Oracle AWR报告是分析数据库问题的十分有效的报告,我以前也写过不少AWR报告导读方面的文章。Oracle 12C以后,AWR报告的内容有了较大的不同,增加了很多内容。昨天正好有个网友发来一份做BENCHMARK测试时采集的AWR报告,以此为例,原本想写一篇导读文章,不过时间有限,“导读”写成“导读片段”了,因此今天只能给大家展示其中的一个问题分析的案例,希望今后有机会多写几篇此类的文章,把我对AWR分析的经验传递给大家。
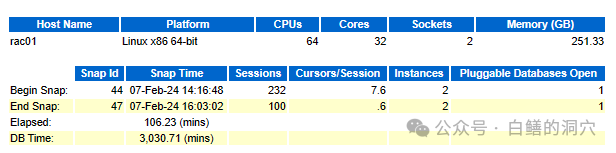
AWR报告中基本上每个数据都是有意义的,忽略上面头部信息的朋友不少,分析一份AWR报告 ,不了解服务器的配置是不行的,很多负载和性能方面的指标依赖于服务器的配置。另外上面的数据里的DB TIME与Elapsed的比值也是很关键的。对于应用变更不是很频繁的系统,对比这个值的变化,对于了解系统总体负载和性能十分关键。
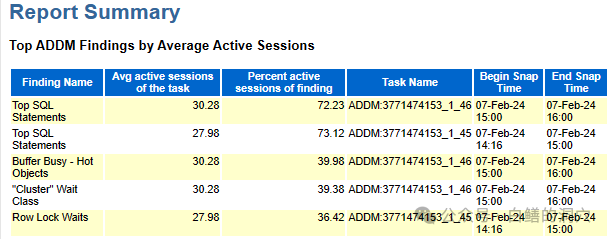
Report Summary是大多数DBA都十分关注的,在12C的报告中,位于C位的是ADDM FINDINGS BY Avg Active Sessions,根据活跃会话情况分析出的系统主要问题可以给DBA一个分析问题的指导性意见。从本案例上看,SQL问题还是最为主要的问题。另外热块冲突、RAC集群和行锁等待是三个十分具体的问题。
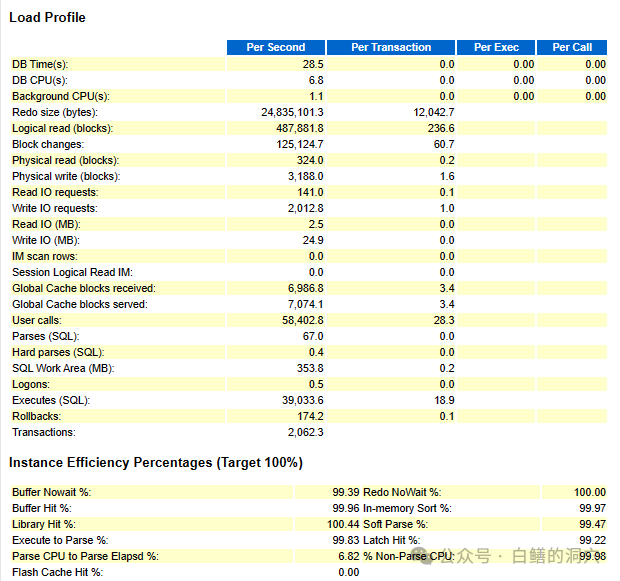
LOAD PROFILE和命中率是DBA最需要关注的细节性问题,从中可以看出一些TOP EVENTS里不一定看得出来的信息。负载永远是分析数据库问题的关键,离开负载谈性能是没有意义的。这里每秒24M的REDO,48.7万的逻辑读,读写IO的吞吐量和流量似乎不高,解析方面也十分合理。每秒3.9万的执行也不算太高,回滚事务数量占比似乎有点高了。而从命中率上看,也是基本正常的。
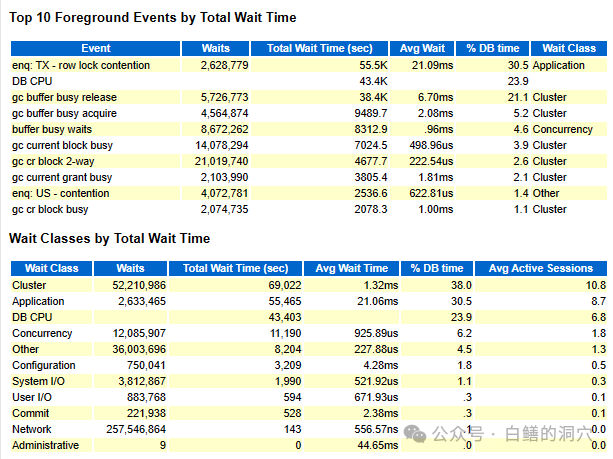
接下来是很多DBA作为C位的Top 10 Events,可以看出行锁平均等待21毫秒,如果在普通的应用系统中算是不错的,不过在BENCHMARK压测场景,这个等待有点高了,可以随后分析。接下来的DB CPU是SQL执行所消耗的所有CPU的统计,随后几个都与集群和热块有关。热块冲突可能是产生这些等待的主因。
接下来是Wait Class的统计,集群等待和应用等待占据了大半部分,从中也可以印证了 对Top Events的分析结论。从集群等待1.23毫秒的平均值上看,这套系统的 RAC集群性能还算正常。USER/IO和SYSTEM/IO都是亚毫秒级的,没有太大的问题。
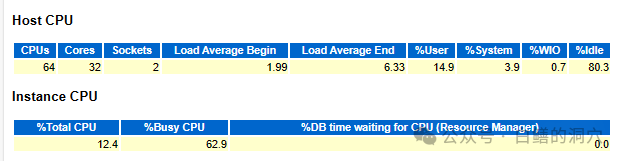
Host和Instance CPU的指标放在这里有点突兀,很容易让人的分析思路被打断或者被忽略掉。如果前面的分析发现系统资源有问题,那么顺便看看这个就很顺,很可能老外的数据库服务器配置都比较节约,经常出现CPU资源不足吧。
Host CPU可以解读为:2路服务器,CPU是16核,32线程的,总共有64线程。SNAP采集时的负载是1.99和6.33,并不算高,不超过CPUS的两倍都不算有明显瓶颈,不超过CPUS的60%,不会因为CPU资源竞争而引起略微的延时增加。其他几个指标大家都看得懂,我就不多说了。
Instance CPU是说实例使用CPU的分解。大家要注意的是最后一个指标,如果这个值很大,说明因为你的资源管理器的配置可能不合理而导致了CPU等待。
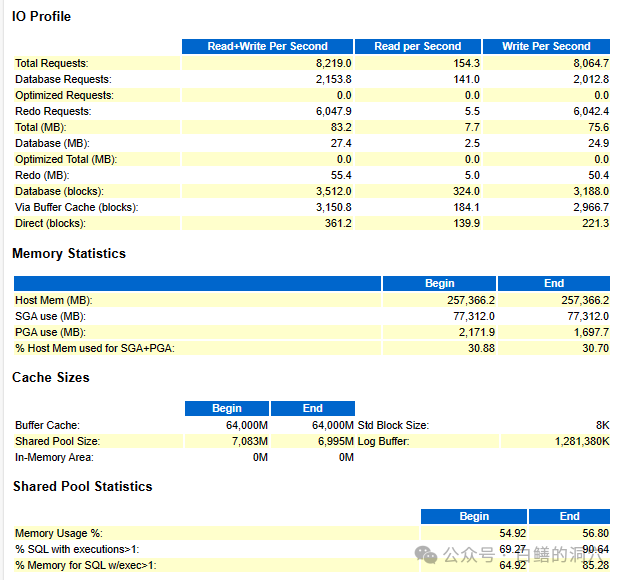
在SUMMARY里最后一部分数据是IO PROFILE和一些内存与一些缓冲区的统计数据。IO和CHACE放在一起还是有一定参考意义的。因为VIA BUFFER CACHE的指标是和DB CACHE配置是否合理紧密相关的。要分析DB CACHE配置是否合理最好参考主报告中的相关内容。

AWR中的这部分内容安排得也十分合理,IO STATS和Buffer Pool Stats是挨着的。
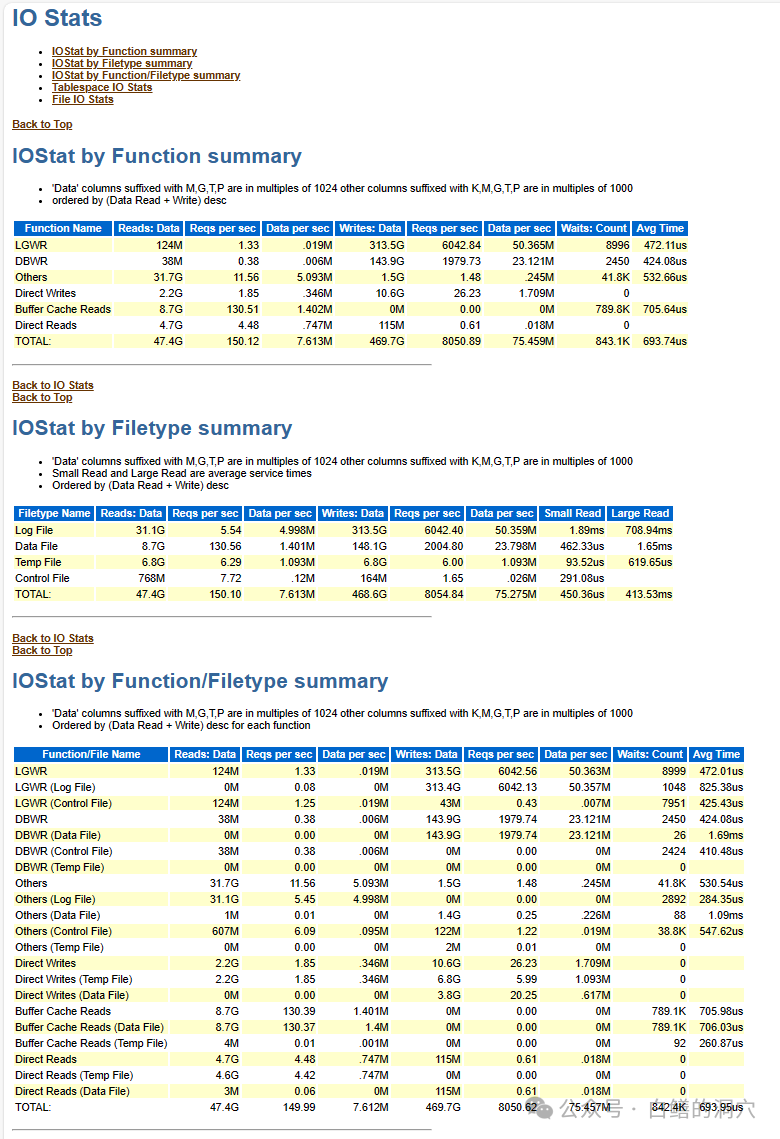
IO STATS里提供了十分丰富的IO分类信息,这里我不一一介绍了。
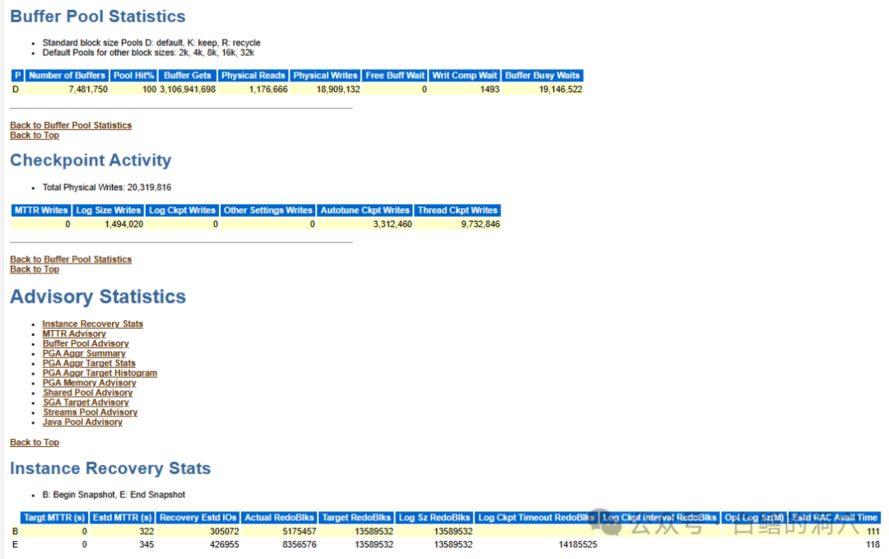
Buffer Pool Stats的每个数据都十分有价值,我们不能仅仅看看命中率,其中Free Buffer Waits指标如果不为零,说明数据库存在无法分配DB CACHE的情况出现,DB CACHE配置过小或者写IO太慢就会引发这个问题。而Write COMP Wait则说明当分配DB CACHE的时候会因为等待DBWR写完脏块后,从LRU-W链中将BUFFER放回主链,要么DBWR写得不够快,要么DB CACHE不够大,要么脏块太多。这里可以看到1493个等待,这样会大幅降低DB CACHE的分配效率,从而加剧BUFFER BUSY WAITS等待。最后一个数值是BBW,就不用我解释了吧。
实际上看到这里,我们是可以看Advisory Stats章节的,不过本报告因为启用了AMM,这部分数据没有内容。
看到这里我们还是很有收获的,因为我们看到了一个和BBW直接相关的一个问题,那就是DB CACHE方面存在的写完成等待问题。如何分析这个问题呢?在这份报告中有几个地方可以对这个问题做进一步的分析。
首先我们来看看实例活跃状态的指标,如果你已经构建起了Oracle数据库的运行状态的知识模型,那么你可以利用这些指标做十分深入的分析,找到其中的不合理数据,从而依托数据库的内部原理去定位问题。在十多年前,我写了一本《DBA的思想天空》,其主要宗旨是让DBA去了解Oracle内部运行的一些基本原理,从而能够利用原理性的东西,去分析你获得的监控数据(特别是AWR数据),从而找到数据库深层次的问题。
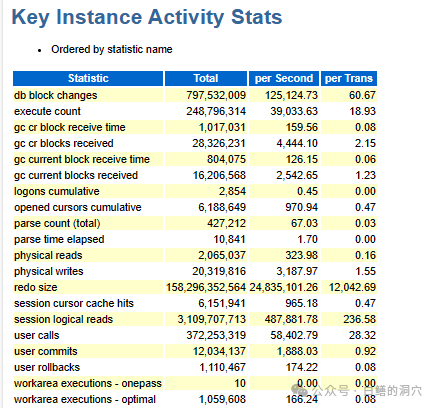
关键指标是Oracle认为对于分析问题最为重要的指标,对于大多数比较明显的问题的分析,通过这些指标就可以有相对直观的了解。对于DBA来说,你可以把这些指标做成数据库的基线(每个数据库实例可能都有不同的基线),当系统出现问题的时候,用这些指标来评估数据库当前的负载。不过我们今天要分析的问题,这些指标对你分析问题的帮助有限,我们还是需要看完整的数据。
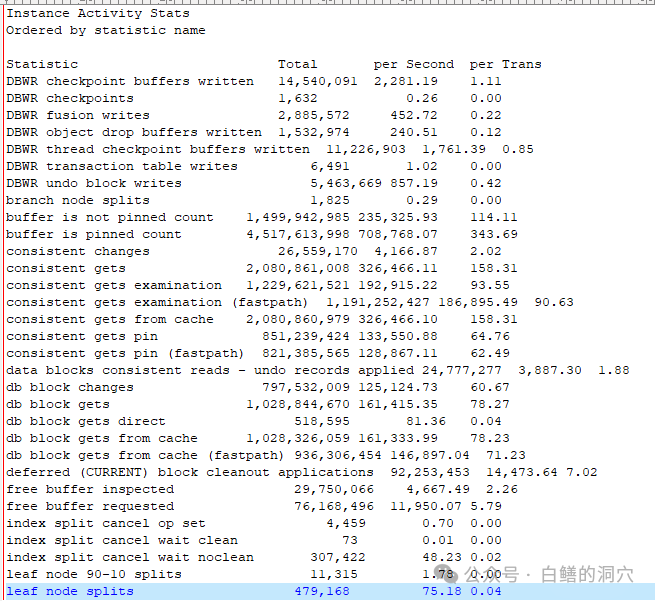
上面这些指标都是和BBW/WRITE COMP WAIT等有关的指标,从指标上看,问题可能是多方位的,DB CACHE存在不足,DBWR写的效率也不算很高,另外索引叶节点分裂过高,一致性度和CR BLOCK读的并发量也很高。遇到这样的问题,优化DB CACHE的配置,实际上对于BENCHMARK测试这样的场景,关闭AMM,合理地调整共享内存配置,调整DBWR的数量,优化分区表的数量,调整索引的PCTFREEE和INITRANS参数等都可以改善性能,进一步提高并发量。实际上在做出调整DBWR相关的结论之前,我们还需要去看看后台写进程的性能,从而确保系统的IO子系统还有提升这方面能力的潜力。
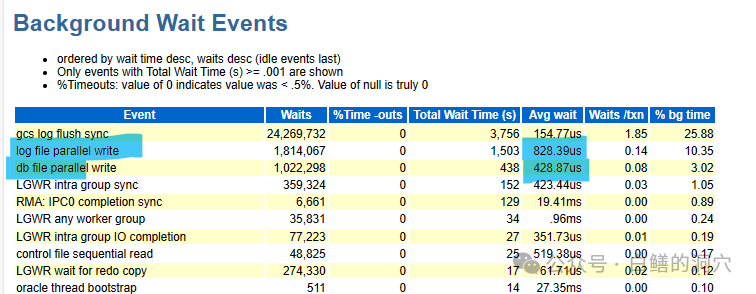
后台jinch的写IO平均延时是我们要十分关注的,从这个案例看,写IO的延时很低,还有进一步提升的潜力。
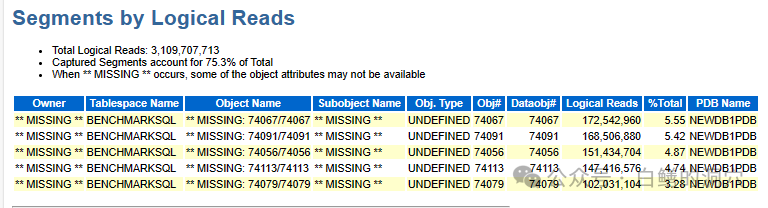
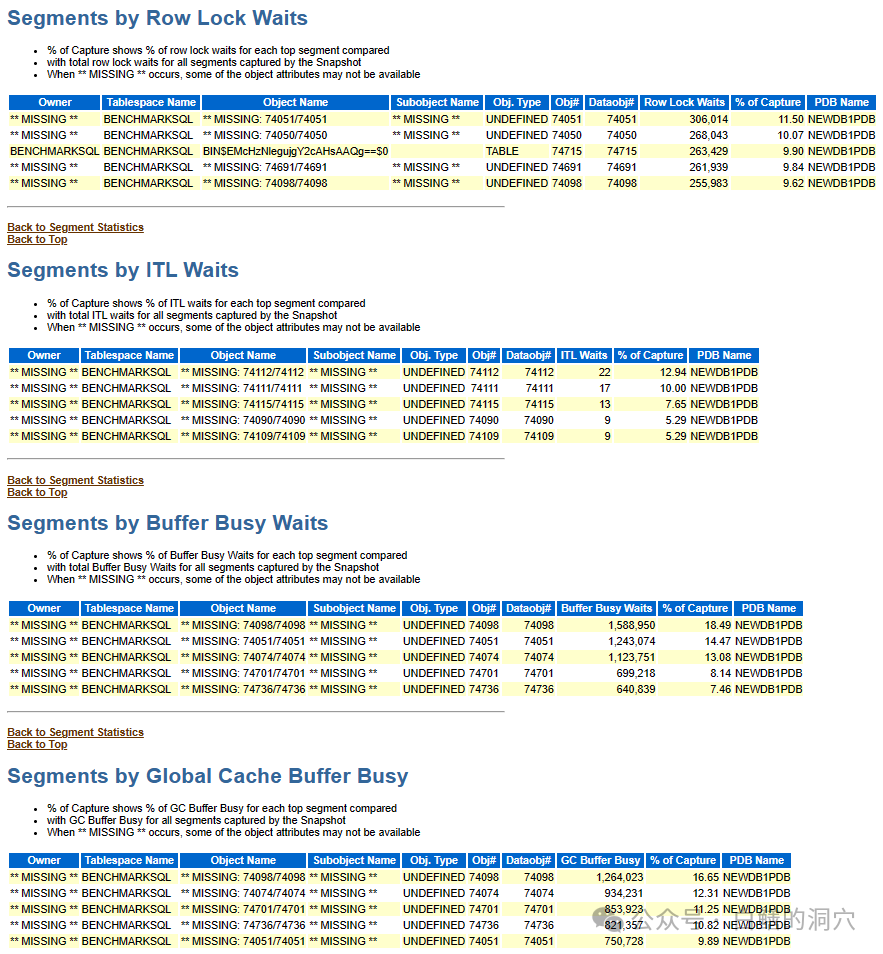
接下来我们可以通过Top Segments来分析哪些对象存在较为严重的冲突和等待,BenchMark测试实际上很清晰,就那么几张表需要调整。可能因为这些表已经DROP了,所以显示出来的都是MISSING。加大PCTFREE,增加HASH分区数量,加大INITRANS都可以有效提升。
马上八点了,今天虽然比平时到公司的时间更早,不过也不足以写一份完整的AWR报告的导读。不过在今早的这个导读中,我们也发现了系统中存在的一些隐藏比较深的影响TPCC的问题。阅读AWR报告曾经是我十分喜欢做的一件事情,有几年时间,我每天的主要工作就是帮助客户和公司的同事阅读AWR报告,并把其中的发现标注出来,与同事和客户讨论,通过远程的分析,帮助用户解决棘手的问题。现在还真有点怀念那段简单而充实的日子。希望今后大家如果遇到什么疑难问题,不妨把AWR报告发给我,我也许能帮你在这些纷繁的数据中找到一些不容易察觉的问题。

