本文整理自DTCC2022大会上字节跳动研发工程师陈超的演讲“字节跳动图数据库架构演进——索引与执行优化”。陈超老师深度参与了 ByteGraph 开发到上线以及后续的迭代演进。目前主要负责 ByteGraph 存储层的开发工作。
总体来看本次分享分为三个部分:一是ByteGraph的介绍,包括ByteGraph可以做什么,Gremlin查询接口和举例以及ByteGraph业务介绍;二是ByteGraph架构,分为查询引擎和存储引擎;最后介绍ByteGraph过去面临的关键问题,包括图局部索引、全局索引、分布式事务、重查询优化、写放大优化和在离线生态。

1 ByteGraph介绍
1.1 ByteGraph可以做什么?
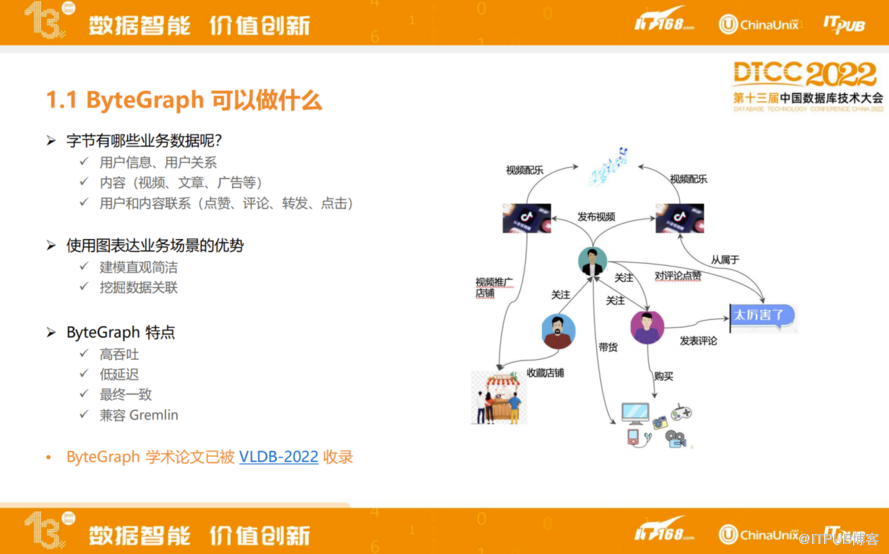
如图,字节跳动共有三类数据,分别是用户类、内容类(视频、文章、广告等)、用户和内容之间的联系(点赞、评论、转发、点击)。
使用图表达业务场景有不少优势,建模直观简洁,能更好地挖掘数据关联。ByteGraph是字节跳动自研的分布式图数据库存储系统,支持有效图模型,支持Gremlin查询语言。具有高吞吐、低延迟、最终一致等特性,读写吞吐可以扩展到千万QPS,ByteGraph一些学术论文已经被数据库VLDB-2022收录。目前ByteGraph已经部署了1000多个集群,遍布全球多个机房,支持头条、抖音、西瓜、知识图谱等。
1.2 Gremlin查询接口和举例

Gremlin是一种图灵完备的图遍历语言,是Apache子项目之一,规定了Gremlin一些不同算子所涉及到的查询语义,但是具体实现不会有硬性限制,所以在不同的厂商对于Gremlin的标准会有自己的实现。
目前,ByteGraph支持Gremlin查询子集可以覆盖到80%左右,ByteGraph数据模型有向属性图模型,在点和边上都可以携带多属性,以及动态加减属性列。通过上面几个例子可以看出Gremlin图查询语言非常接近于自然语言。
字节跳动内部有非常具体的案例,Gremlin如何表达不同类型的查询。
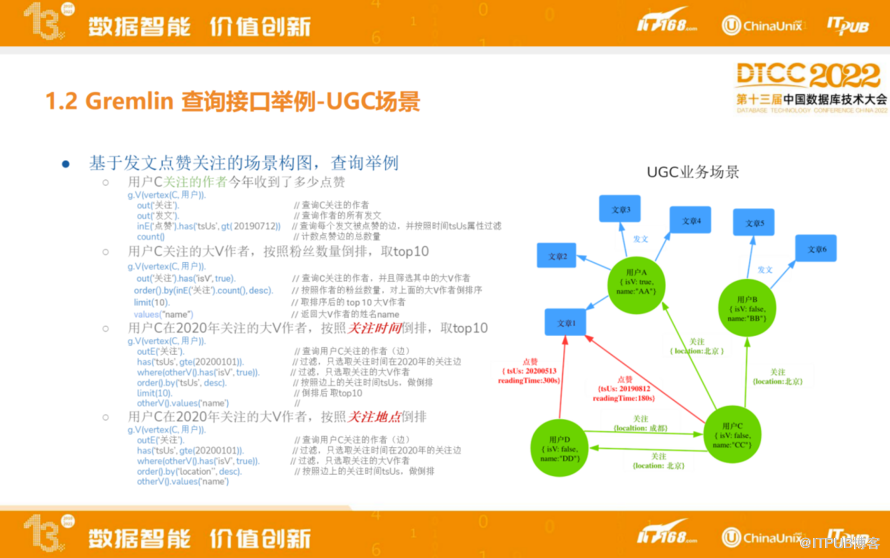
如图,基于发文点赞关注的场景构图,查询举例,
用户C关注的作者今年收到了多少点赞。
用户C关注的大V作者,按照粉丝数量倒排,取top10。
用户C在2020年关注的大V作者,按照关注时间倒排,取top10。
用户C在2020年关注的大V作者,按照关注地点倒排。
通过以上的案例,可以看到基于Gremlin查询的写法,相当于SQL来说相对简单直白。
以下是ByteGraph内部扩展场景,跨集群、跨表查询,为内部业务场景提供支持。
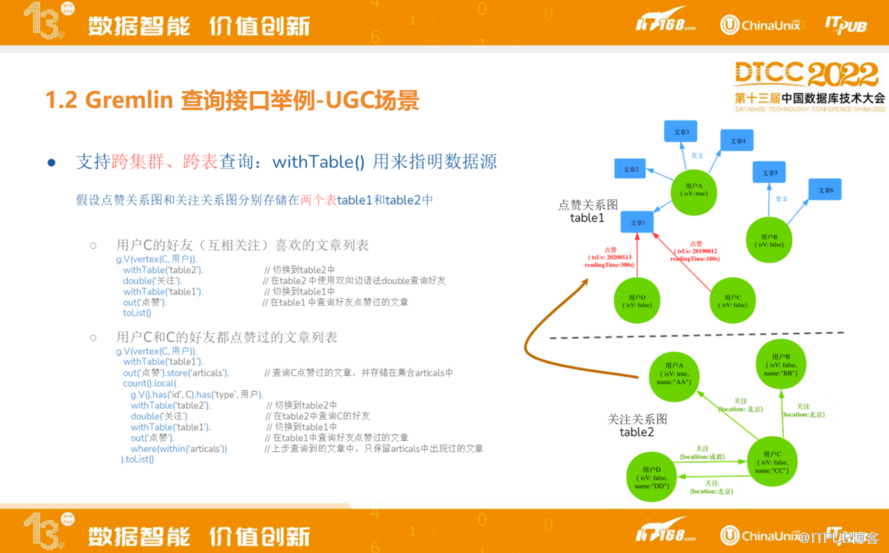
如图,用户点赞和发文以及用户关系是在两个不同表甚至两个不同集群里,左边两个例子分别是求用户C的好友里喜欢的文章列表,以及用户C和C的好友都点赞过的文章列表。这两条里都需要提到的是ByteGraph新增withTable()这种限定语法用来支持Gremlin跨表查询。
1.3 ByteGraph业务介绍
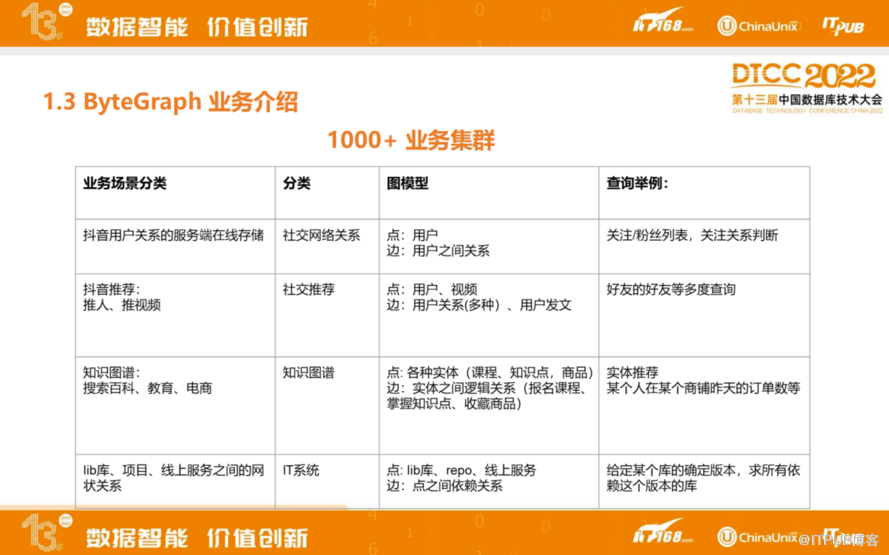
目前ByteGraph支持了超过1000多个业务集群,服务器规模已经达到上万台。最开始时,ByteGraph用来存储抖音用户关系在线存储,比如好友关系,以及粉丝列表等。有了这些用户互动基础数据之后,也会基于这些基础数据去做推荐,比如抖音推荐、推人、推视频等,基于好友的好友这类多跳查询做关系的挖掘以及关联关系的分析等算法上的内容。
ByteGraph也会应用在知识图谱领域,支持搜索百科、教育团队以及电商团队,去做实体的推荐。除此之外,在IT系统上用图模型去抽象代码仓库的依赖关系,或线上服务之间网状关系等。
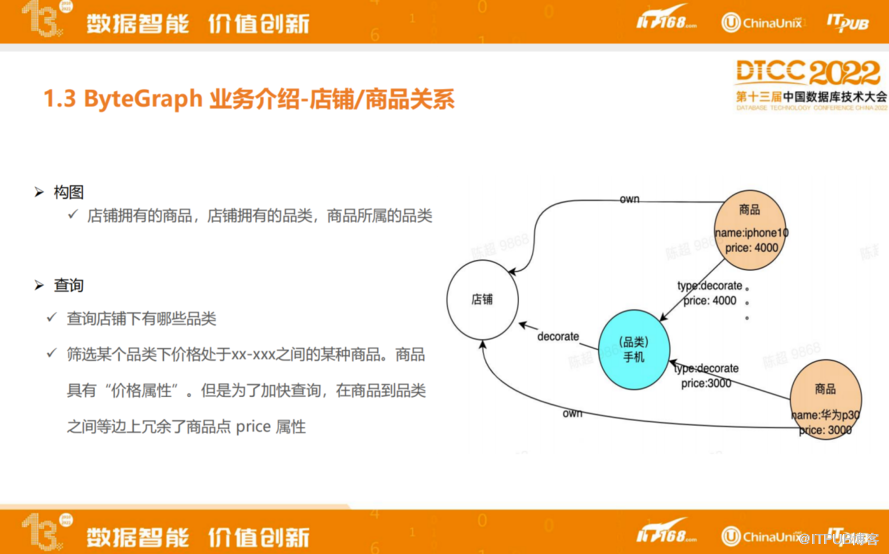
实际案例,如电商业务构图,基于店铺所拥有的品类以及商品所属的品类进行构图,在图上可以做各种各样的查询。例如查询店铺会有哪些品类,还可以用来筛选某个品种类价格处于某一个范围的某种商品。关于第二种查询有一个小技巧,价格本来应该是点上的属性,但是为了加快查询,在商品到品类之间的边上冗余商品点价格的属性,就不用再多次查询每个点属性,从而提升了性能。
2 ByteGraph架构
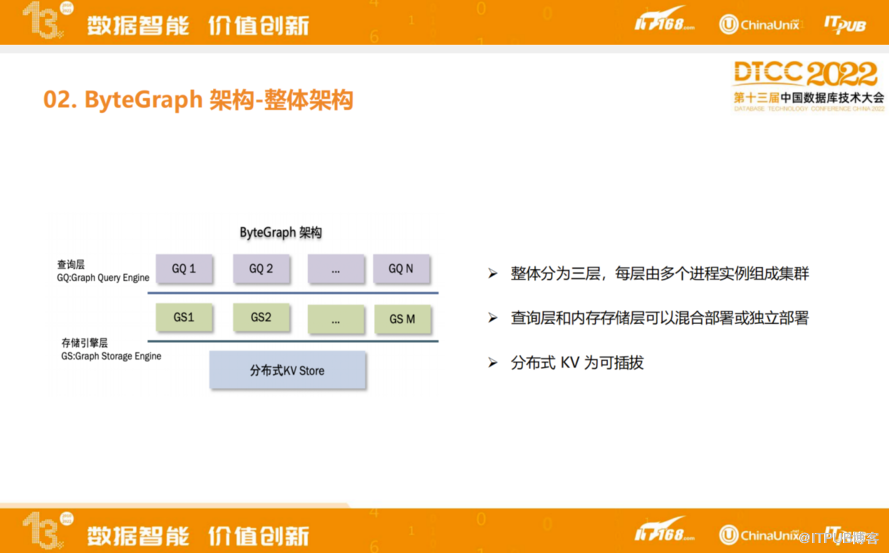
ByteGraph整个系统架构分三层:分别是查询引擎层、存储引擎层、磁盘存储层。三层之间相互独立,每一层都可以进行水平扩容。查询语义非常复杂,可能涉及到步骤数量比较多,所以是计算量比较重的查询,但是内存存储开销比较少一些,所以可以开启更多查询引擎层,开更少存储引擎层。
整体上ByteGraph是基于非常经典的计算存储分离架构去做的,最底层是分布式KV,分布式KV用内部第三方KV存储系统,从设计上来讲,KV引擎可以用热插拔形式做更替,只需要具备基本的KV接口就可以替换。
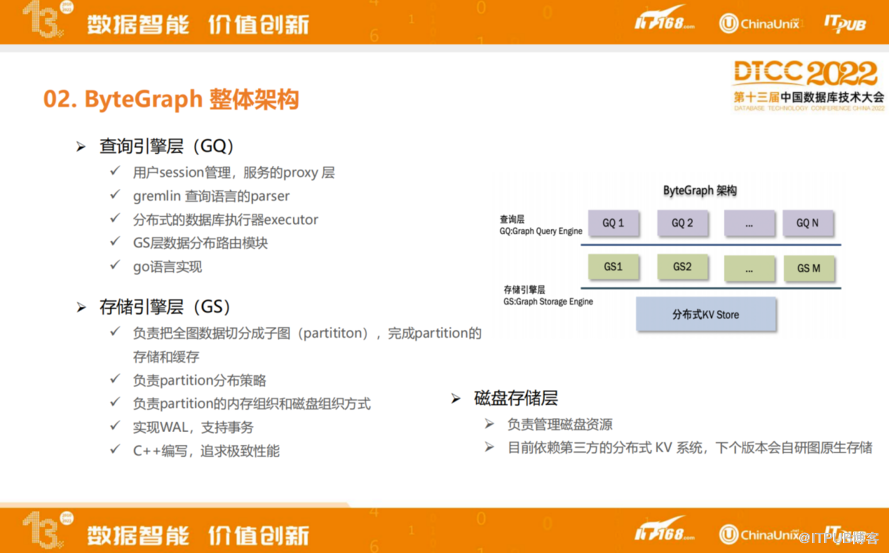
查询引擎层主要涉及到用户session管理,服务的proxy层,Gremlin查询语言的parser,分布式的数据库执行器executor,目前用Go语言实现,比较注重高并发的问题。
存储引擎层涉及到存储,模块中涉及到如何把全图数据进行切片,称每个切片为一个partition,每一个partition代表一个子图数据,要有相对而言比较良好、比较低的读写放大能力,以及需要考虑到能够在磁盘上组织形式对磁盘比较友好,如何实现这一数据结构也是ByteGraph比较核心的设计。为了保证数据不能丢失,在存储引擎层支持WAL,通过两阶段提交的方式支持事务,存储引擎层用C++编写。
最下面是磁盘存储层,目前依赖公司第三方KV Store,下个版本也会自研一些图原生的存储引擎。
2.1 ByteGraph架构-查询引擎
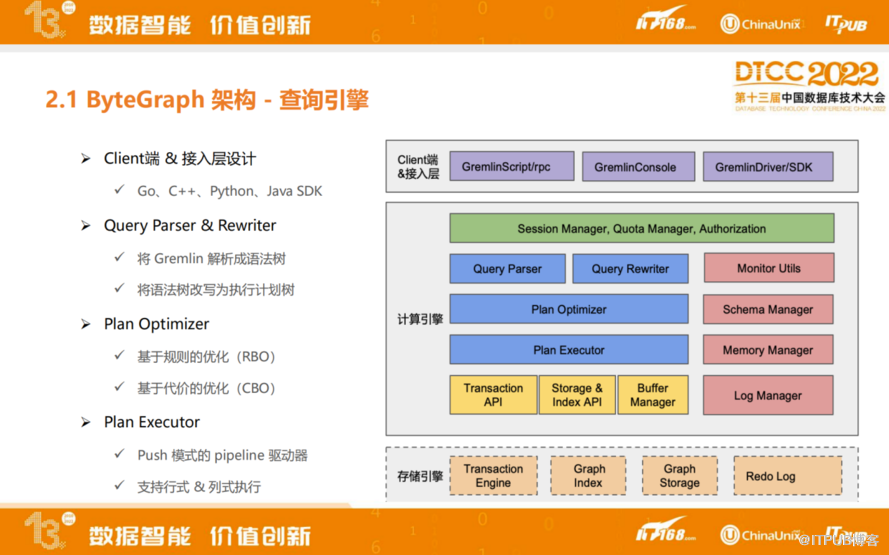
详细介绍一下查询引擎内部的实现细节,分为四层:
最上面一层是客户端以及接入层设计,是数据库使用的入口,提供各种语言API接口,命令行交互的查询接口等。这一层除了提供基本的增删查改接口,还提供流量管理、权限认证等功能。
第二层是Query Parser&Rewiter,这个模块功能主要是将客户端提交的Gremlin解析成语法树,以及将语法树改写成执行计划树。
第三层是优化器模块,Gremlin是一种函数式的编程语言,和其他的编程语言一样,实现逻辑可能会有各种不同等价的表达式,而不同的表达式对应执行计划的代价不同。目前采用一些优化规则主要是基于规则的优化(RBO),以及基于代价的优化(CBO)两种优化规则相结合优化Gremlin查询。
第四层执行器模块,选定比较高效的执行计划之后,会交给执行器去执行,执行器有两个特点,主要是由Push模式的pipeline去驱动,支持行式和列式两种执行模式。

在查询引擎查询层(GQ)和MySQL的SQL层一样,主要工作是做查询的解析和处理,查询引擎首先要做Parser,将查询语言解析成查询语法树,然后生成查询计划。例如一个带索引的查询进来之后,在存储层已经建立了索引之后,这个查询就不应该放到查询层去做,而应该放到存储层去做,这里也会涉及算子下推的优化。
为了防止查询计划多次生成,某一个查询计划基于某一个模板情况下有相关的缓存,生成相关查询计划之后,接下来让GQ层和GS层进行交互,查询的时候算子之间有一个依赖关系,能并行做执行尽量并行去做,不能并行只能串行去查询。同时GQ层会在查询时去理解存储层上分片的逻辑,找到对应的数据。

ByteGraph查询优化分为两类:基于规则的查询优化以及基于代价的查询优化。
基于规则的查询优化中,ByteGraph使用了如下规则,比如在语法改写方面,基于Gremlin开源实现,实现对应简单语法改写等常见优化。通过数据预取以及子查询消除的优化,可以减少不必要的数据访问开销。
基于代价的优化中,统计点的出度,以网络通信成本、计算成本和磁盘读取成本计算查询代价。比如要查我关注的人里哪些人也关注了他,这里有两个执行计划,执行计划A做两跳的扩展,先找到A的一度邻居,让一度邻居再去找A的二度邻居,看多少人当中会是需要筛选的B。另外一种方式是找到A的一度邻居之后,再找B的一度邻居,依赖这样的次序去做大小表的join。在不同情况下,A和B有不同的查询代价,大多数查询B会是更优的执行方式。但是也有例外,如A的出度比较小,B的出度比较大,A会是更优的执行方式。
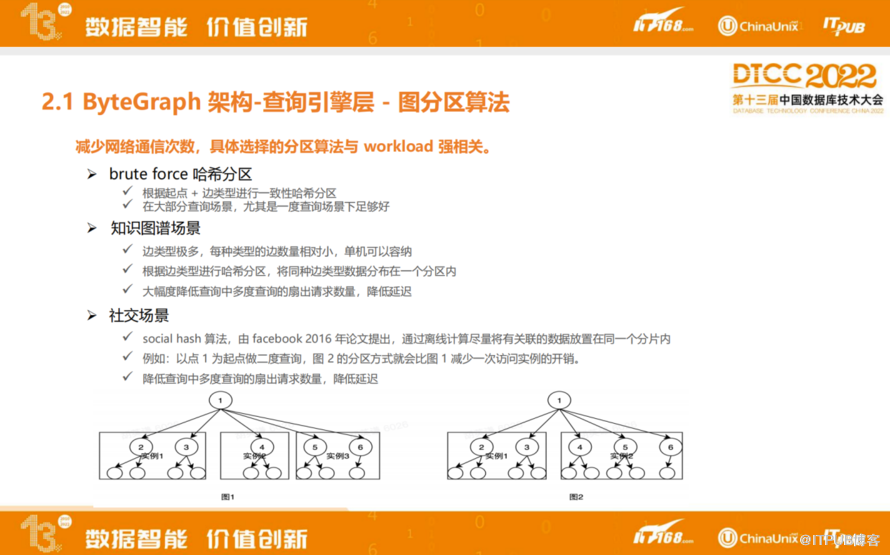
ByteGraph支持不同策略的图分区方式,最简单的是基于起点和边的类型进行一致性哈希分区方式,目前在大部分场景上都是基于这一分区算法来做。
然而在知识图谱场景里,也会将相同类型的边放到同一分区,这样能大幅降低查询中多度查询的请求数量,降低网络开销,进而可以降低整体延迟。
在社交场景中,因为字节跳动是一个比较重社交的公司,参考Facebook在2016年的一篇论文中social hash算法,用来保证我们多跳邻居查询的延迟、网络开销比较低,这种情况ByteGraph第一步基于图导出之后做离线图分区算法,之后会把对应的路由表存到中性化节点里,后续通过路由表提供线上读写访问请求。
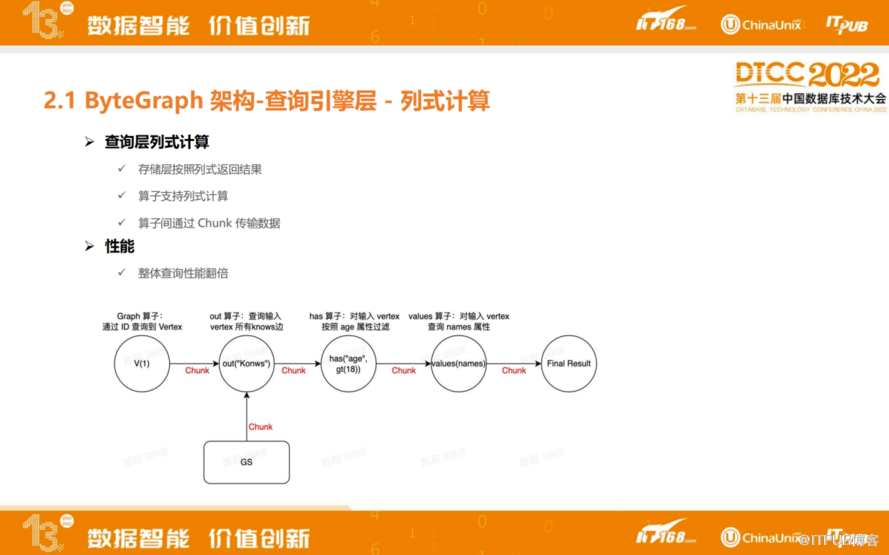
查询层列式计算,会将数据组织成链的方式进行组织和计算。目前这一块我们做到的是存储层,按照列式方式去返回查询结果,以及查询层和算子之间支持列式计算。ByteGraph查询层、算子之间数据传输是通过Chunk进行传输。实现了列式计算后,最终在部分场景中查询性能会直接翻倍。
2.2 ByteGraph 架构-存储引擎层
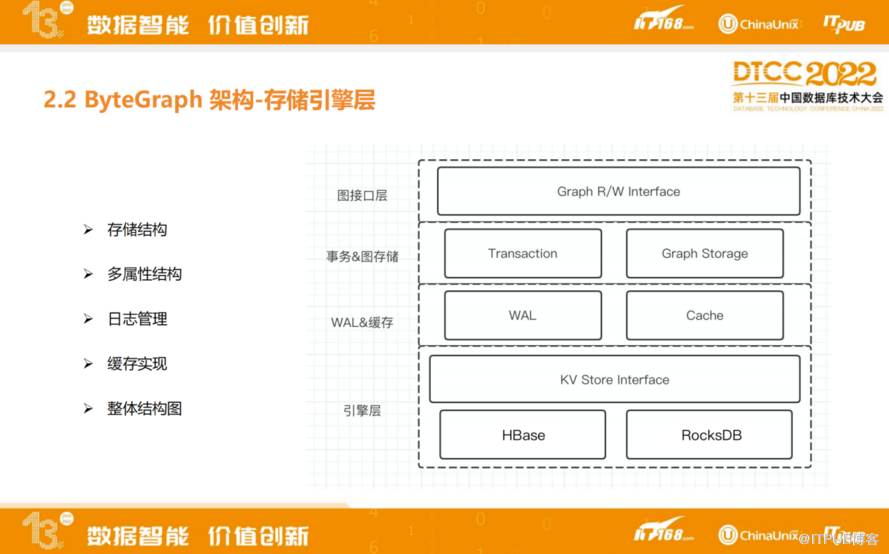
接下来讲一下ByteGraph存储引擎细节,整体上存储引擎会把系统的组件划分为几层:
最上面一层图接口层是跟图数据库接口有关的读写接口,中间的事务&图存储层主要涉及如何支持数据的事务,以及图原生存储。支持WAL来保证数据的更新是持久化的,不会有任何数据更新的流失。最下面一层是KV Store接口,未来可能会对接一些开源的HBase、RocksDB等。

如何基于KV构建一个图的结构?最直观的一种方式是一个KV对一条边,实现简单,同时写放大非常小,适合写入场景,当前的建模写放大非常小,因为粒度很细。但做一跳邻居查询时,读性能退化非常大。另外一种方法是一个KV保存一个起点所有边,这种写放大会变得很大,比如改了一个对应点上某一条边,其实整个边的历史被更改,无法处理字节内部一些超级顶点写入问题,因此在设计上需要做折中。
ByteGraph的邻接链表图结构构建,用多个KV对组成B树等结构保存起点的所有边,实现较为复杂,可以根据配置来灵活平衡读放大和写放大。
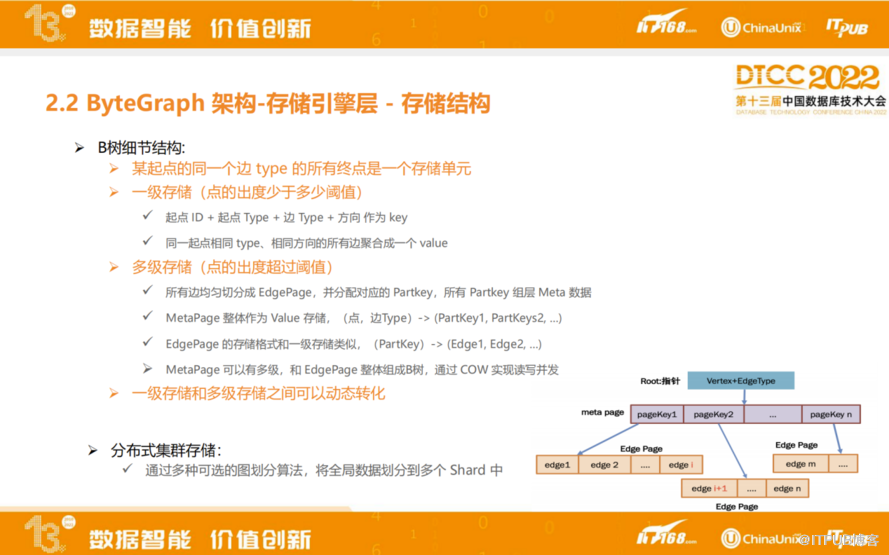
如图是B树实现细节,第一层是MetaPage,MetaPage整体作为Value存储。比如1000万个邻居中,每2000个会做分片,每一个分片称为EedgePage,每一个EedgePage里又存了2000条边,采用多级拆分方式降低整体读写放大问题,这是比较平衡的设计。
总体来说,单个起点固定的边类型会组成一个B树,B数的每个节点都是一个KV。根据我们的设计,一个集群里面99%都会是单层的B树,1%的数据会被拆成两层甚至更多层的B树。
B树的并发控制力比较复杂,目前为了规避并发控制的复杂度,ByteGraph会限制每一个B树写是唯一的,以防止并发的修改导致破坏B树逻辑。
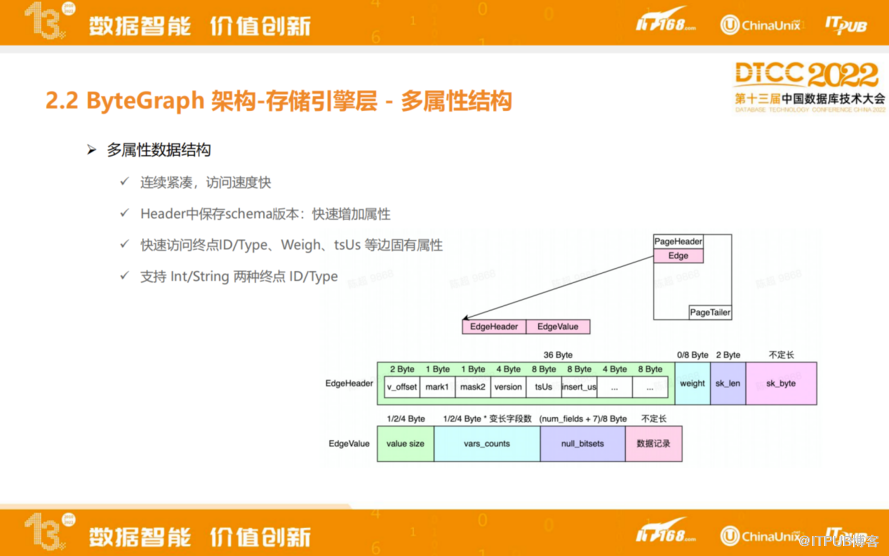
ByteGraph多属性结构是为了支持点边多属性访问,针对图的结构去定制一些多属性数据结构,有几个特点:会连续紧凑、访问速度快;Header中保存schema版本,快速增加属性;快速访问终点ID/Type、权重,以及时间这种边上固有属性;支持Int/string两种类型的ID/Type。
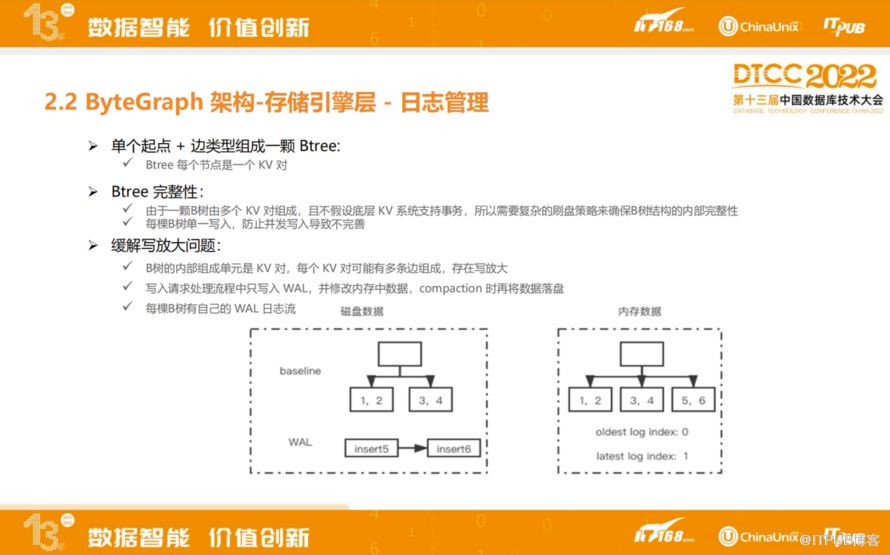
日志管理模块,ByteGraph WAL作用有两个:
一是维护B树完整性,由于B树的分裂和合并操作会涉及多个KV,我们并不假设底层KV系统会支持分布式事务,所以需要有日志维护B树内部数据的完整性以及做分列合并的原子性。另一个是缓解写放大问题,每棵B树有自己的WAL日志流,写入请求处理流程中只写入WAL,并修改内存中数据、compaction时再将数据落盘。
关于缓存,ByteGraph目前自己实现了高性能LRU Cache,作为数据库而言,需要将缓存层组织成一个图相关的结构,用于提供最适合图的读写模式缓存性能。同时在缓存层也支持条件过滤等部分算子下推功能。LRU支持不同的策略,基于不同频率的读出以及触发阈值也不一样,比如物理机内存用到60%再往上走可能就比较危险,开始触发LRU Cache,把不经常用到的page下刷写到磁盘里。
ByteGraph架构其实是缓存与存储相分离的架构,这种架构优势是当数据规模不变时,读写请求流量增大时,可以通过缓存与存储分离模式做到快速扩容,也就是可以把GS层实例单独增加,用于提整体服务能力。
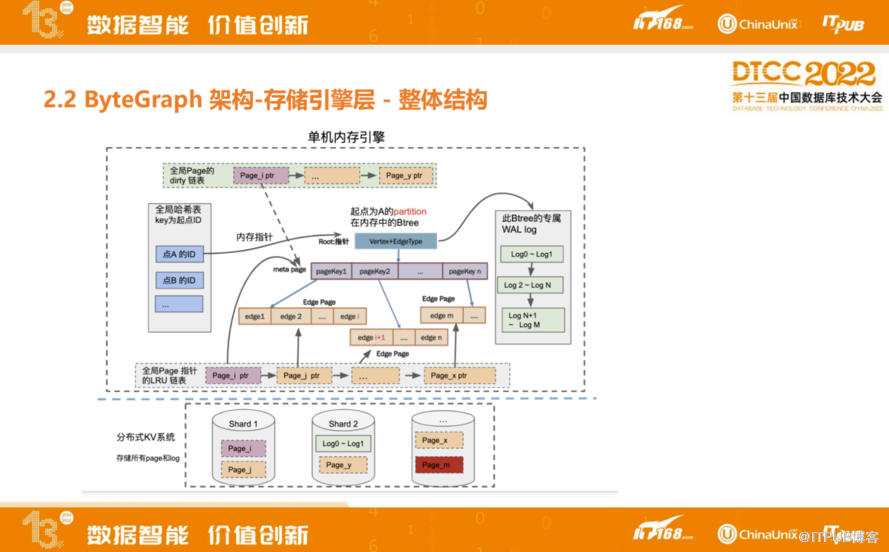
ByteGraph存储引擎层的整理结构是把整个图数据模型计入一个特定的点,以及对应的边,抽象成一个B+树的数据结构,随着读写流进来,写入流会更新page上的数据,写入一个WAL,page会变脏,所以会用delta page上link list去记录脏数据,脏数据积累到一定程度之后,把脏数据下刷到子盘里面。同时会有WAL这样的log流。也会有一个LRU Cache来保证物理机内存维持到某一阈值之下,整体内存使用会有上界以及下界。最下面是分布式KV层,里面会混合page以及log两种类型的数据。
3 面临的关键问题以及具体解决方法
3.1 ByteGraph 架构-图索引 - 局部索引
图相关的索引有局部索引以及全局索引。
局部索引是指对于给定点的起点和边类型,在边的属性上去构建的索引。主要应用场景是用来加速边的过滤以及边属性排序。
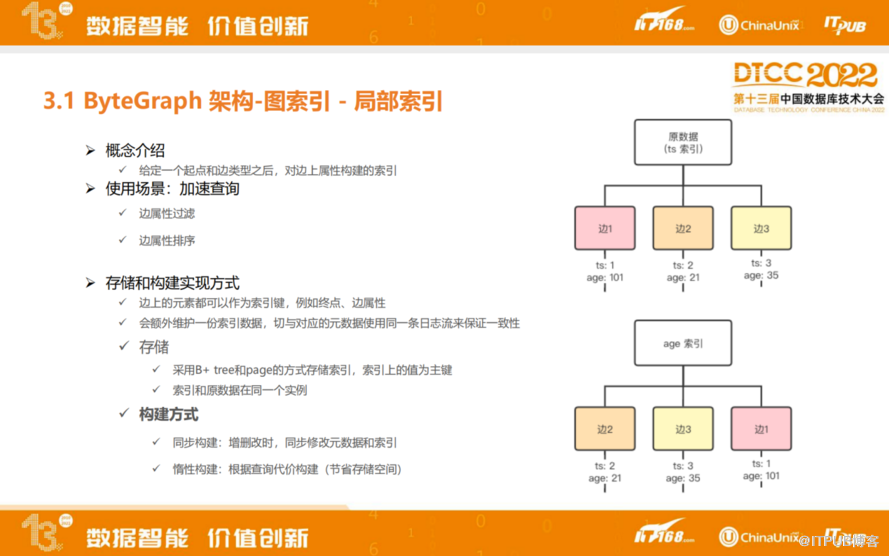
上图右边的图是新建局部索引的例子,当前默认索引是基于时间做索引,边就会基于时间做排序。如果基于年龄做索引,也会基于年龄做排序。用两个不同的B+ 树的方式去组织这两个数据。目前ByteGraph二级索引和主索引共用一个OP日志,也是为了避免底层分布式KV的分布式事务。
索引构建目前支持两种方式:一是同步构建,在主索引去增删查改时,立刻修改元数据以及对应的索引。二是惰性构建,根据查询代价构建,使用惰性构建可以显著节约消耗资源量。比如某一种边类型上有时间索引以及年龄索引,就某一个点出度比较小,这时候可能没有必要构建年龄索引,如果某些点出度比较大,年龄索引构建优势比较大。
3.2 ByteGraph 架构-图索引 - 全局索引
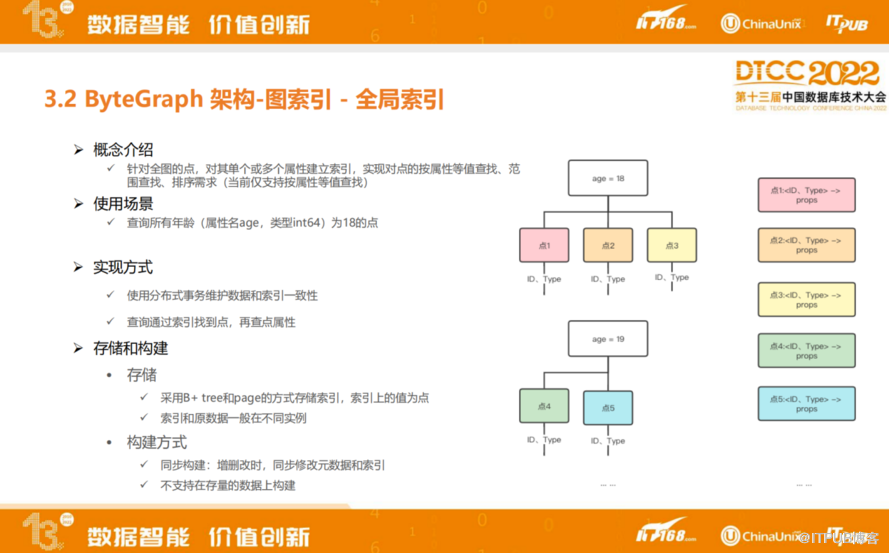
全局索引是指基于某一个属性值能够查到在当前Graph里具有特定锁定值所有点的ID,这是全局索引的概念。
比如基于年龄构建全局索引。年龄为18和19岁分别为两棵B树。全局索引更新涉及数据一致性问题,所以会通过分布式事务能力维护数据和索引之间的一致性。同时全局索引也是通过B+树来维护,所以如果索引的排序键区分度不太好的话,比较极端的例子就是男、女两种,全局索引上面的数据量太大,会导致比较严重的性能问题。
当前,ByteGraph全局索引只支持同步构建,并不支持在存量数据上进行构建。
3.3 ByteGraph 架构-分布式事务
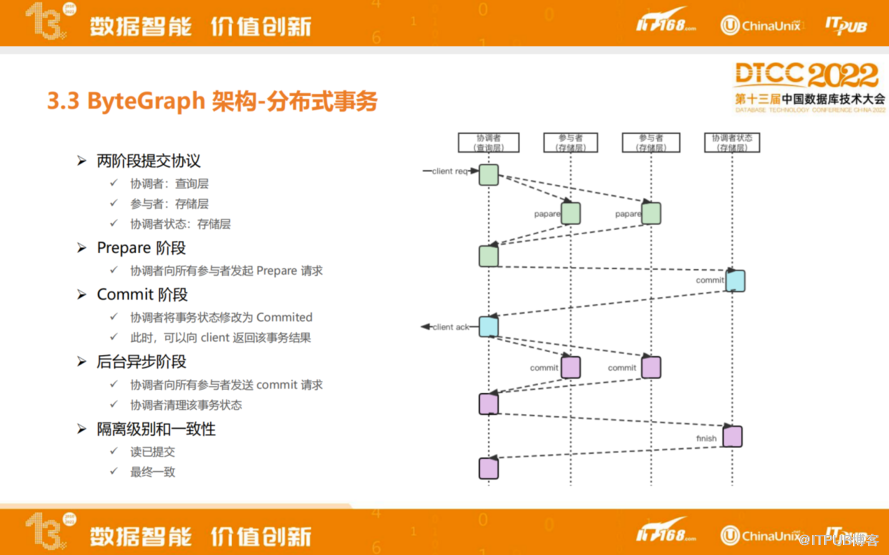
ByteGraph采用两阶段提交的协议实现分布式事务,查询层会作为一个协调者,存储层会作为参与者,查询层都是无状态的,所以存储层会保存协调者的状态。
两阶段提交的事务再经过Prepare阶段和Commit阶段,都能返回客户端结果。后台异步阶段,协调者向所有参与者发送commit请求,协调者清理该事务状态。目前ByteGraph支持隔离级别是读已提交,保证最终一致,未来的版本会不断完善事务能力。
3.4 ByteGraph 架构-重查询-自适应限流
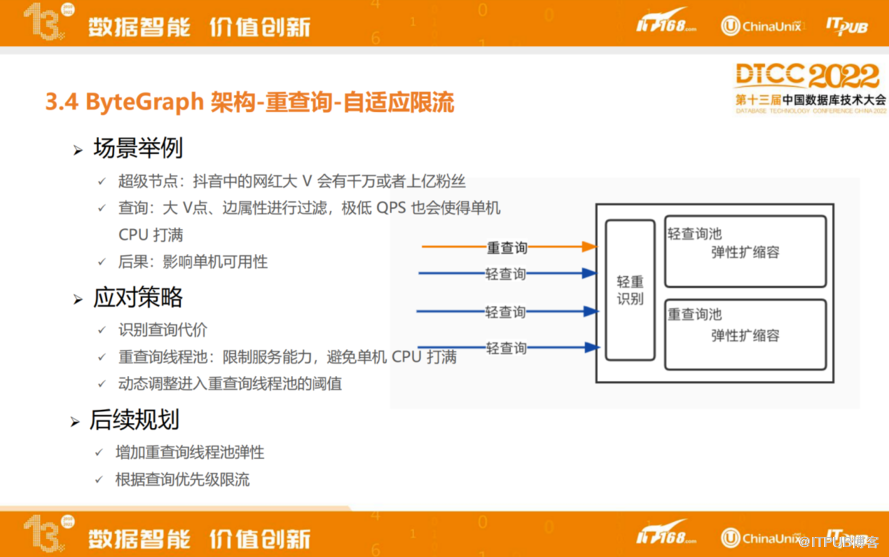
ByteGraph会基于图的负载进行针对性的优化,比如针对重查询的自适应限流。在社交网络中,会存在一些超级节点,例如抖音中网红大V会有千万或者上亿粉丝,如果图查询起到相关大V点,极低QPS也会容易使得单机CPU打满,从而影响单机可用性。
针对超级节点的负载,会对每条查询分为轻查询和重查询两类,同时会把单机资源划分到轻查询池和重查询池,查询时会将对应类别的查询投入到对应池子里,如果某一个池子资源已经耗尽,会拒绝后续查询的投入。
通过这种方式,限制了重查询使用的资源量,避免少量重查询打满单机CPU,后续也会持续优化自适应限流机制,例如增加重查询池子的弹性,以及根据查询优先级划分更多类型的查询池。
面对超级节点问题,除了限流,还会做一些自适应局部索引,在系统内部会衡量识别查询代价和构建索引后执行代价,目前该功能还在演进中。因为构建索引会消耗一些存储空间,除了动态构建索引,未来也会需要做到动态删除索引,以及更好地和限流结合,例如会对高优先级查询构建索引,对低优先级查询做限流。
3.5 ByteGraph 架构-写入放大优化

前面介绍了通过WAL缓解部分写入放大,接下来会介绍如何进一步缓解B树的写入放大。
这里借鉴了类似BW-Tree的解决方案,在每个page上由base和delta两个部分组成,新写入的数据,先写入delta page,到一定阈值之后再合并到base page里。和BW-Tree不同的是,BW-Tree每个base的page会有多个delta page,读取时会合并多个delta page,ByteGraph只会有一个delta page,每次写入之前会附带之前的delta page,这样读放大就会稳定控制到2。
3.6 ByteGraph 架构-在离线生态
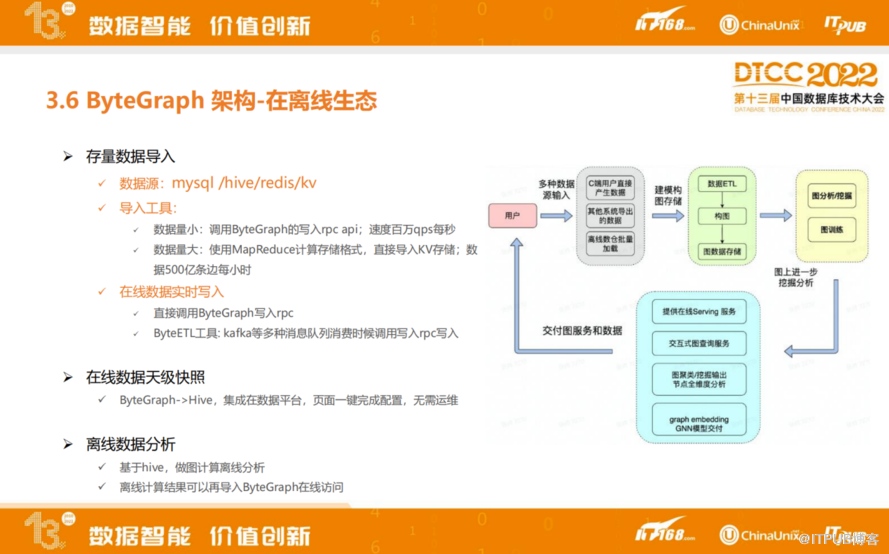
在离线生态方面,ByteGraph非常注重在离线数据融合,在我们内部产品线,除了有ByteGraph这种图数据库,也会有一些图计算产品。
ByteGraph支持存量数据导入,之前存在不同的数据源里,如MySQL、Hive、Redis、HBase等其他外部数据源,可以通过公司内部平台导入到ByteGraph里。数据量小时,调用ByteGraph的写入rpc api,速度达每秒百万QPS。数据量大时,使用MapReduce计算存储格式,直接导入KV存储,速度达到每小时500亿条边。
在线实时写入是通过线上服务调入SDK,可以通过Kafka这种消息队列在线写入ByteGraph,支持天级数据快照,可以把前一天的数据完整地放到Hive或者图计算里,用来给上游的业务同学去做离线分析或者离线训练。
嘉宾介绍

陈超
字节跳动研发工程师
深度参与了 ByteGraph 开发到上线以及后续的迭代演进。目前主要负责 ByteGraph 存储层的开发工作。

