ChatGPT 越来越笨了吗?
机器能够学习并随着时间的推移变得更好,这是现代人工智能的一大卖点。但8月初发布的最新研究表明,随着时间的推移,ChatGPT 在某些任务上的表现实际上可能越来越差。
根据斯坦福大学和加州大学伯克利分校研究人员的论文初稿,在支持ChatGPT 的OpenAI 大型语言模型(LLM)GPT-3.5 和 GPT-4 的结果中检测到了相当大的漂移。
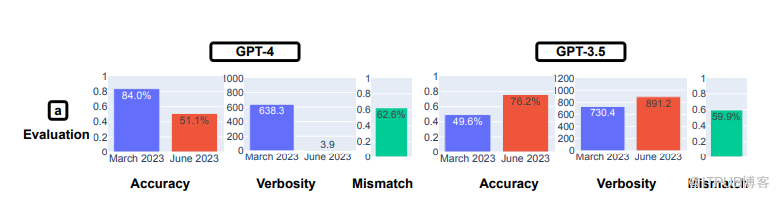
斯坦福大学和加州大学伯克利分校的研究人员指出,从 3 月到 6 月,GPT-4 的数学成绩有所下降,而 GPT-3.5 的数学成绩则有所上升
这三位研究人员包括斯坦福大学的助理教授Matei Zaharia、加州大学伯克利分校的Lingjiao Chen和James Zou,前者是 Databricks 的联合创始人,也是 Apache Spark 的创建者。
研究人员在人工智能任务测试平台上运行了四个模型,包括数学问题、回答敏感/危险问题、回答民意调查、回答多跳知识密集型问题、生成代码、美国医疗执照考试和视觉推理。
结果表明,LLM 所给出的答案差异很大。研究人员发现,6 月份版本的 GPT-4 在回答数学问题时的表现尤其不如 3 月份版本。通过思维链(COT)提示正确识别质数的准确率显示,GPT-4 的准确率从 3 月份的 84.0% 降至 6 月份的 51.1%。与此同时,GPT-3.5 在同一测试中的准确率从 3 月份的 49.6% 升至 6 月份的 76.2%。
作者思考了 GPT-4 的准确率下降如此之多的原因,发现 COT 行为有所不同。3 月份的版本将任务分解为多个步骤,正如研究人员所要求的 COT 提示。然而,6 月份版本的 GPT-4 没有给出任何中间步骤或解释,只是将答案(错误地)生成为 “否”。(研究人员指出,即使 GPT-4 给出了正确答案,它也没有显示自己的工作,因此也会出错)。
第二道数学题也出现了类似程度的偏差:找出快乐数(happy number)(快乐数是数学领域术语,研究人员写道:“如果一个整数反复被其数位的平方和替换,最终产生 1,那么这个整数就被称为快乐数”)。研究人员写道,他们“在这项任务中观察到了明显的性能偏移”,GPT-4 的准确率从 3 月份的 83.6% 降到了 6 月份的 35.2%。GPT-3.5 的准确率则从 30.6% 上升到 48.2%。再次观察到 GPT-4 没有按照研究人员发出的 COT 命令进行操作。
当研究人员向 LLM 提出敏感或危险问题时,也观察到了变化。随着时间的推移,GPT-4 回答问题的意愿有所下降,从 3 月份的 21.0% 下降到 6 月份的 5.0%。相反,GPT-3.5 则变得更加健谈,从 2.0% 上升到 5.0%。研究人员总结说,OpenAI 在 GPT-4 中采用了“更强的安全层”,而 GPT-3.5 则变得“不那么保守”。
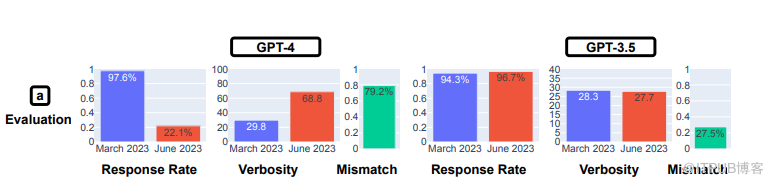
斯坦福大学和加州大学伯克利分校的研究人员说,从 3 月到 6 月,GPT-4 参与民意调查的意愿有所下降
意见调查测试表明,GPT-4 的意见提交率明显下降,从 3 月份的 97.6% 下降到 22.1%,而字数(或字数)增加了近 30 个百分点。GPT-3.5 的回复率和字数几乎保持不变。
在回答需要“多跳推理”的复杂问题时,发现了性能上的显著差异。研究人员将具有提示工程能力的 LangChain 与用于回答多跳问题的 HotpotQA Agent 相结合,结果发现,在生成完全匹配的答案方面,GPT-4 的准确率从 1.2% 提高到了 37.8%。不过,GPT-3.5 的“完全匹配”成功率从 22.8% 降至 14.0%。
在代码生成方面,研究人员发现两种 LLM 的输出结果在可执行性方面都有所下降。3 月份,GPT-4 超过 50% 的输出可直接执行,而 6 月份只有 10%,GPT-3.5 也有类似的下降。研究人员发现,GPT 开始在 Python 输出中添加非代码文本,如额外的撇号。他们推测,额外的非代码文本是为了让代码更容易在浏览器中呈现,但却使代码变得不可执行。
在美国医学执照考试中,GPT-4 的成绩略有下降,从 86.6% 降至 82.4%,而 GPT-3.5 下降不到 1 个百分点,降至 54.7%。然而,随着时间的推移,GPT-4 答错的答案也发生了变化,这表明随着 3 月份的一些错误答案得到纠正,6月份LLM从正确答案变成了错误答案。
视觉推理测试在两个模型中都有小幅改善。不过,总体准确率(GPT-4 为 27.4%,GPT-3.5 为 12.2%)并不高。研究人员再次观察到,这些模型在之前正确回答的问题上产生了错误答案。
研究人员写道,测试结果表明,GPT-3.5 和 GPT-4 的性能和行为在短时间内发生了显著变化。
“这凸显了对应用程序中 LLM 漂移行为进行持续评估和评价的必要性,尤其是因为 ChatGPT 等 LLM 如何随时间更新并不透明。”研究人员写道,“我们的研究还强调了统一提高 LLM 多方面能力的挑战。提高模型在某些任务中的性能,例如对额外数据进行微调,可能会对其在其他任务中的行为产生意想不到的副作用。相应的,GPT-3.5 和 GPT-4 在某些任务上的表现越来越差,但在其他方面却有所改善。此外,GPT-3.5 和 GPT-4 的变化趋势往往是不同的。”
原作者:Alex Woodie

