快狗打车业务快速发展是公司众多人员的努力,同时对数据侧提出了更高的要求。数据的价值随着时间的增加而降低,分析以及运营更加希望实时数据助力业务发展,研发也希望借助BI侧的大数据综合计算能力得到汇总数据。
在这样的基础上,快狗打车实时数据仓库历经两次迭代,从Spark计算引擎到阿里云Blink+Flink,从Hbase存储到目前多样式OLAP系统使用。本文将分享快狗打车实时仓库的发展和实践。

▲快狗打车实时数据仓库负责人 杨铮
嘉宾介绍:2019年加入快狗打车,负责实时数据仓库整体架构。毕业于山东理工大学,在离线和实时数据仓库有丰富经验,热爱分布式相关技术,在OLAP,Flink,Spark等技术有较深理解。
分享大纲:
1、以往的开发流程和实时计算
2、从上云开始转变
3、解决痛点
4、应用
首先交代下,快狗打车实时数仓的业务背景。业务的复杂度比较高,业务线比较多,各个业务线之间数据相互关联,不相互独立。流量比较大,目前有小程序、APP端、网页、H5等,这些端产生的业务数据日增有几TB,如果全部应用到实时数仓里,对成本和计算都有压力。
此外,实时数据的应用场景也比较多,比如驾驶舱、报表、应用于线上的智能的调控等,这些场景对实时数据需求多。在业务发展初期时,也会面临或多或少的问题,比如开发时长等。
以往的开发流程和实时计算
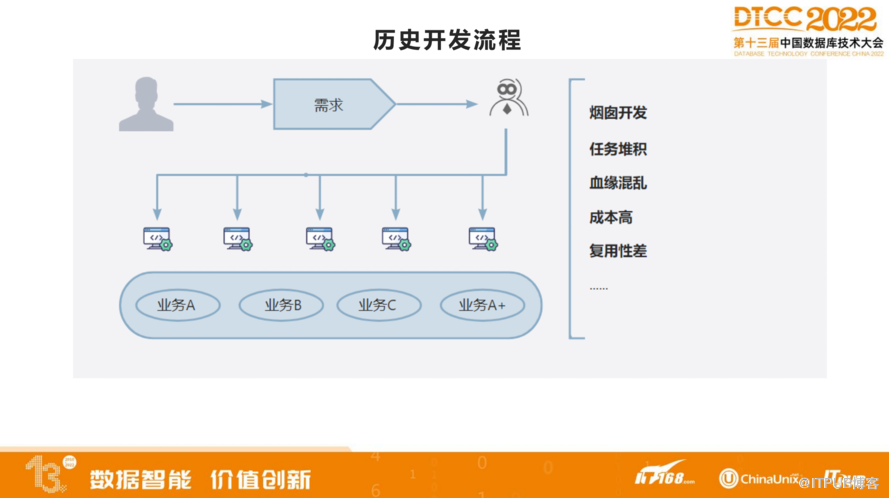
在历史上,实时数据的开发流程如上图所示。首先,需求同学提出需求到数据产品经理。然后,数据产品经理再把需求下发到开发同学身上。在业务发展的快速期,更多的是以应对需求和快速解决问题为主。
在开发时,会出现重复的任务,然后就形成了一系列问题。比如,烟囱式开发会导致任务堆积,任务的血缘变得混乱。在这个时候,我们逐步发现,运维成本和机器成本变得非常高,数据的复用性也很差。
关于实时计算的过程,从DS到kafka,然后Spark消费kafka的数据,继而产生服务。这在当时来讲,是一个非常简单的流程。它的叠加历史时期,也是一个业务快速发展的时期,我们在上面堆积了非常多的任务,从风控到流量,以及驾驶舱等一系列的任务。
我们发现,开发成本非常高,通用化模版应用少,功能越复杂,开发成本越高,大量时间在编码设计上。早期Spark版本维护有困难,任务失败修复重复数据带来的高昂运维成本。另外,当时使用服务没有节制,服务链路无监控,导致数据源维护成本高。开发应用服务混乱,数据得不到统一,冗余数据也越来越多。
从上云开始转变
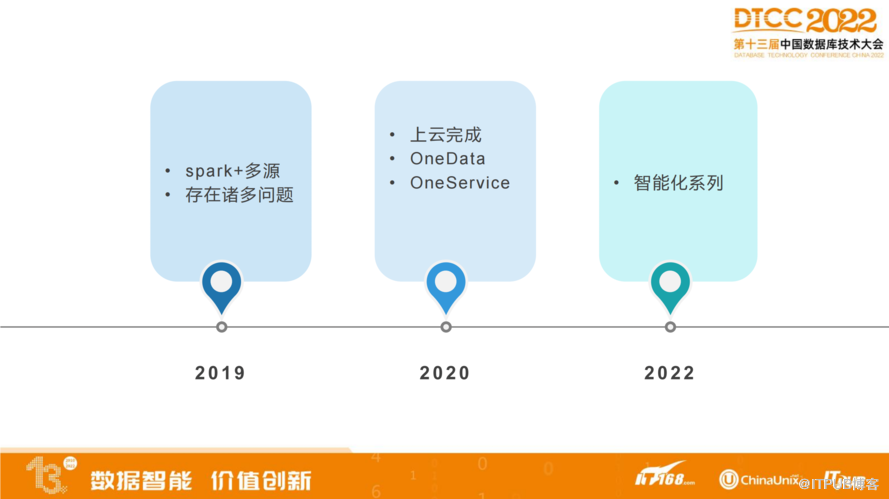
从所有的离线数仓和实时数仓迁移上云开始,我们决定做一次完整的改变。在2019年之前,我们使用Spark作为主流的处理引擎,加上多存储的数据源。数据服务大多来自于这些数据源,比如,Mysql、ES等存储引擎。
在2019年到2020年之间,我们完成了一次上云,把整体的离线数仓和实时数仓都迁移到阿里云上面。在这个时期,我们提出了两点:一个是OneData,一个是OneService。
从2020年开始,我们开启了智能化系列。比如说,智能调优、智能运营等一系列的基于实时数据的智能化操作。
解决痛点
在上云的时候,以解决我们的痛点为主,烟囱式的开发,数据得不到复用,成本无限的增高,没有合理的架构,当时是为了解决问题而存在,现在我们希望沉淀数据。
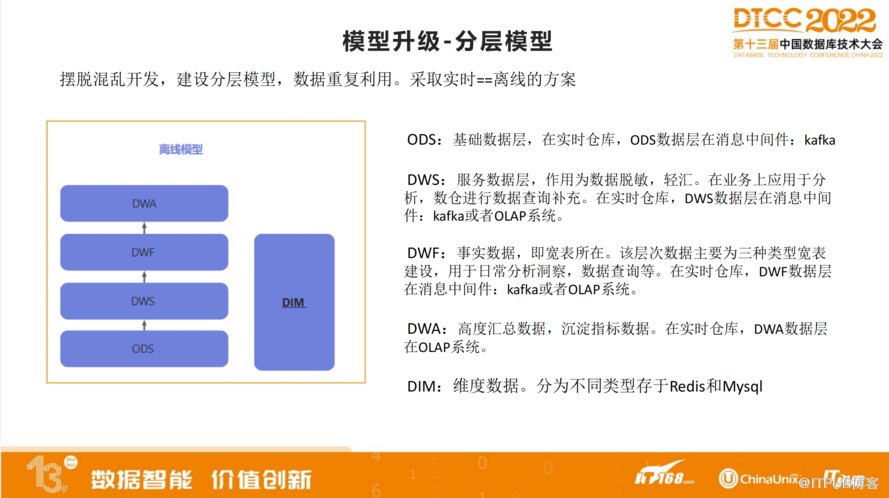
首先,第一点是模型升级,我们采取了大家认可的分层模型,为了摆脱混乱开发,建设分层模型,主要目的是让数据重复利用。我们采取实时和离线完全相等的方案,这么操作运维起来很方便。
我们严格按照离线模型,区分了几个层面。第一是ODS基础数据层,第二是DWS服务数据层,第三是DWF事实数据层,第四是DWA高度汇总数据层,第五是DIM维度数据层。
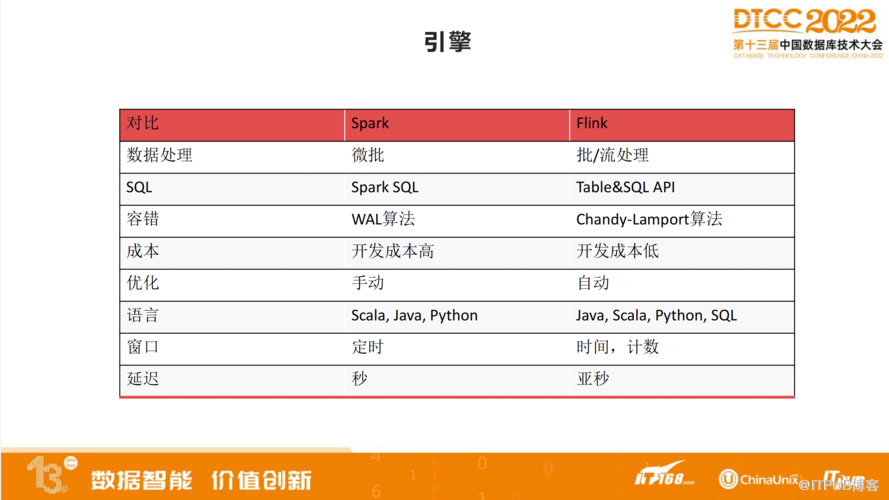
之前我们使用的是Spark,后来用到了Flink。上云的基础运用的是阿里云云原生,最开始是Flink,现在是全托管Flink,很少用到开源的Flink。从Spark迁移到Flink,很大的一部分原因是希望得到效率方面的巨大提升。
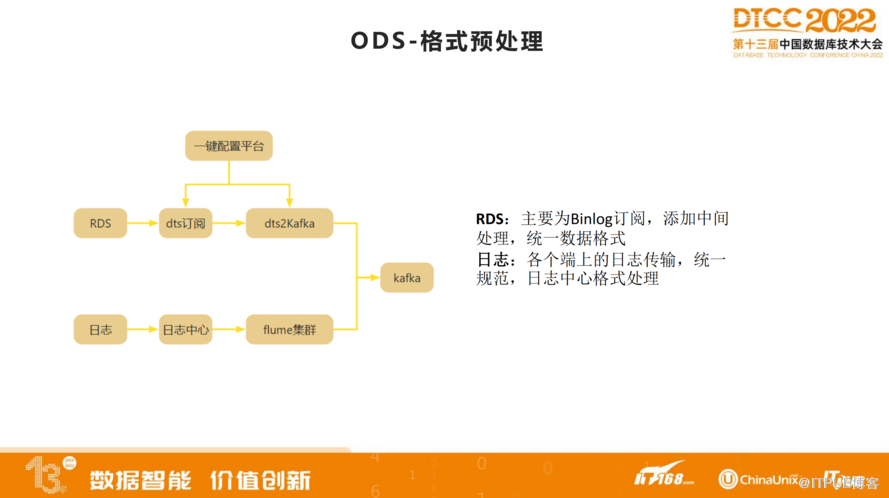
在ODS层面,我们已经做了一次格式的预处理。当时在架构设计方面实现离线实时一体化。RDS主要为Binlog订阅,添加中间处理,统一数据格式。日志数据是通过各个端上的日志传输,统一规范,日志中心格式处理。
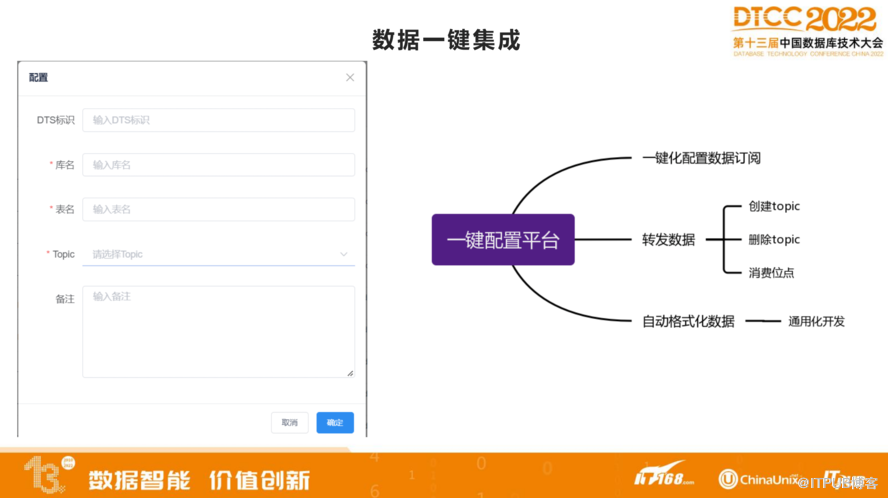
上图是数据一键集成图,在这里,只需要我们填写DTS标识、库名、表名、Topic,它就会自动的一键创建数据,并且自动转化出来,把数据格式经过一次处理传输,直接转发到kafka里面。
一键配置平台的数据订阅工作,极大的节省了我们与DBA沟通把数据订阅进来的操作流程。另外,创建Topic、删除Topic、消费位点等一系列操作都可以在一键配置平台上进行操作。自动格式化数据,方便后续做模版化的开发,不需要进行定制化开发。
关于开发模版的大致流程分为四步:
第一,Flink SQL读取kafka数据源格式固定,可变的是topic参数和读取位点,group等;
第二,创建视图,利用核心UDF统一离线和实时Schema信息,任务启动阶段进行校验两方的shcema信息(类型,名称等),严格一致;
第三,多流处理阶段,一般无法定制模板,需要注意state,资源等;
第四,输出阶段,分为输出至OLAP、Mysql、Kafka,输出至Kafka利用核心UDF固定格式。
在数据流入和流出阶段,进行严格的格式控制,利用通用模板提高效率,同时保持离线实时一致。
事实上,日志处理是一个非常麻烦的过程,占用大量的时间。所以,我们做了一次集成化的处理,做成了一个参数化配置的平台,仅需传入离线日志表,任务自动获取离线任务所有信息,自动配置到实时任务。
它类似于一个动态规则的配置,自动创建topic,初步清洗好的日志数据自动传入topic,并且优化格式。此外,这个任务还具有资源优化功能,内部核心为任务清洗程序,配置后台,根据任务资源,日志数据切分任务,极大缩短开发时间。
在我们平滑上云之后,用了三个主存储系统。第一个是Hbase+ES,Hbase存储数据+ES构建加速查询索引。第二个是阿里云ADB(云原生数据仓库),同时也是即席分析平台,支持存算分离、动态扩展、高并发等。第三个是我们与阿里云共建的Hologres,主要使用的HOL AP系统,支持PB级别,支持高并发。
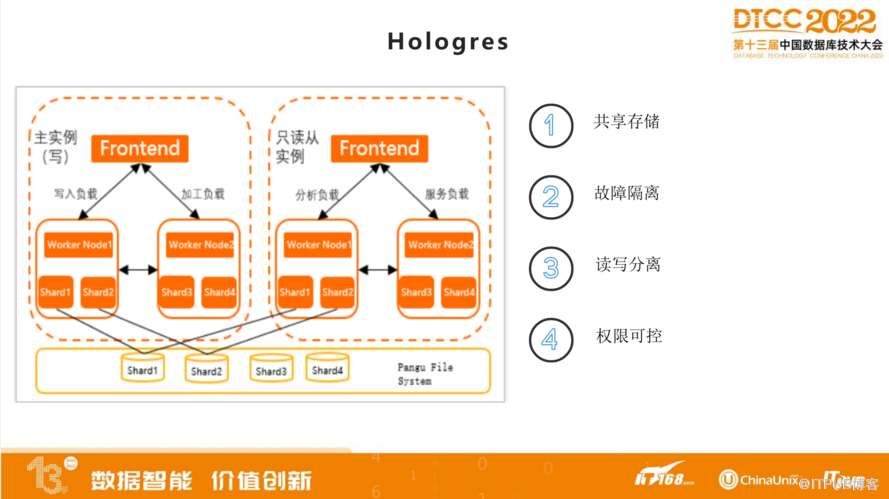
我们在Hologres用到读写分离的架构,Hologres支持实时+离线数据映射查询,支持联邦查询,实时和离线数据混合使用。支持统一数据出口,无论是即席分析还是实时接口查询等,数据出口均在Hologres。
应用
构建好实时数据仓库之后,有哪些应用?
首先,对外提供应用接口。比如,Http接口,灵活性高,可拓展性强;采取表映射形式,可以解耦,无感知变更;接口监测,所有接口的响应时长,ip,查询频率等进行资源监控;平台一站式开发,内部研发的接口管理平台,上线接口从测试到上线达到分钟级别;慢查询监控,慢查询及时监控预警。
接口开发平台的接口配置为SQL开发,测试之后自动生成接口id,分钟级别上线。目前接口规模300+个,平均查询时长在毫秒级别。

在风控应用方面,业务数据经过消息队列里面的消费,加工,然后传输到图计算里面,离线数据先把全量灌进去,然后实时的增量数据构建插入。这部分更多体现我们在风控和图计算方面的内容。
关于指标预警,通过构建运营同学关注的指标,可以以自定义规则定制实时预警和离线预警方式,目前支持SQL和指标形式进行监控,小时级别和天级别的预警,智能预警形式结合算法,自动测算,实时预警。
OneData指标管理是实时指标和离线指标统一管理平台,具备指标血缘、版本等各种管理功能。无论实时或者离线指标,首先是指标管理平台收录,再进行三方嵌入使用。
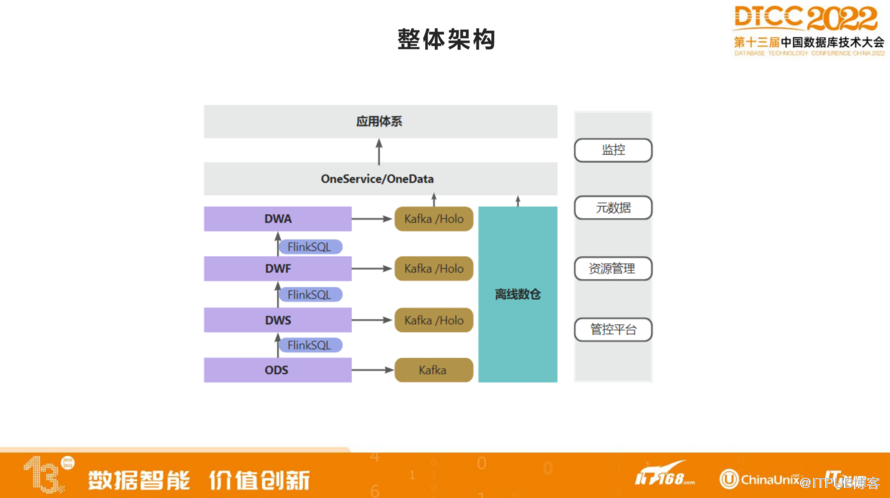
上图是实时数仓整体架构图,从ODS、DWS、DWF、DWA,经过FlinkSQL一层一层的加工,数据分别存入到Kafka/Holo,在往上进入到OneData、OneService,最后进入到应用体系。
展望未来,我们希望通过流批一体,达到一套系统,一个逻辑。目前来讲,我们实现了实时数据离线数据相互统一,但是它仍然存在数据交互的问题。另外,它依然是两套系统,务必存在系统之间的相互隔离。同时,我们正在做一套动态规则,智能营销,实现运营策略。

