时序数据库在海量地震波形数据分布式存储与处理中的应用
近年来,随着国家对防震减灾工作的日益重视,以及物联网、云计算和地震预警技术的飞速发展,地震监测数据的处理与存储面临着前所未有的挑战。为了满足国家对地震监测的更高要求,我国已实施了多个大型地震监测工程项目,不仅优化了观测台网和仪器,还引入了更多非传统地震计类型的地面运动传感器,从而大大提高了地震实时监测和预警的能力。
然而,随着地震监测台网中的台站数量的大幅增加,从约1300个扩充至15000个以上,地震波形数据的汇入量也将呈现爆炸性增长,由每天约40G增至超过400G。这意味着传统的在单一服务器上处理和存储地震数据的方式已经无法满足现有的需求。在效率、性能和可扩展性等方面,这种方式都存在明显的瓶颈。
当数据量激增后,数据处理效率受限于数据获取的快慢,而获取数据的速度依赖于数据存储方式,传统以文件形式将全部数据集中存储于大的磁盘阵列的方式,其处理效率会受限于服务器读写磁盘的速率。对于实时数据,Kafka、FLINK、Spark Streaming等流式处理框架能够分布式处理高流量、高吞吐量数据,进而降低实时处理延迟。
那么如何通过时序数据库技术,来解决以上问题呢?
为什么是时序数据库
时序数据库已逐渐成为物联网、车联网等领域中存储仪器设备的监控和实时采样数据的重要工具。这种数据库专门设计用于存储时间序列类型的数据,通过将数据按照时间顺序排列,并构造“时间戳|采样值”对,能够高效地管理和查询按时间变化的数据。
在存储结构方面,时序数据库采用按设备编号以列的形式存储数据,每张表及其多个备份分布式保存在多个服务器节点的多块硬盘中。这种分布式存储方式不仅提高了数据的可靠性和可用性,还保证了在部分服务器节点宕机的情况下,系统仍能继续运行并提供数据服务。
确实,随着时序数据需求的增长和技术的发展,不仅有诸如InfluxDB这样的国际知名时序数据库,国内也出现了TDengine、DolphinDB、IoTDB等优秀的自主研发的时序数据库产品。
其中,TDengine、DolphinDB和IoTDB等国内产品在读写、聚合查询和压缩性能等方面均展现出了与InfluxDB相当或更高的性能。这是一个非常重要的里程碑,因为这意味着国内的技术研发能力已经达到了国际先进水平,甚至在某些方面有所超越。
除了核心性能外,这些国内时序数据库与早期的实时数据库相比,也有了明显的架构优势。过去的实时数据库大多只支持一主多备的模式,而现在的时序数据库如TDengine和IoTDB等都支持集群和线性扩展。这意味着它们不仅可以处理更大的数据量,还能在需要时轻松扩展存储和处理能力,满足更为复杂和大规模的应用需求。
集群支持使得这些时序数据库可以部署在多个服务器节点上,每个节点都可以处理和存储数据,从而大大提高了整个系统的吞吐量和容错能力。而线性扩展则意味着当数据量或访问需求增加时,只需简单地增加更多的服务器节点,就能成比例地提高系统的处理能力。
地震波形处理需要时序数据库的哪些技术优势?
为了能够较好地解决波形数据量激增所带来的存储和处理瓶颈,中国地震陈通表示,时序数据库可以为未来地震预警中心海量波形数据的高效存储和处理探索新途径。
高速数据写入:地震台站产生的海量波形数据需要数据库具备强大的写入能力。时序数据库采用特殊的存储结构,结合内存表和消息中间件技术,确保每秒数百万条记录的高速写入,满足实时接入大量台站的数据需求。
高数据压缩率:地震数据需要长期保存,因此对存储空间的优化至关重要。由于地震波形数据的特殊性,时序数据库能够实现高效的数据压缩,降低硬盘空间需求,或在有限的存储空间内保存更多的数据。
快速响应机制:通过对数据进行分级存储,时序数据库确保了实时数据的快速访问。热数据存储在内存或高速缓存中,温数据保存在SSD硬盘中,而冷数据则存储在机械硬盘中。这种存储策略保证了数据的快速检索和查询。
多功能集成:时序数据库不仅仅是一个数据存储系统,它还将消息队列、内存缓存、流式计算等功能集成在一起。这种集成策略简化了数据处理流程,降低了性能损耗,并为实时全量数据处理提供了一个更为简洁的方案。
自定义函数和插件支持:为了满足地震数据处理的特殊需求,时序数据库允许用户定义自己的函数或插件,并在数据库内部执行这些函数。这为地震数据处理提供了更大的灵活性。
多种触发机制和流式计算支持:地震数据处理往往需要基于时间或数据事件的触发机制。时序数据库支持多种触发机制,如数据事件触发、时间窗触发和定时触发,并能保存和处理过程中的历史状态。这为复杂的地震实时处理需求提供了有力的技术支持。
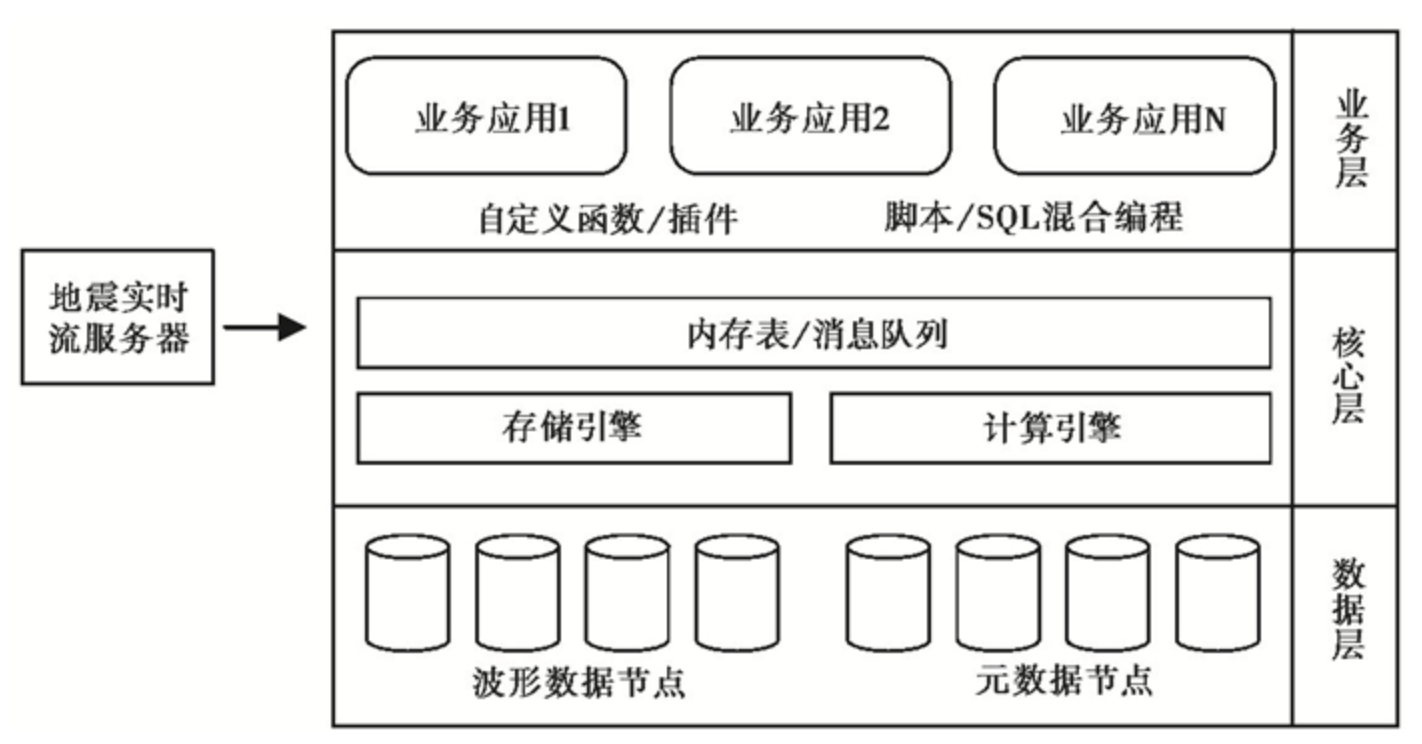
地震时序数据库系统的架构分为三个主要层次,如图1所示。这种设计旨在确保系统的可扩展性、高效性和灵活性,以满足地震数据处理的各种需求。
数据层:
位于架构的最底层,负责直接与硬件存储交互。
包括多块本地磁盘,用于存储原始的地震波形数据和相关的元数据。元数据提供了关于数据包的关键信息,如到达时间、采样起始时间和采样点数量等,这对于后续的数据处理和分析至关重要。
核心组件层:
该层是时序数据库的核心,负责数据的实时接入、缓存、计算和存储。
内存表和消息队列为实时数据提供缓存空间,确保数据在写入磁盘前能够得到快速处理。
计算引擎执行基于数据流的触发计算、滑动窗计算等任务,而存储引擎则优化磁盘的读写操作和数据检索速度。
业务层:
位于架构的最上层,是直接与用户和应用程序交互的界面。
时序数据库在这一层提供了自定义函数和插件的功能,允许用户根据特定的地震数据处理需求进行定制开发。
通过脚本和SQL查询语句的混合编程,用户可以创建复杂的地震数据处理流程。
这种三层的架构设计确保了地震时序数据库系统的高效运行、易于扩展和灵活性,使其能够满足各种地震数据处理和分析的需求。
总结来说,地震时序数据库既拥有大数据集群系统的高可用性,同时又对地震波形数据的存储和检索进行了优化,对分析处理海量波形数据工作具有较好的应用前景。

