数据基础系列:Lambda架构和Kappa架构

随着每天都会出现不同的应用场景,数据管理者会相应地评估他们的架构设计。有些人坚持使用现代数据堆栈!有些人坚持使用开源解决方案来反抗现代数据堆栈的宣传者,有些人只是尝试解决问题。
无论您代表哪个团队,都有一个共同的问题:数据处理。数据处理模式和工具正在不断变化和发展。在本文中,我将介绍Lambda和Kappa数据处理架构作为数据处理架构决策的基础。
一Lambda架构
Lambda架构是大数据系统中用于处理实时和批量数据的一种设计模式。它由NathanMarz提出,旨在解决低延迟处理大量数据的挑战。
在深入了解架构细节之前,让我们先看看用例,以更好地理解为什么以及在何处需要Lambda架构。
常见的用例:
Lambda架构适用于需要以实时和批处理模式处理大量数据的各种用例。一些常见用例包括:
欺诈检测:检测信用卡欺诈或身份盗窃等欺诈活动需要实时分析大量数据以识别可疑模式和行为。Lambda架构允许组织实时处理流数据以立即检测,同时分析历史数据以改进欺诈检测算法。
物联网(IoT)数据处理:物联网设备会生成大量数据,需要实时处理和分析这些数据才能获得见解并采取适当的行动。Lambda架构可以实时处理物联网数据流,同时还可以执行批处理以进行长期分析和优化。
推荐系统:个性化推荐系统用于电子商务、媒体流和社交网络平台,依靠实时用户交互以及历史数据来生成准确的推荐。Lambda架构有助于处理实时用户交互和历史数据的批处理,以不断改进推荐算法。
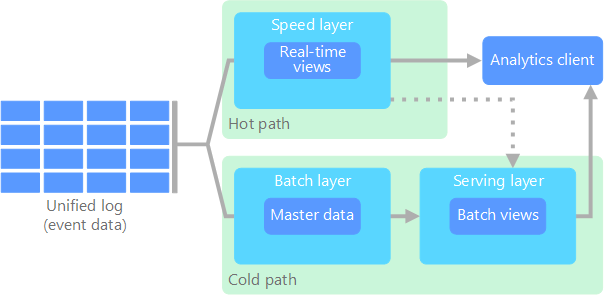
Lambda架构的组成
Lambda架构由3层组成:
批处理层
批处理层负责大批量处理历史数据,并将结果存储在集中式数据存储中,例如数据仓库或分布式文件系统。我们通常将传入数据存储在经过优化、索引且可供使用的视图、物化视图或表中。
批处理层以不可变和仅附加的形式存储数据。这有助于组织保存其历史数据并在需要时访问它。
速度层
批处理层本质上存在延迟。大多数情况下,批处理数据每天更新一到两次。在大多数用例中,它足以继续处理下游用例,但在某些情况下,延迟可能是一个问题。在这方面,我们需要以流式闪存的形式提供数据,以最大限度地减少数据差距。
速度层负责实时数据处理。它以近乎实时的方式处理传入的数据流并生成增量更新。然后,这些更新与批处理层的结果合并,以提供统一的数据视图。速度层的工作是缩小数据创建时间和数据可供查询时间之间的差距。服务层
服务层是访问数据的接入点。它结合了批处理层和速度层的结果,并提供一致的数据视图。数据服务层按照预定义的时间表从批处理层接收批处理视图。该层还接收从速度层流式传输的近实时视图。
二Kappa架构
Kappa架构是一种数据处理架构,旨在提供可扩展、容错且灵活的系统,用于实时处理大量数据。它是作为Lambda架构的替代方案开发的。它通过消除批处理层简化了大数据系统的设计,从而为处理实时数据提供了更简化的方法。
常见的用例:
Kappa架构适用于需要实时处理大量数据的各种用例。一些常见的用例包括:
实时监控和警报:Kappa架构非常适合实时监控系统和应用程序,例如网络流量、服务器性能或应用程序日志。它允许组织在发生异常、性能问题或安全漏洞时检测它们并触发即时警报或操作。
点击流分析:网站和移动应用程序会生成大量点击流数据,需要实时处理和分析这些数据,以了解用户行为、优化用户体验并提供个性化内容或推荐。KappaArchitecture使组织能够实时处理点击流数据流并获得可操作的见解,而无需进行批处理。
供应链优化:Kappa架构可通过实时处理来自库存系统、物流网络和销售渠道等各种来源的数据流来优化供应链运营。它允许组织实时监控供应链绩效、识别瓶颈、预测需求并优化库存水平。
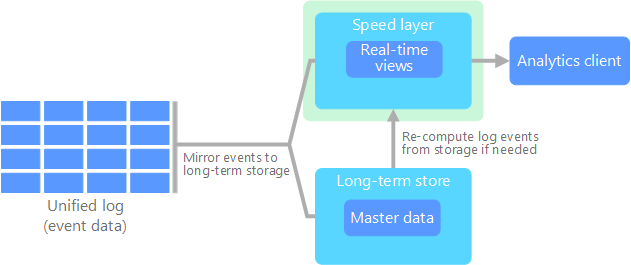
Kappa架构的组成
Kappa架构由两层组成:
数据采集层
该层负责实时收集和提取来自各种来源的数据。数据连续流入系统,无需批处理或预计算。ApacheKafka或类似的分布式消息传递系统等技术通常用于Kappa架构中的数据提取。
流处理层
在Kappa架构中,流处理层是系统的核心。它处理实时数据和历史数据重放。ApacheFlink、ApacheSamza或ApacheStorm等流处理框架用于实时处理数据流。这些框架提供了对传入数据流执行复杂转换、分析和计算所需的功能。
三小结
Kappa和Lambda架构都提供了以实时和批处理模式处理大量数据的解决方案,每种架构都有各自的优势和用例。
Lambda架构具有批处理、速度和服务层,为处理复杂的数据处理需求(包括历史分析和批量计算)提供了一个强大的框架。
另一方面,Kappa架构通过消除批处理层简化了设计,仅专注于实时流处理。这种简化的方法减少了延迟,简化了维护,并为实时数据和历史数据提供了统一的处理模型。
Kappa和Lambda架构之间的选择取决于用例的具体需求,平衡延迟要求、数据复杂性和系统复杂性等因素。

