力;纵轴是代价、成本和复杂度。
从这两个视角可以看到,从单机到主备,再到共享集群和分布式,收益和代价都有质的变化。到底是集中式架构还是分布式架构,经历了漫长的争论和讨论。其实没有说某一个架构适合所有的场景,还是要根据场景来选择。
像办公、OA系统使用单机就可以,单机简单、轻量化、便宜,是够用的。但是有一些场景有高可用的诉求,需要用主备提升高可用能力。对于更复杂的场景,当你有更高性能、高可用要求,有一定扩展要求时,共享集群架构能够很好支撑。比如在数十TB以下场景,包括大行的核心系统,大部分聚焦在这个场景。但是,对于数据规模膨胀到一定程度之后,有数PB、百PB数据,用分布式架构更适合,分布式架构会带来自己的一些制约因素,比如说复杂性大幅度增加,成本也会大幅度增加。
所以这些架构都有自己的用武之地,说未来全部是分布式架构或者全部是集中式架构是不客观的。

对于计算和部署模型,是多层次的,从 NUMA 核到进程模型、再到DC内/跨 DC 部署,越能支持自动适配优化、减少资源开销、支持丰富灵活的模型,对用户越友好。
未来NUMA架构会是主要的应用场景,所有的厂商CPU架构都在往NUMA方向走,是否能够自动解决NUMA架构下性能优化问题,可能直接导致有50%甚至以上的性能差距。
进程和线程模型有各自的优势,Oracle是进程模型的,进程模型更安全,单个进程故障不影响整体。线程模型在大规模并发的情况下有很多资源优势,包括共享缓存池,大量的连接、网络开销有大幅度削减。
对于数据中心内和跨数据中心的高可用问题,也有几个不同方案和层面可以解决。在数据库层面主要是三类,基于物理复制,基于逻辑复制和混合复制。这三种复制模型也有各自的优缺点,物理复制,实时性、一致性能够保持得非常好。逻辑复制,可以处理异构等灵活性问题,但是逻辑复制带来一些问题,比如不能完全保证RPO等于0,在很多核心场景不能接受。混合复制,在很多场景下也有非常强的用途,比如现在数据库在迁移过程中大量存在的场景,客户的应用系统不可能一下子全部迁移完,是一部分一部分增量进行的,必然存异构数据库系统的连接、同步、数据处理问题,混合复制通过逻辑日志和物理日志的转换解决这些的问题。
所以对于跨数据中心架构的也要根据场景选择合适的架构。
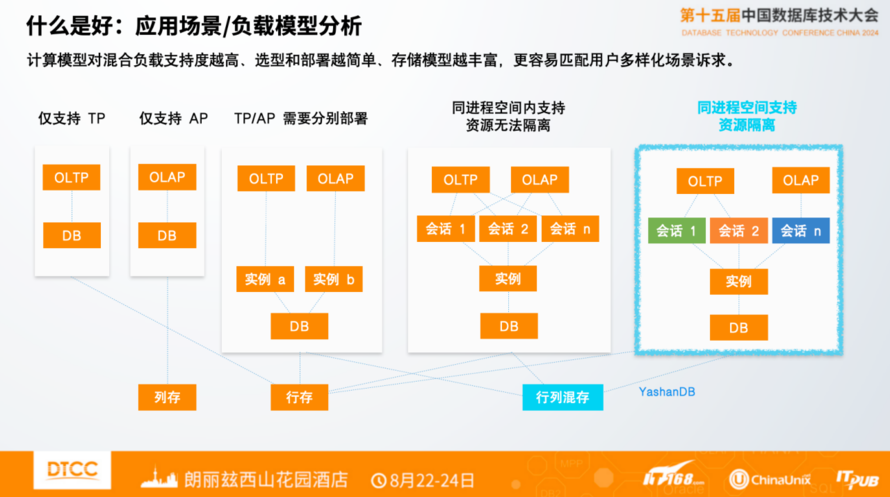
应用场景和负载模型,一直是比较热点的话题,大家有非常多的争论,TP交易和AP分析的负载到底是要分开进行还是合起来进行。不同用户的差异非常大,对于很多小的用户,分析的数据非常少,分析诉求用交易数据库也能够承载,这也就是大家为什么喜欢用Oracle的原因。很多小型的银行,很多AP的负载在Oracle里完全跑得非常好。
负载模型支持,不同厂商有不同的思路和路线。有些厂商专注于做OLTP,有些厂商专注于做OLAP,有的同时支持AP和TP负载。但是同时支持AP和TP负载也有多种模式,最简单的方式是部署成多个实例,为交易部署一套,为分析也部署一套,通过ETL做数据同步和分析。有些厂商可以做到不用分离,可以在同一个进程内,同一个实例支持混合的负载,像Oracle就是支持这种方式。
再更进一步,数据量大的客户会关注,TP和AP放在一起会不会影响正常的交易,资源、任务是不是能够做到很好的隔离,确保交易不受任何影响,能够做到资源的隔离对用户来讲更安全,更可靠。
支持技术的底座也有两种方式,行存和列存,列存用在分析场景较多,行存用在交易场景较多。对于混合负载的场景的支持,有的厂商用行存支持两种负载,行存对于AP的负载性能不是非常好。更好的方式是能够支持行列混存,包括对于表的行列转换,应对TP和AP负载的时候有更高的灵活性,给用户各种场景提供更丰富的方案。对于用户数据库选型,降低技术复杂度,降低成本,不用分别建设、也不用搞那么多技术栈。
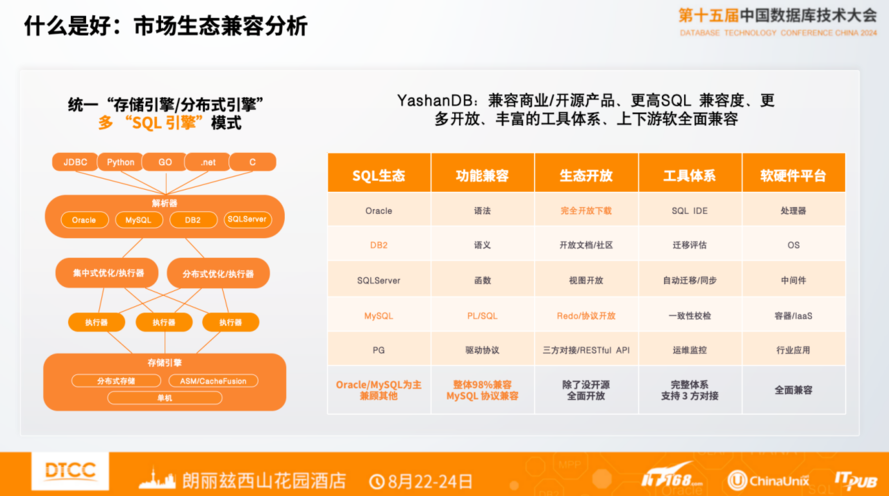
市场和生态,是老生常谈的话题。所有客户应用系统的迁移都避不开这个问题,是否兼容主流的生态,包括SQL生态、功能、工具体系等方面的兼容支持。
现在我们在市场上看到存量的生态还是比较多的,不仅有Oracle,MySQL,还有市场占用率不那么高的数据库,比如DB2、SQL Sever,这些数据库还有不少的存量,对于这些生态是否很好的支持,也很关键。
SQL引擎的支持有不同的方式。有些厂商存储、优化器、分布式这些底层能力是一样的,只是对于生态有多SQL 引擎兼容支持,给用户带来更好的体验,包括用户的使用方式、用户的接口、用户的生态依赖可以有统一的体验和界面。
功能兼容是更高层面的兼容,功能涉及到更高级的能力,比如对于函数、PL/SQL、MySQL协议、对于Oracle OCI接口兼容,也很关键。
再到整个生态开放,你的软件敢不敢让用户用,能不能让用户自由体验,和产品力有极大的关系。当产品力不足的时候会有各种担心,产品力非常强的时候是希望更多用户使用的。比如Oracle的软件包,竞争对手、客户、DBA都可以随意下载使用,我们YashanDB也已经把软件包放在官网上开放下载,大家不需要注册,不需要申请,自己就可以下载体验,这也体现了我们对产品的充分自信。
2、什么是便宜的?
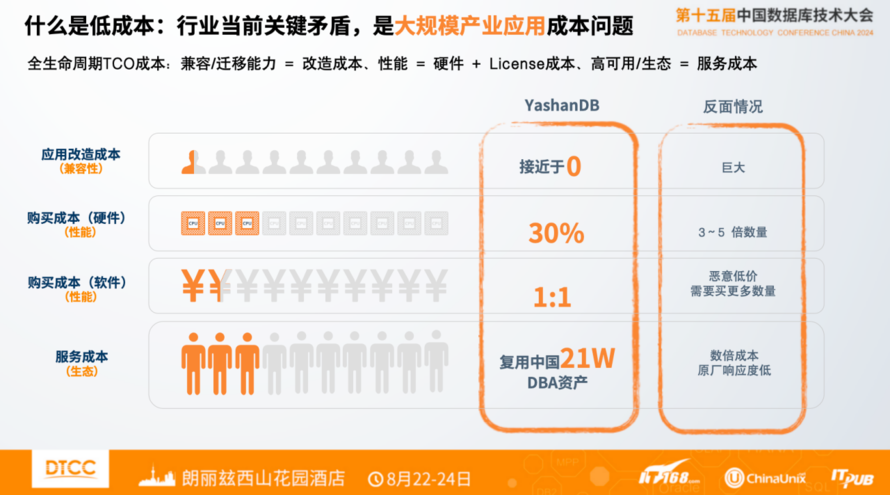
从试点到走向规模产业应用阶段,从用户视角来看,行业当前关键矛盾是成本问题。数据库替换有增量和存量两大类场景:增量场景相对简单一些,数据库本来就要建设,选择国产数据库稍微复杂一点,成本有一些增加,但是不会增加特别多。存量场景怎么办?大量存量场景的替换,不是直接创造业务价值的行为,更需要考虑成本。我们必须提供一个方案,能够以最低的成本完成过去几十年积累的所有应用系统的替换。
数据库大规模应用成本有三个维度构成:
第一,应用改造的成本,本质是兼容性问题。兼容性越好,意味着用户改造成本越低。如果能够很好的兼容主流的厂商,可能95%以上的兼容问题都能够解决,对于用户来讲成本非常低,甚至接近于零,如果做的不好,可能需要投入大量的时间,人力去调优解决这样的问题,对于试点是可以的,规模应用是不行的。
第二,购买成本,本质是性能问题。构建一个业务系统,数据库的投入很大一部分来自于硬件投入和软件投入。原先购买一台机器,一个数据库就能解决的问题,现在如果购买5台或者10台,需要5个或10个license,可能单价便宜一点,但是乘以5或乘以10之后成本大幅度增加,所以很多用户体感是信创的替换体验更差了,价格也更贵了。如果有非常好的性能,可以完全和现有能力的承载做到1比1,甚至1比0.8,比原来做的性能更好,对客户来说成本才能更低。
第三,服务成本,关键是利用现有体系。是否能够把几十年积累的中国20多万DBA利用起来,意味着能否大规模应用后得到完整的服务保障、能否不依赖昂贵的原厂保障,这会对行业规模使用有很大影响。
3、什么是耐心的?

耐心是比较大的话题,本质是要做长期主义,还是解决眼下的问题。做产品要有长期主义、用死力、出慢工、赚取合理利润。
比如开发和运维能力,我们不能总等开源社区去解决,或者交给客户和第三方 DBA 去解决。也不能总拿硬件很便宜当借口,不去精细化利用和管理资源使用和消耗。
比如文档,Oracle的文档很强大,我们需要持续耕耘完善文档、提升产品力,而不是总依赖人肉解决问题。再比如代码和技术资产,有人说不要重复造轮子,利用现有资产就可以,但是假如某一天这个轮子没有供应了怎么办?例如CockrochDB 近期再一次改变了其开源许可证,全面转向企业级许可证。
比如整个公司战略,包括投入可持续性的能力,今年看到有一些厂商面临生存的问题,战略的持续性和投入的保障对于用户来讲至关重要。
4、什么是诚信的?
诚信问题不是原罪,这里有各种各样的因素,根因可能最终还是供需不平衡问题。对于数据库来讲,数据库的研发、测试、跑分、招投标、交付运维等都有不同层面的做法。
研发是只能做封装,做简单的修改,还是能做创新,做内核的演进开发。对于POC测试,只管增量的问题,让客户自己解决大量存量问题,还是能为客户提供完整的解决方案。数据库的跑分,利用各种各样的开关、实验特性,还是能够以生产配置跑出性能。面对大客户和小客户一视同仁,还是区别对待。对于招投标和报价是合理竞争中标,还是恶意把数据库的价格压得非常低,通过其他方式或途径为难用户。交付运维也是一样,产品力不足用人来凑,大规模的情况下如何满足用户需求。
造成现状有各种各样的原因,可能有逐利的原因、投机主义的原因,也有缺少监管等原因,本质还是供需的不平衡。
未来技术出路和商业出路在哪里?
技术方面,供需平衡一个关键点是解决技术、生产力问题。
看能源发展史会发现一个规律。从数万年前钻木取火到畜力,到煤和石油的应用,再到电力、新能源的应用。中国在前两个阶段领先于世界,在中间两个环节有一些落伍。现在通过新能源又走在了世界前列,这里面每个时代的变迁都不是在前一个时代体系下延续和增量完成,都是通过变革才能突破和发展,作为信息载体的数据库同样如此。
从甲骨文到竹简,再到纸张、文件,后来商业数据库提供更好的效率,我们如果在别人构建的框架下发展,意味着这里面的价值和利益都已经被这些厂商拿去了,而如何保持竞争力获得长远发展,还是需要通过自主去解决。
制造手机初期大家都可以利用模块化组件来组装,大家就有一个错觉认为制造手机很容易。数据库也一样,好像通过单机内核、集群管理、数据同步、工具中间件等组件组合,很容易就能够自己开发出数据库产品。但这是组装,不是制造。整个手机制造产业链涉及到很多的技术问题,这些问题的解决非常困难,数据库的研发也是一样,打开之后发现有数十、上百个基础的模块、技术需要掌握和构建,这么多的东西需要自己亲手解决。
数据库技术的出路,是要从组装到产业链,从依赖开源到走向完全自主掌握。

再看商业方面,我们制造出很好的产品,怎么流通到客户手里是非常大的问题。大家知道宁夏的瓜非常好,又甜又大,为什么现在宁夏的瓜买不到?就是流通环节的问题,怎么便宜地流通?
数据库的应用是非常漫长的过程,整个链条远远长于货物的流通,数据库从选型、测试、改造、验证、问题的解决收敛、报价商务、人员技能到未来的运维,这么长的链条是非常脆弱的,任何一个环节出问题,意味着整个链条不能往下进行。
本质上是社会的协同和分工,这么脆弱的长链条,只有拥有很强的信任关系才能运转地很好,否则就会出现:用户本来应该关心自身的业务,现在用户被迫成为“数据库反诈专家”,用户对于数据库每一个问题自己都要弄清楚才不会上当受骗。
数据库的商业出路,社会分工协同的基础是信任,优秀的厂商和产品终会打动用户。
数据库未来要支持大规模的市场应用,随着商业化策略从标杆灯塔工程走向产业规模化应用,市场终究要回归商业的本质:质量好的打败质量差的、便宜的打败贵的、耐心的打败浮躁的、诚信的打败背信的。群雄逐鹿的时代最后,需要大家一起寻求产业共同的生机,探索未来可能正确的出路和方向。
关于YashanDB
去年9月,YashanDB发布了LTS版本,重磅发布了共享集群产品和空间数据库产品。经过一年的努力,崖山数据库有了长足的进步,功能兼容性得到了进一步提升,对主流生态的兼容达到了 95% 以上,云产品、软硬一体化产品将在今年9月全面推出。同时,去年发布的共享集群产品,在今年9月份将会迎来成熟应用能力,经过市场打磨并提供LTS版本支持大规模商用。这个版本在下个月,也将会在官网上全部开放出来,所有人都可以体验使用。
产品技术方面,YashanDB的定位是面向企业核心、自主统一架构管理的数据管理平台。面向企业核心,既可以满足一般系统和外围系统的需求,也能够满足企业核心系统需求。YashanDB是100%完全自主研发的统一架构内核,对代码和技术完全掌握,可快速响应和持续演进。同时,支持面向交易、分析及混合负载等多种应用场景,提供主备、集群和分布式多种产品形态的数据库产品。
在商业化方面,通过近两年市场的应用YashanDB积累了近 200个客户,在这个过程中,产品的成熟度得到了充分验证,也构建起了比较成熟的商业化能力,包括渠道体系、生态体系和服务体系都已经构建起来,形成区域和行业两个维度的大商业支撑体系。
|嘉宾介绍|

王南
近二十年数据库架构设计&内核研发和商业化经历,历任华为GaussDB架构负责人、GaussDB开发总经理、openGauss总经理,蚂蚁OceanBase产品部总经理,目前负责深算院 YashanDB 产品、解决方案和商业化。

