企业如何借实时湖仓赢在“数据制胜”时代?
如果说,Hadoop的出现,标志着企业IT架构进入大数据时代;那么,以实时湖仓为代表的新IT架构,则把大数据推向更现代化的技术栈。
近日,实时数仓专题研讨会以闭门会议的形式成功召开,北京滴普科技有限公司FastData DLink PDT计算引擎部总监张赵中,以《实时湖仓一体平台的落地与实践》为主题,与来自银行、证券、保险、制造、互联网等行业技术高层汇聚一堂,共话实时数仓。

通过Data Mesh实时捞取数据
提到湖仓一体,我们再熟悉不过,和流批一体一样,都是大数据领域前沿概念。问题是,实时湖仓一体概念我们该如何理解?
“大数据技术越来越成熟,企业对数据时效性要求越来越高,之前Hadoop时代的T+1链路已经不能满足业务需求。” 张赵中认为,实时湖仓一体的出现,是大数据技术及企业业务双重推动的结果。
半结构化、非结构化数据的出现,使得原来只能处理关系型数据的Hadoop,出现了难以跨越的鸿沟。首先,时效性差。对于企业管理者以及营销人员来说,更希望实时看到业务数据,而不是T+1天,只能看到事后数据。其次,无法统一管理数据。在传统数据架构下,大量数据无法统一管理、统一运维、统一权限管控。
此种背景下,北京滴普科技有限公司提出一个新概念,那就是类似于网格架构的Mesh。我们可以把Mesh当作是一个数据网格,在这种架构下,用户不需要搬运数据,因为数据本身就散落在各个系统中,然后通过统一的引擎或者技术把元数据给管理起来,在做实时性探查的时候,直接捞取数据就可以了,这也是典型的存算分离架构。
采用Iceberg实现数据统一管理
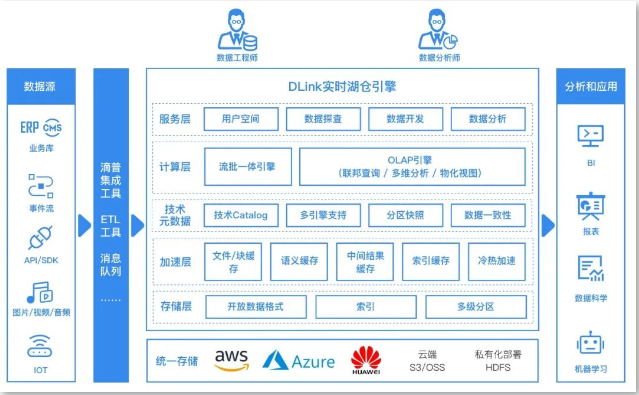
从具体技术架构来看,实时湖仓一体主要分为四层:最底层是数据存储层、再往上是表格式层、数据加速层和计算引擎层。存储层可以是Amazon S3、阿里云OSS、HDFS等,只负责存储;表格式层,需要对数据进行编织,把数据抽象成一个类似于 table format 这种格式;数据加速层,提供的是本地数据缓存和元数据加速服务;最上面一层,是Spark、Flink等计算引擎。实时湖仓一体的本质是,通过四层架构实现了数据的实时流动,包括数据进来如何取,如何算,最后产出结果。
其中,在表格式层会引入湖仓一体的内核技术,包括Delta Lake 、Iceberg和Hudi。Delta Lake在国内的应用比较少,大多数企业会选择Iceberg或者Hudi部署湖仓一体架构。那么,滴普在构建实时湖仓一体技术架构时,为什么要选择Iceberg?
主要基于以下6个原因:
1)支持Schema和分区演进,方便用户灵活的动态调整表结构和分区结构。
2)支持隐藏分区,用户可以不需要指定分区键,即可实现分区过滤的效果,SQL更加智能化。
3)统一的对外接口,不会出现多引擎之间访问不兼容的问题。良好的用户体验,Iceberg 配置参数较少。
4)支持谓词和聚合下推,可以更好地过滤数据,提升查询性能。
5)支持 Python 语言,可以支持机器学习领域的开发,对非结构化数据进行统一管理。比如,通过实时和离线方式把数据拉取到平台上来的时候,如何把元数据给抽取进来,形成一个非结构化数据的元数据层,做统一管理和权限管控,然后进行数据加工,这点非常重要。
6)支持最高的事务隔离级别,支持并发读写,不需要依赖外部组件控制锁。
简单理解,Iceberg最大的优势在于,不会和任何引擎绑定,拥有独立的table format 层。当然,随着技术路线的逐渐成熟,Iceberg和Hudi都在各自补齐,功能都差不多。所以,实时湖仓一体的关键点,不是选择Iceberg还是 Hudi,而是整体架构的落地。
DLink让整库数据流批一体入湖
大体来看,数据入湖这一层,是实时湖仓一体架构搭建过程中遇到的一大痛点。比如:表的动态性做得不够、schema 在变更时不能实现ODS 层同步、不能做断点续传、无法做存量数据和增量数据的一体化等等。
而有了实时湖仓引擎DLink,用户就可以实现整库多表入湖、存量和增量数据的一体化入湖,同时还可以实现运行时的DDL变更(新增列,新增表)等。
当数据从各种业务库数据采集出来,会直接进入DDL处理算子,然后所有变更也会同步,Apply 到ODS层。只不过,DDL 种类很多,有的种类还很危险,用户可以自主选择。但在数仓里,一般不推荐个别动作,比如不会drop数据表。一旦业务库的有些表drop 掉,数仓一般不drop,最多会做一些列删除动作。
另外,构建实时湖仓,少不了表运维能力。因为,既然数据是实时写入,而且又有分区写入,还涉及多长时间 commit (提交事务),导致各种各样的小文件问题出现,同时还涉及数据文件跟删除文件合并的问题……这些问题搞不定,数据湖就“玩不转”。DLink 把这一切过程实现了自动化,在 DLink 上构建后台,可以自动合并小文件任务,让用户忘记繁重的表运维任务,进而实现Iceberg开箱即用。
以某半导体客户为例,这家企业之前是基于CDH(6.3.2)技术栈搭建的大数据平台,每天需要定时去业务库拉数据,然后通过Impala去做查询,再加个Apache Kudu做一些去重的动作。但是,因为数据量庞大,总计20万亿条数据,单表每天5亿条数据,系统架构已经无法支撑。通常是,历史数据还没跑完,当天数据就已经进来了。后来,他们通过DLink平台把表全部建在Iceberg上,在流式数据入湖的时候就实现了流式去重。新系统构建上线后,带来的数据处理速度有了质的提升,之前是T+1,现在控制到2分钟内完成。
技术在不断进步,实时湖仓一体架构也在不断演进。Iceberg本质上是个微批,写一段数据进行commit后下游才可见,如果不这样做,小文件的事务会特别多。所以,为了帮助用户赢在“数据制胜”时代,DLink的下一步计划是,通过Iceberg实现秒级甚至亚秒级的实时数仓。另外,Iceberg未来也不是DLink的唯一内核技术,也正在把Hudi引入进来。最后,自适应实时物化视图功能,也可以解决大部分实时数仓的需求,让数据一层一层地往下流转,实现二级物化视图的再造,进而满足业务数据的实时性处理需求。

