DTCC演讲 | PolarDB-X技术架构:云原生分布式数据库
作者:阿里云PolarDB-X数据库研发负责人 黄贵

PolarDB-X是一款云原生分布式数据库,为存储计算分离的分布式数据库架构,由以下几个组件构成:
①元数据服务(GMS)。GMS是一个高可用集群,利用 Paxos 协议实现数据的高可用,负责存储全局的元数据,包括数据的分片、数据节点计算节点的拓扑信息以及日志节点拓扑信息,还负责提供全局授时的服务,用于判断数据的全局可见性,提供外部一致性事务保证。
②计算节点。计算节点无状态,负责接收应用发来的 SQL ,任意计算节点都可以完成 SQL 的解析、重写、优化、转化为物理执行计划并执行,支持MPP 的执行框架,负责整个计划的调度与执行,并最终返回结果。
③数据节点。是数据存储的载体,同时也负责单机执行计划的执行。数据节点会组成复制组,每个组由Paxos 一致性协议保证数据的强一致的高可用,为了横向的扩展能力会将其切分为很多分片。数据片会根据一定的规则分布在各个DN复制组上。
④日志节点。提供全局一致的 binlog 能力,兼容 MySQL 生态。日志节点输出的全局一致Binlog完全兼容单机 MySQL 提供的 Binlog ,因此可以将整个 PolarDB-X 看作单机的MySQL来使用,包括原来的生态、对接的下游数仓、大数据类的生态,都可以通过CDC 消费日志。
PolarDB-X 架构在阿里云平台上,包括生命周期的管理、备份、容灾、数据迁移、数据的DevOps、SQL 的全流程诊断、DAS等都依托于云平台提供的一整套数据库服务。
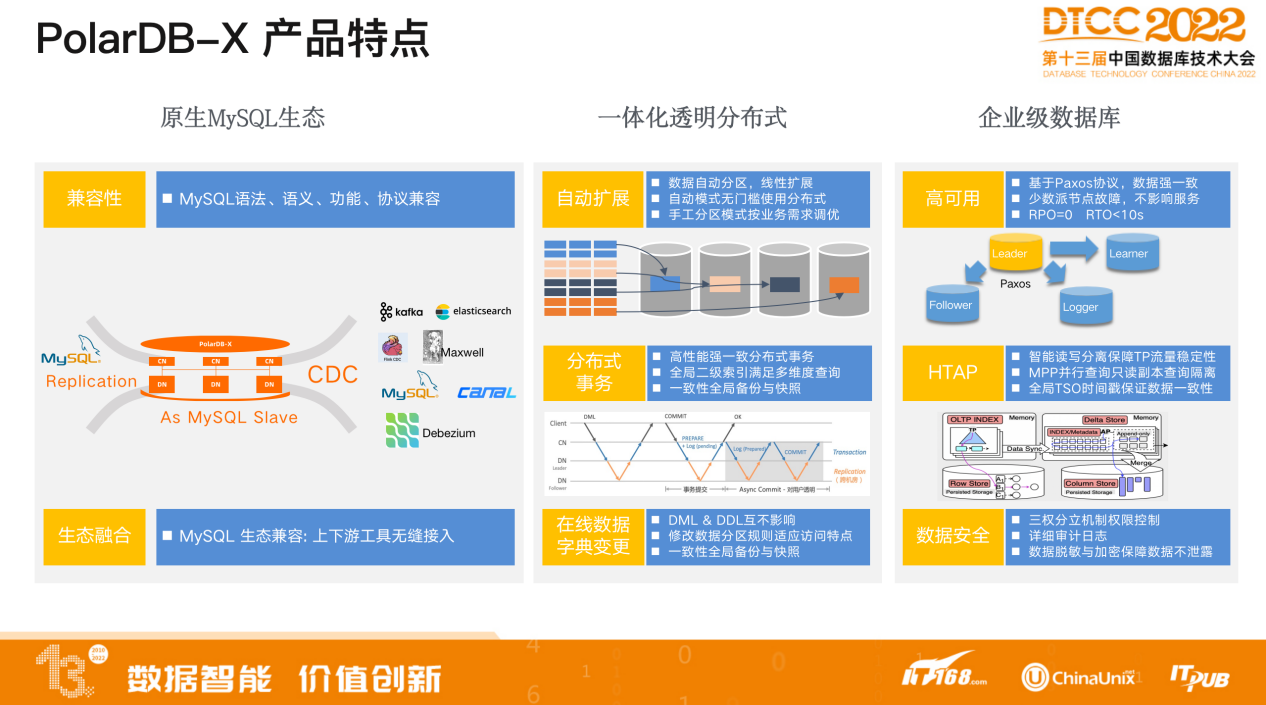
PolarDB-X 作为分布式数据库,具有以下三个特点:
第一,原生MySQL生态。提供完全兼容 MySQL 的能力,包括语法、语义、功能、协议以及生态的兼容。原生的 MySQL JDBC的connector或 Java 、Go 等版本的客户端connector都可以直接连接 PolarDB-X,享受完全一致的体验。
生态的兼容方面,利用CDC,PolarDB-X既可以作为 MySQL 的备机,通过 Binlog 同步数据,使用 MySQL 的 replication 功能,实现主备高可用的模式,也可以作为一个大的MySQL数据库 通过 CDC 同步给下游的数据生态系统。
第二,一体化透明分布式。PolarDB-X希望用户不再需要关注数据分布的细节,也无需为此做太多优化,我们希望尽可能地为用户提供与单机数据库一致性的体验,不管是建表还是应用均无需做任何改变即可享受到分布式数据库的扩展能力。降低用户的使用门槛。另外,PolarDB-X支持手工分区模式,按实际业务需求进行调优。分布式主要体现在自动扩展、分布式事务以及Online DDL。
第三,企业级数据库的能力,包括强一致数据的高可用、支持HTAP以及对于数据安全的保障。
分布式数据库并不是新技术,只是早期的分布式数据库更多地存在于学术界,作为研究对象。2000 年左右,互联网开始蓬勃发展,业内意识到了单机数据库以及集中式数据库的局限性,无法应对互联网的业务增长带来的海量数据以及对于大规模数据的高并发、高吞吐的写入需求。
为了增强数据库的扩展性,逐渐发展出了 NoSQL 。而 NoSQL 数据库为了扩展性,放弃了很多关系型数据库的实用特性,包括ACID等,是的应用不得不编写复杂的逻辑来尽可能保证数据一致性,变得更复杂。后来,关系型数据库和分布式技术相结合发展出了NewSQL,这也是分布式数据库从理论走向应用的发展阶段,彼时的分布式数据库更多地被大型互联网公司使用。
到了云时代,分布式数据库作为云产品为用户提供通用的数据库服务,真正进入商业化发展的阶段,不仅关注扩展性,还关注易用性以及企业级的特性,因此也必然会出现兼容性、数据库运维等能力上的要求。

分布式数据库面临几个较为突出的问题。
①兼容性:传统数据库的应用如何更便捷的迁移到分布式数据库上?
②使用门槛:用户有使用分布式数据库的诉求,但是又不希望投入太多学习成本。
③扩展能力:分布式架构能否实现真正的线性扩展?
④运维复杂度:分布式系统天然具备复杂性,如何应对运维管理上的挑战?在分布式数据库上保证ACID、保证数据一致性比传统数据库更具难度,比如在数据量巨大的分区表上做DDL或创建索引需要付出高昂的代价。
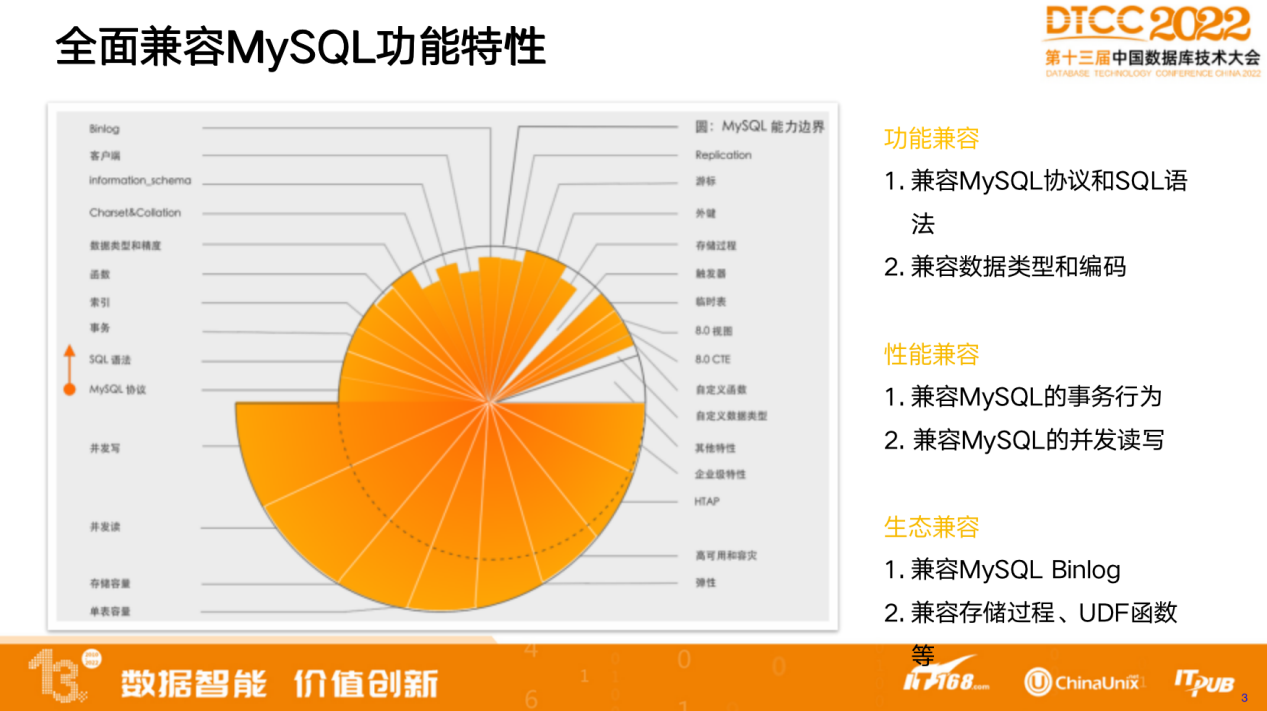
PolarDB-X 全面兼容 MySQL 数据库,包括功能上的兼容和生态上的兼容。
功能上并不追求百分之百的兼容。上图中圆圈为 MySQL 的能力边界,涂色的部分是 PolarDB-X目前已经覆盖的能力。部分PolarDB-X的能力与 MySQL 的实际能力依然存在一定差距,也有部分超出了MySQL的能力。判定兼容性的原则需要以用户诉求为依据,我们会优先覆盖常用功能,对于不常用的功能,会有选择性地支持,并逐步补全。
目前, PolarDB-X对 MySQL 的大部分功能基本已经实现兼容,也包括扩展性的能力,比如存储过程触发器、外键等等在分布式数据库上较难支持的功能,而高可用容灾、高并发读写等方面的能力已经远超出现有 MySQL 的能力。
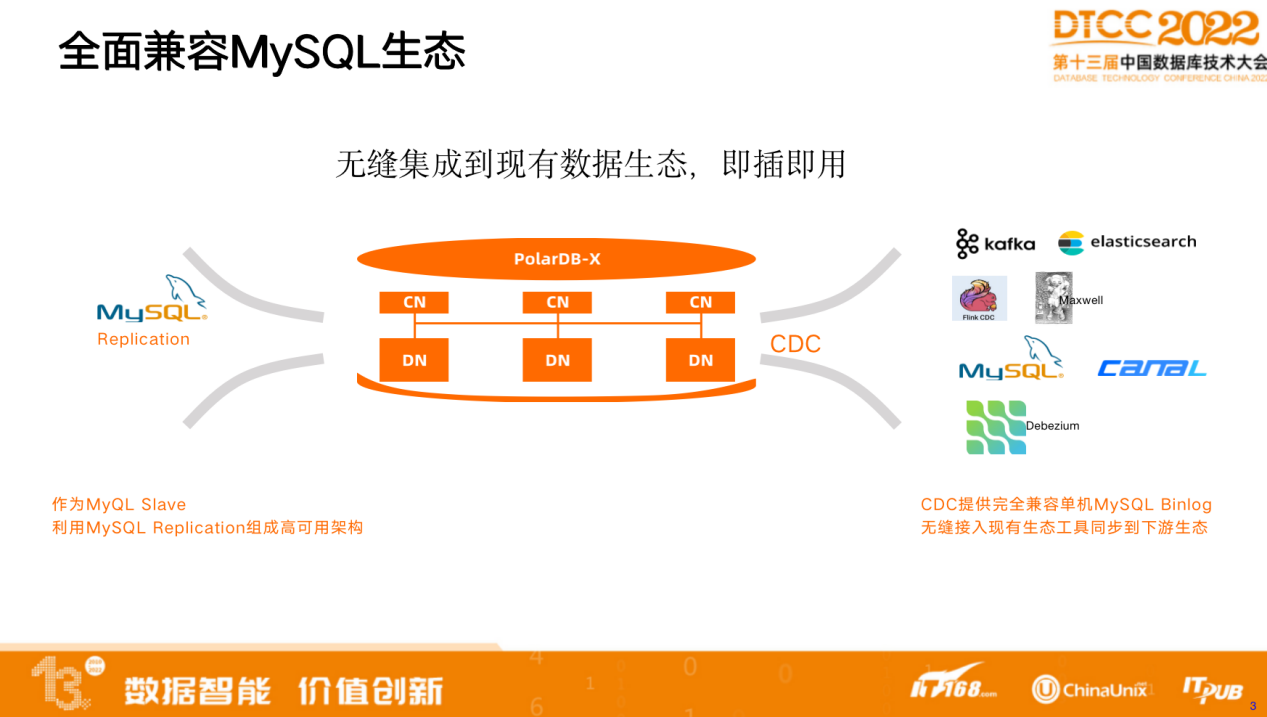
生态的兼容主要利用全局一致的Binlog,即CDC。 CDC 是一个高可用集群,能够提供全局一致的 Binlog 服务。PolarDB-X 作为分布式数据库,存在很多数据节点,每个数据节点都有日志流。为了保证数据一致,CDC 会对多机上的日志做归并、排序、整流,最终提供与用户事务发生顺序一致的全局 Binlog 日志流。日志流完全兼容 MySQL 单机 Binlog ,格式完全一致。下游生态系统消费Binlog时,可以将其看作单机MySQL 来使用。
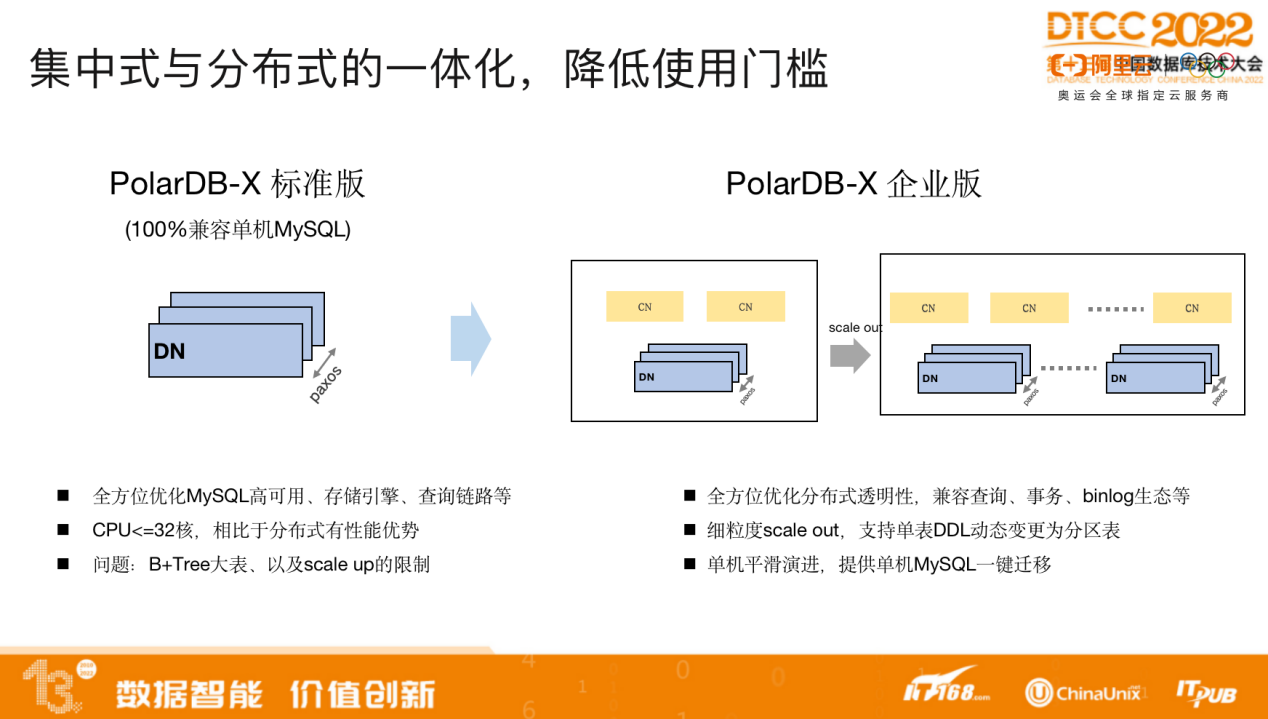
分布式系统作为云上的服务,希望为用户提供集中分布式一体化的体验。PolarDB-X提供了标准版和企业版两种形态,两者可以平滑迁移。标准版百分之百兼容单机MySQL,提供了高可用的能力。企业版提供了典型的分布式能力。
对于很多用户而言,如果当前业务规模不大,则可以先选择标准版。业务规模扩大以后,无需任何修改即可平滑迁移至企业版。原先在单机上建的表能够自动变为分布式的表,无论是查询还是事务,使用上均没有任何区别。也可以通过 DDL语句指定数据分区的规则,保留了按照业务特性进行数据分布的需求。
集中分布式一体化有两层含义:其一,既能满足集中式的需求,也能满足分布式需求;其二,集中式到分布式可实现完全透明转化。
切换到分布式形态时,如何保证集中式的体验?
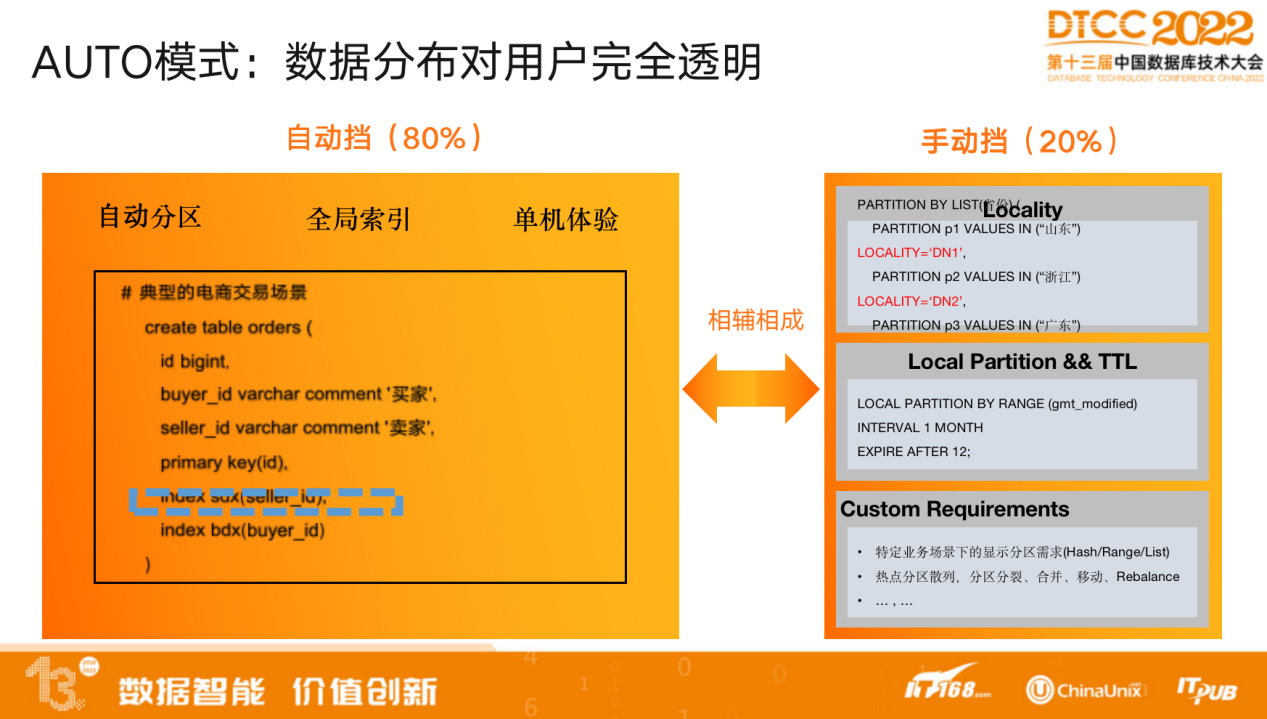
PolarDB-X提供了 库级AUTO模式,数据分布对用户完全透明,无需指定分区键,在集中数据库里建一张分布式表,数据库会自动为其做分区。同样,也可以建全局二级索引加速查询。
但这必然存在代价,比如默认按主键做分区,分区不一定符合需求。其次,全局索引开销较大,导致写入开销较大,可能无法满足对业务性能的要求。
另外,PolarDB-X提供了手动分区的模式,可以手动指定分区算法,采用了完全兼容 MySQL 的 partition 分区表语法,分区的算法可以兼容 Oracle 的所有的分区的算法。同时,也可以指定分区在不同条件下存放的位置,真正完全契合业务的访问模式。
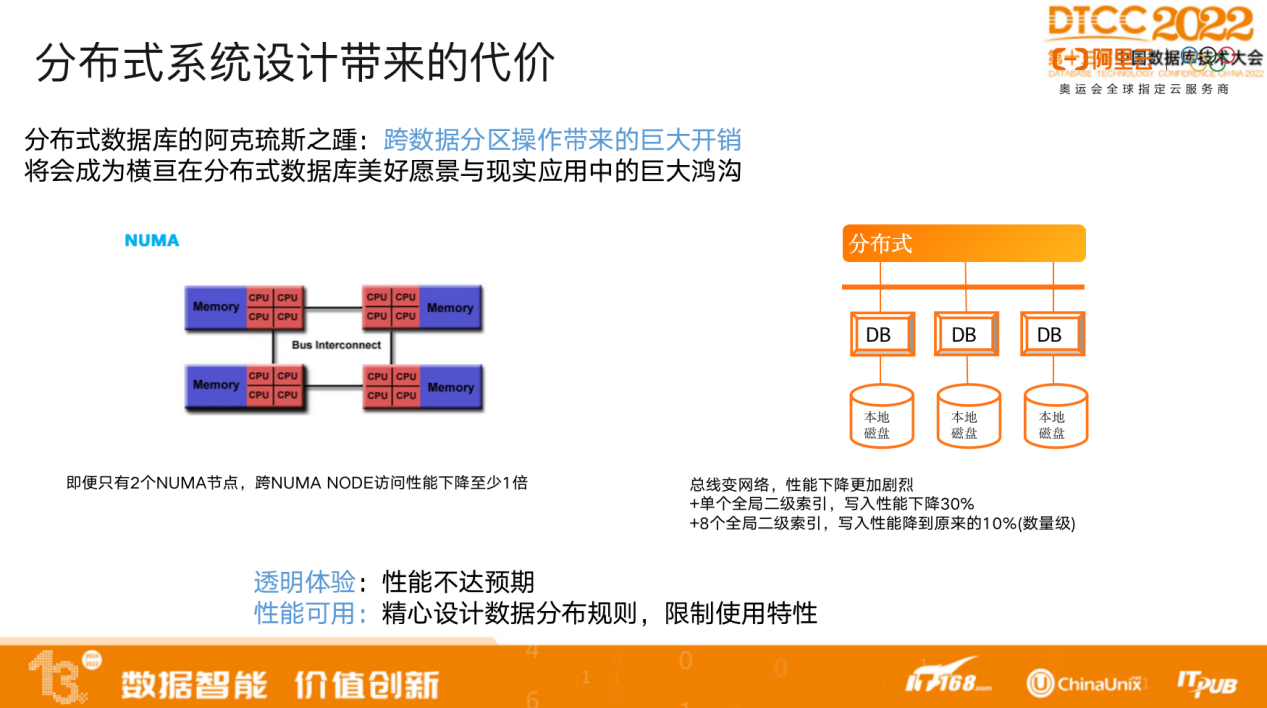
分布式数据库的显著优点在于能够无限扩展,然而,扩展并不是没有代价的。一旦数据进行扩展以后,集中式数据数库上的事务操作可能会变为跨分区的分布式事务操作,会导致性能急剧损失。如上图所示,即便只有2个NUMA节点,跨NUMA Node访问的性能也将至少下降1倍。
而同样的事情发生在分布式架构上,性能损失会更明显。NUMA Node 之间有总线连接,而分布式架构下只有网络连接,即便是高性能网络也会产生巨大的网络延时,导致性能急剧下降。
我们曾经做过实验,加一个全局二级索引,写入性能下降30%;而加8个全局二级索引,写入性能将会下降一个数量级。
因此,分布式系统能否做线性扩展,取决于访问模式。如果系统中跨分区的事务很少,理论上可以实现线性扩展;但如果系统中跨分区的事务比较多,则无法实现线性扩展。
在硬件没有实现突破时,很难提升分布式事务的性能。而我们能做的只有尽量减少分布式事务的比例。
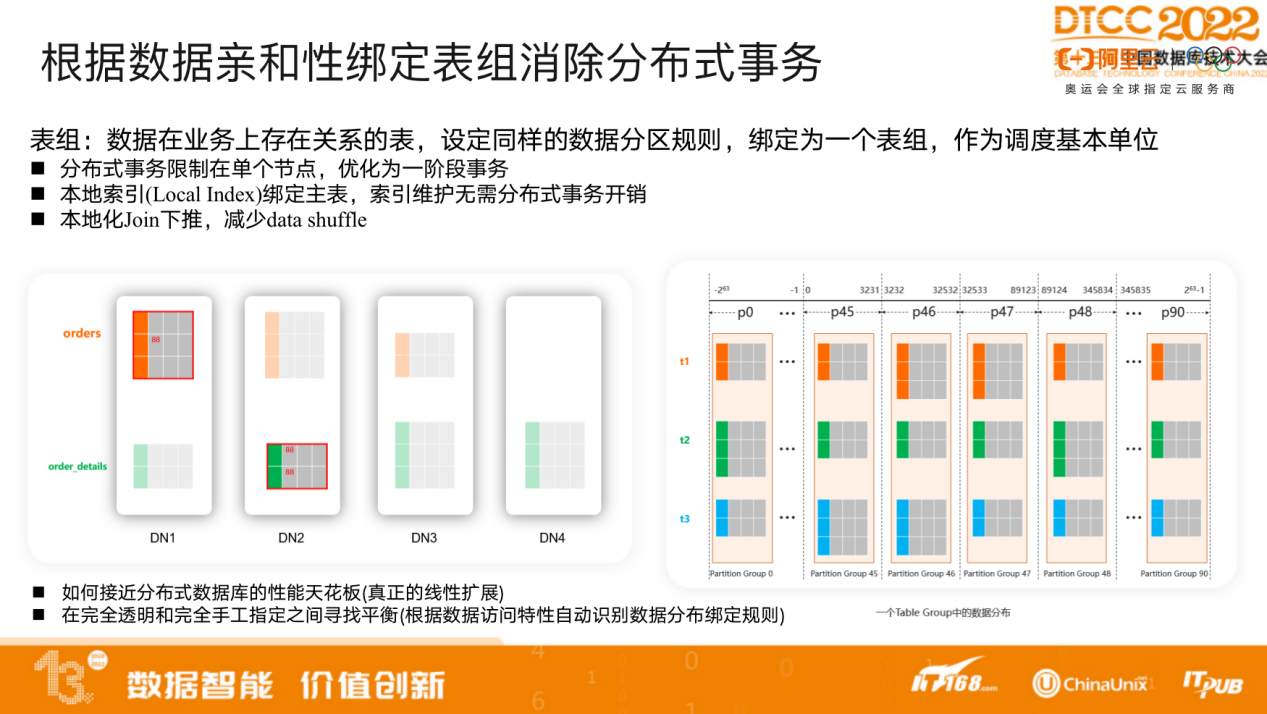
因此,我们提出了做数据亲和性绑定的概念,将业务上有关联的表,设定同样的数据分区规则,绑定为一个表组,作为调度基本单位。一个表组里的表都采用同样的分区规则、同样的分区算法以及同样的分区个数,减少了分布式事务占比,从而降低分布式事务带来的性能开销。
绑定表组最优的方案是自动识别用户的访问模式,自动聚合。
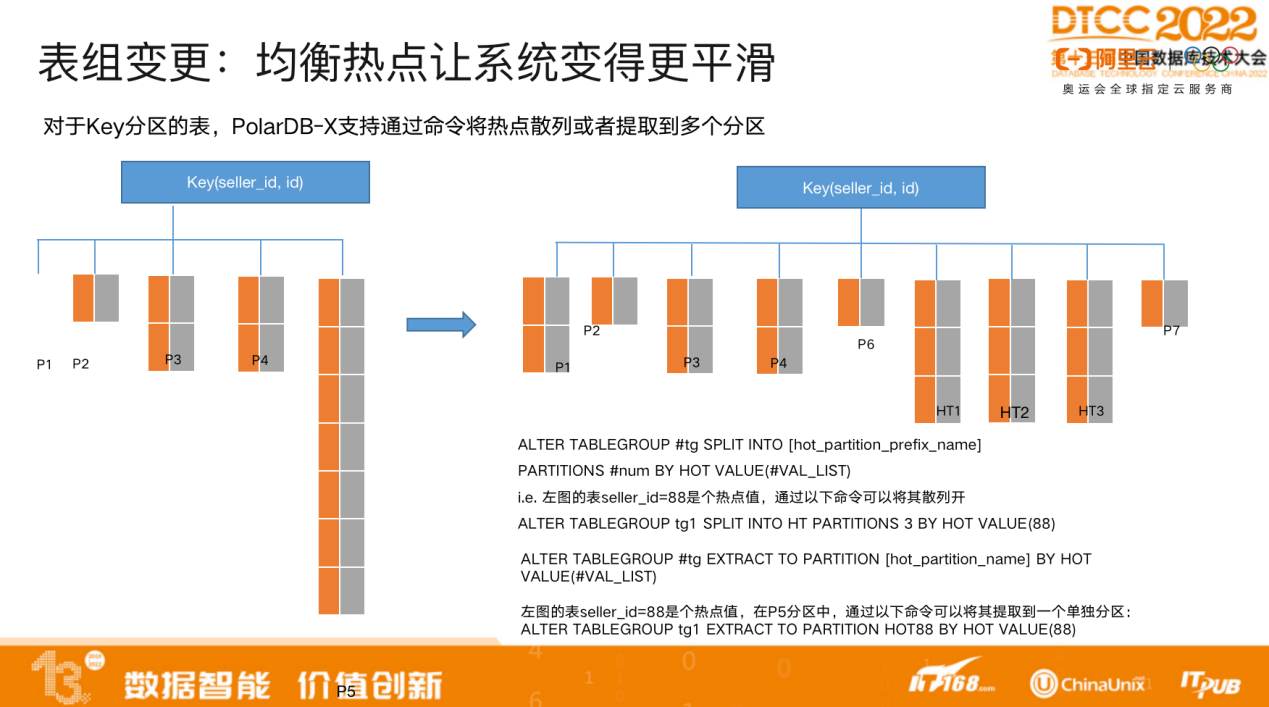
在分布式系统里,一旦负载均衡受到了挑战,则会出现数据热点。PolarDB-X能够进行实时的数据热点提取,可以将热点数据分片重新打散,提取到多个分区。它提供了丰富的 DDL 操作语句,能够实时有效地消除热点,达到系统的负载均衡。
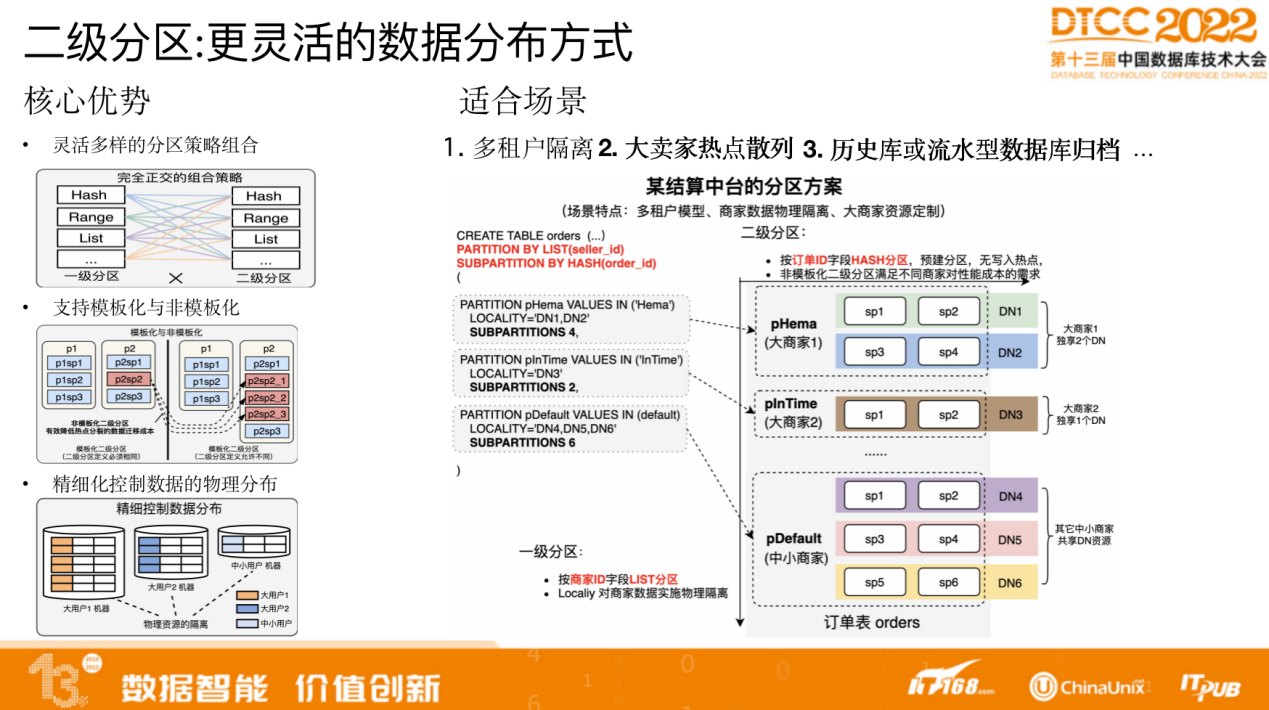
电商业务一般会按买卖家做分区,而大卖家会成为热点分区,此时会重新将卖家再按 order ID做哈希分区,打散热点,这是二级分区的作用。
二级分区使用灵活,支持与一级分区一样多的分区策略,是完全正交的策略。而且可以任意组合,支持模板化和非模板化的方式,能够实现精细化控制。比如二级分区可以对所有一级分区制定统一的规则,将每个一级分区都分为 5 个子分区,也可以只将某一个分区分为 5 个分区,其他一级分区不变,这样的模式可以根据业务特点进行灵活的调整,也能够避免分区数量无限膨胀。
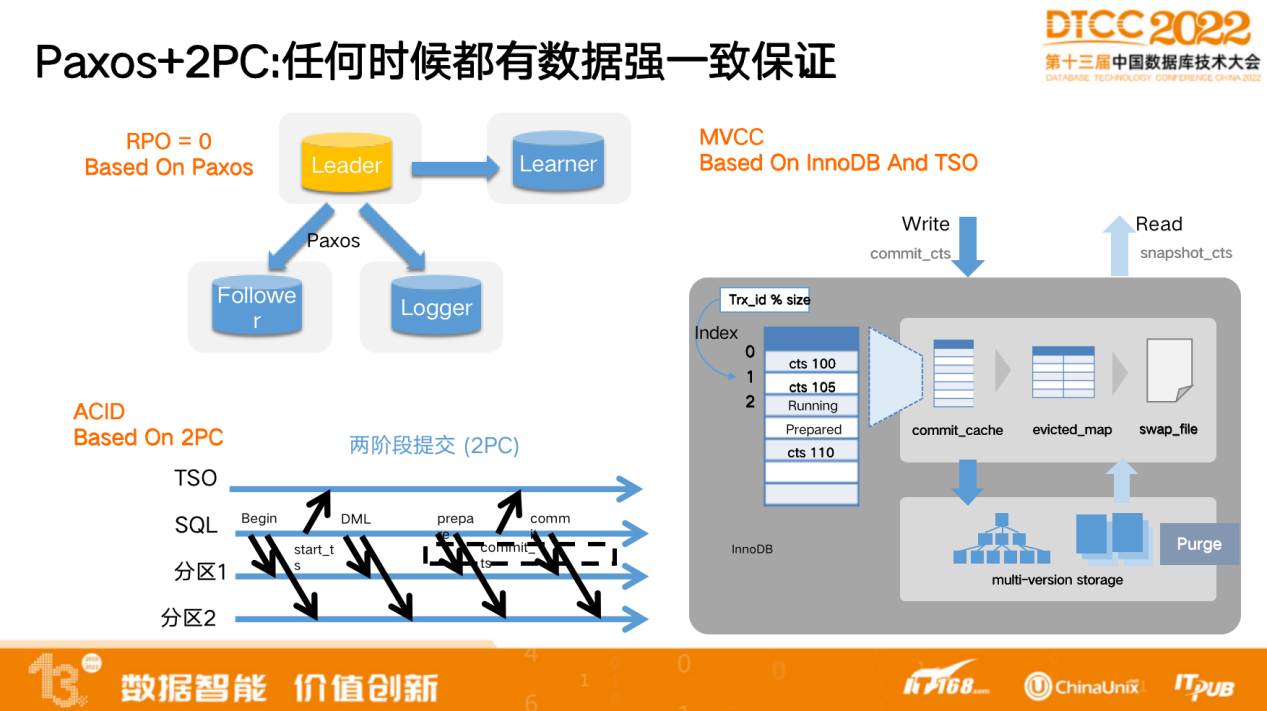
分布式带来的好处在于在企业级能力上提供了一致性保证,利用Paxos+2PC实现了任何时候都有数据强一致的保证。
Paxos主要用于 DN 的复制组,保证数据副本之间的一致性。 MVCC 加2PC 的分布式事务的方式保证了外部的一致性。TSO用于做 Snapshot 隔离级别、事务隔离级别的一致性保证,其优势在于,做只读事务时,无需对数据进行加速,通过快照也可以读到一致的数据视图,不会读到某个部分的事务。
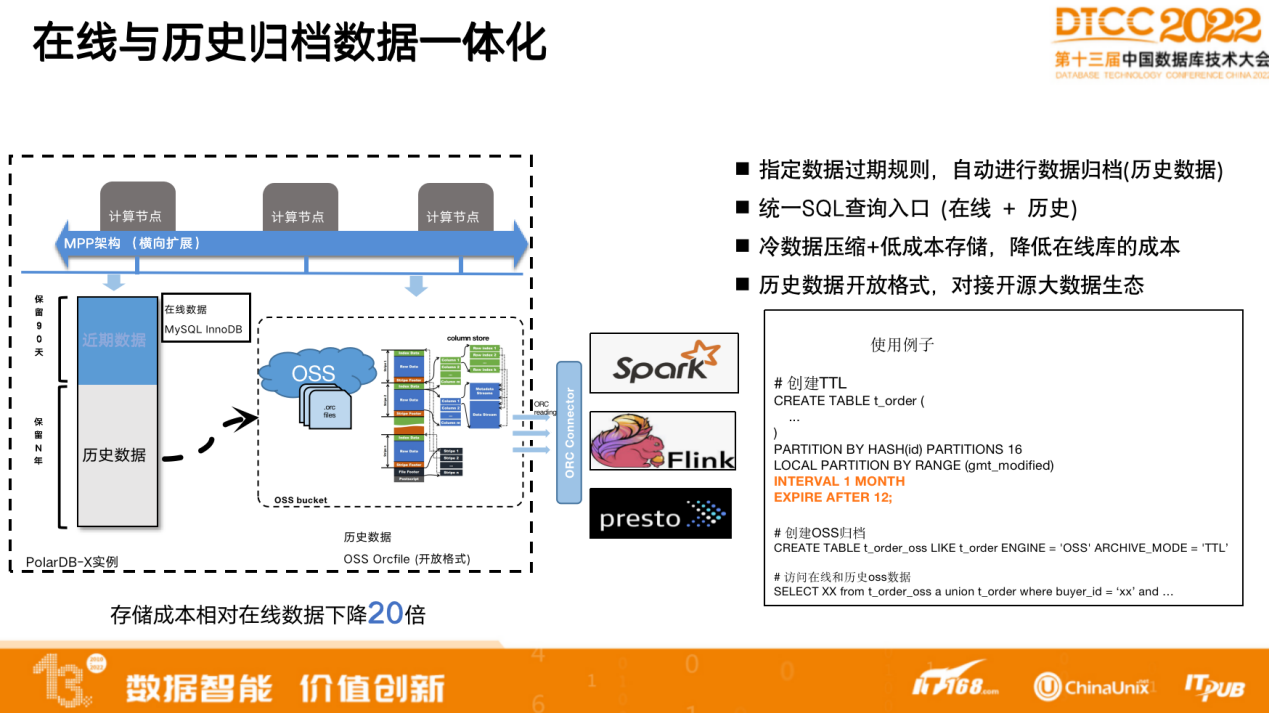
企业级能力这一层做了一体化,包括分布式一体化以及在线与历史归档数据一体化。
数据在分布式系统里的体量非常大,且很多数据均有明显的冷热区隔。为了降低成本,我们实现了自动归档的能力。
归档过程全自动化,在建表时指定数据过期规则,会将过期数据自动建好分区进行归档,存储到低成本的OSS存储里。自动归档也会对冷数据的做压缩,大幅降低数据容量,结合OSS 低成本的混合存储方式,相对在线数据的成本有 20 倍下降。
过期的分区可以作为外表做在线查询,即对历史归档数据一样可以与在线数据做混合查询。
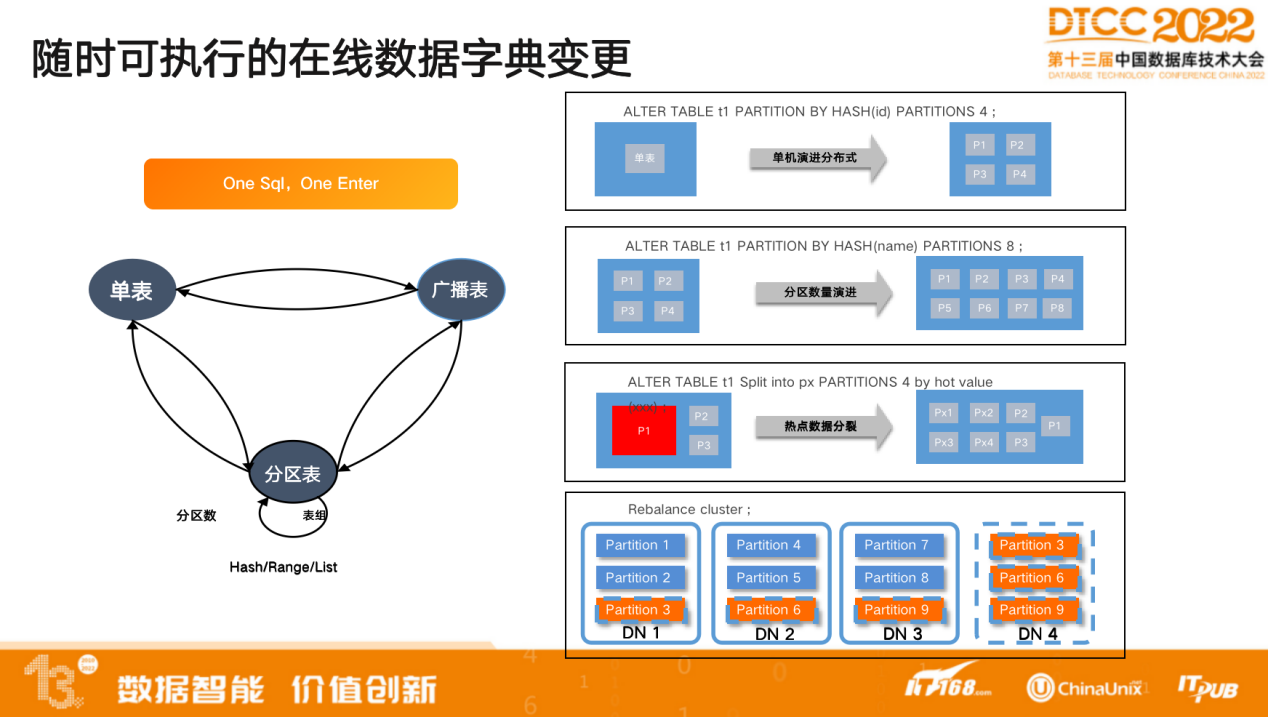
为了解决分布式数据库的运维问题,我们做了很多工作,比如做了整体的云管平台,内核层面实现了在线数据字典变更,只需ONE Sql,One Enter即可实现。无论是分区表的算法变更、分区键要变还是热点数据分裂,都可以用 DDL 的方式操作,所有 DDL 都为 online ,不会影响现有的数据查询和事务操作。
用户无需专门找运维窗口,随时随地可做数据字典的变更以及算法的变更来提升性能。
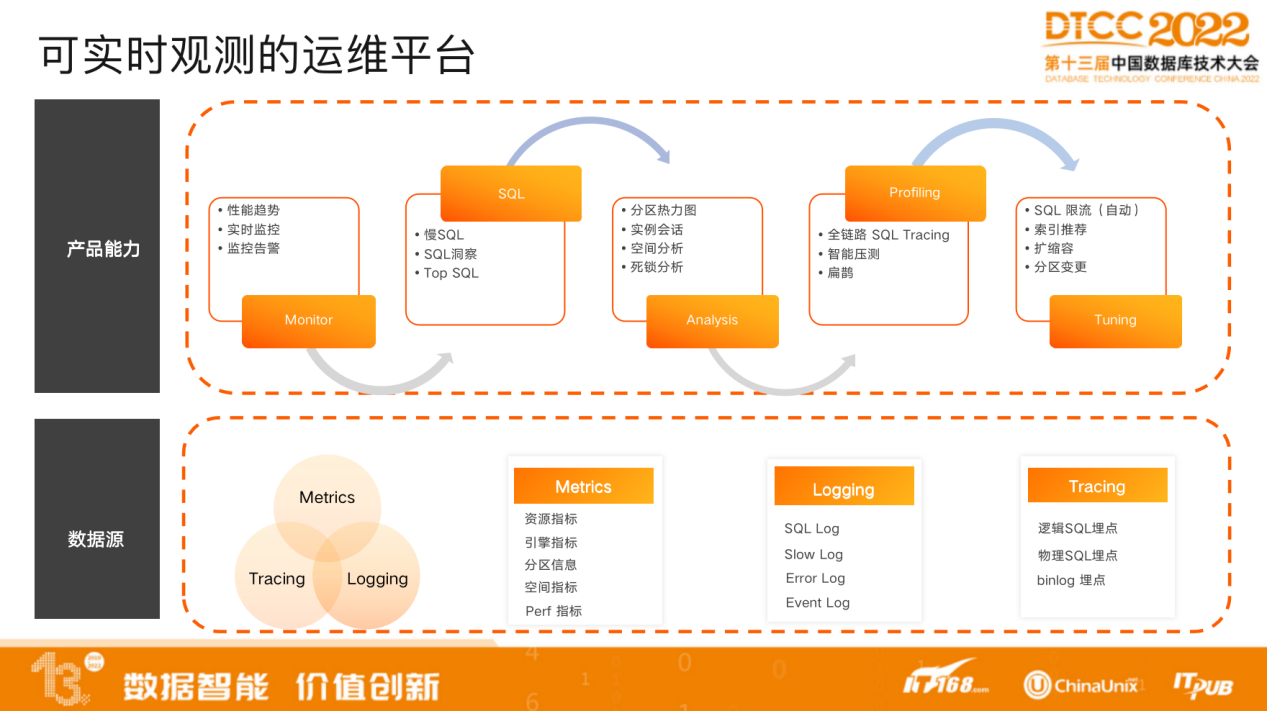
同时,我们提供了完整的实时观测运维平台。
我们对数据源进行了归类整理,包括metrics、 tracing 、logging,会在 SQL执行路径上做很多埋点,便于跟踪整个云管平台,进行监控告警、SQL洞察、性能分析诊断、 Profiling 以及Tuning,也可以根据SQL执行模式进行索引推荐。
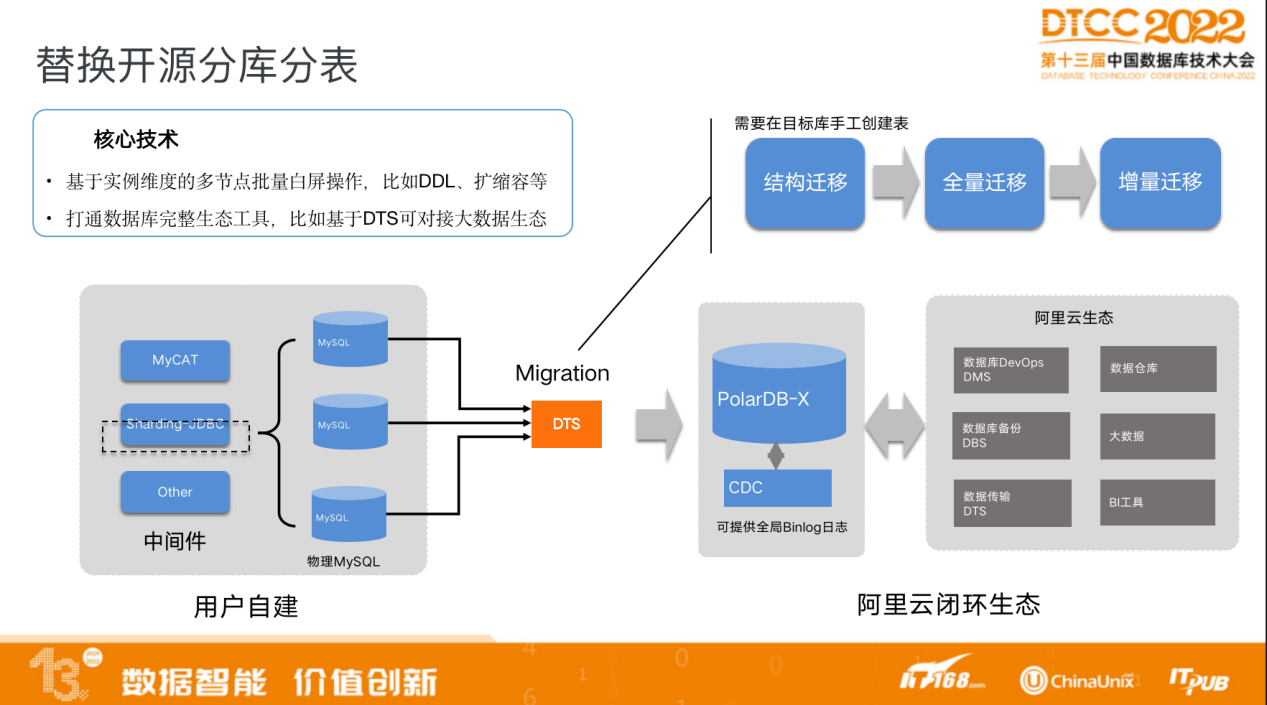
PolarDB-X有以下几种典型的应用场景。
PolarDB-X 可以用于替换开源分库分表。
可以将用户自建数据库通过DTS同步到PolarDB-X集群,可以对原有的建表做结构迁移、将数据做全量迁移以及做实时的增量迁移。
PolarDB-X 支持分库分表的模式,对接原有的分库分表时无需对用户应用做过多改动。
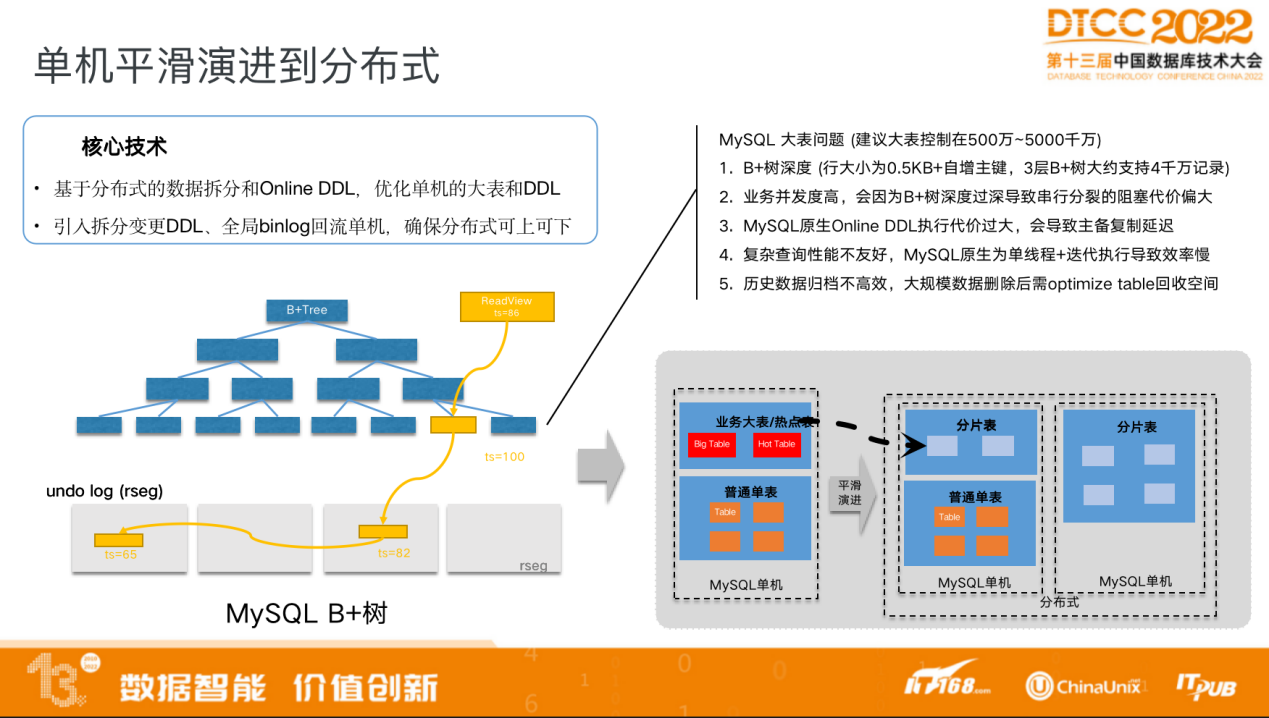
PolarDB-X还可用于单机平滑演进到分布式。
单机 MySQL 的数据库可以一键迁移到线上分布式数据库,应用 0 修改,在PolarDB-X上直接实现建表语句即可。
完成演进后,原先在单机 MySQL 上难以解决的问题,比如大表如何做拆分等问题都可以在分布式系统上得到很好的解决。分布式系统对于不同的表有不同的解决方法,比如大表可以做成分区表,按指定的方式做分区;比如针对热点表,可以将热点打散后做成分区表;一些普通的单表迁到分布式系统后依然可以作为单表使用。
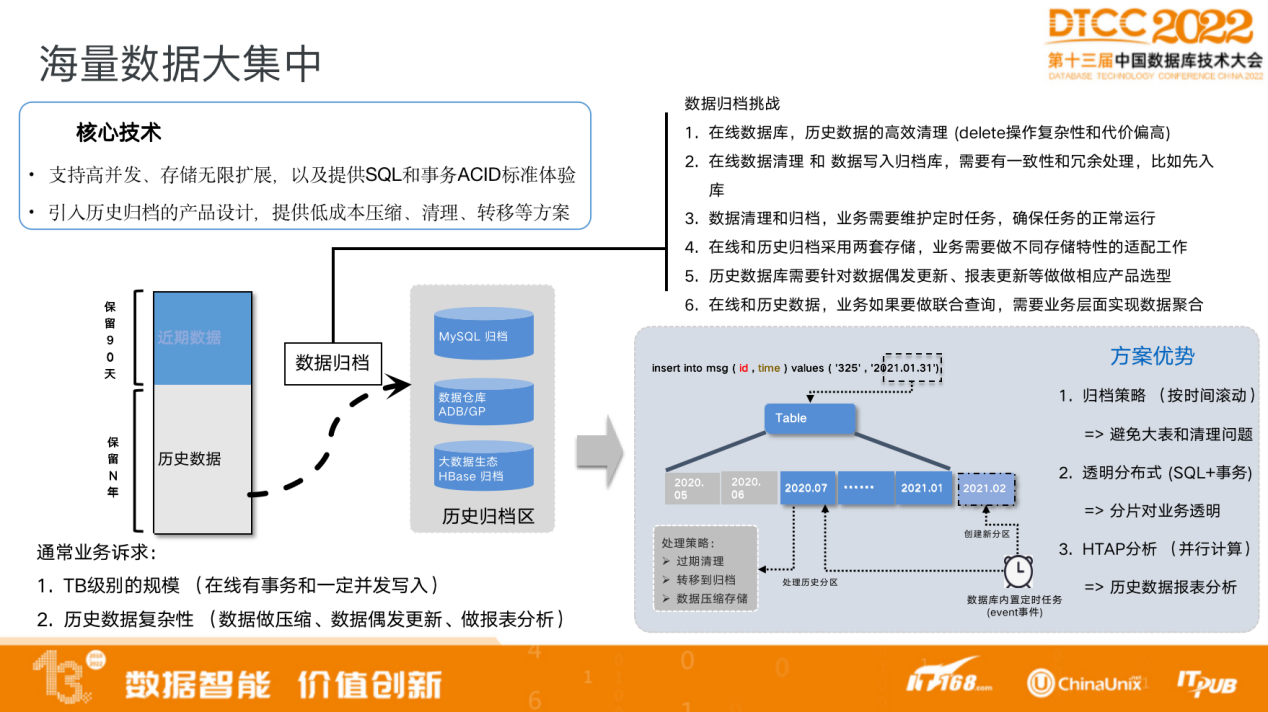
PolarDB-X的另一典型场景是海量数据大集中。
原先的系统中使用了很多数据库,各种数据库之间存在数据孤岛问题,如何做融合的查询分析?
PolarDB-X结合DTS 以及ADB提供了一整套解决方案,同时满足在线数据的处理以及在线数据分析的需要。PolarDB-X还可与ADB做深度融合,中间不再需要数据传输的工具,只需进行实时的数据转换,ADB实时分析转换好的内存的数据副本,实现完全一体化的数据处理以及数据分析的一致性体验。
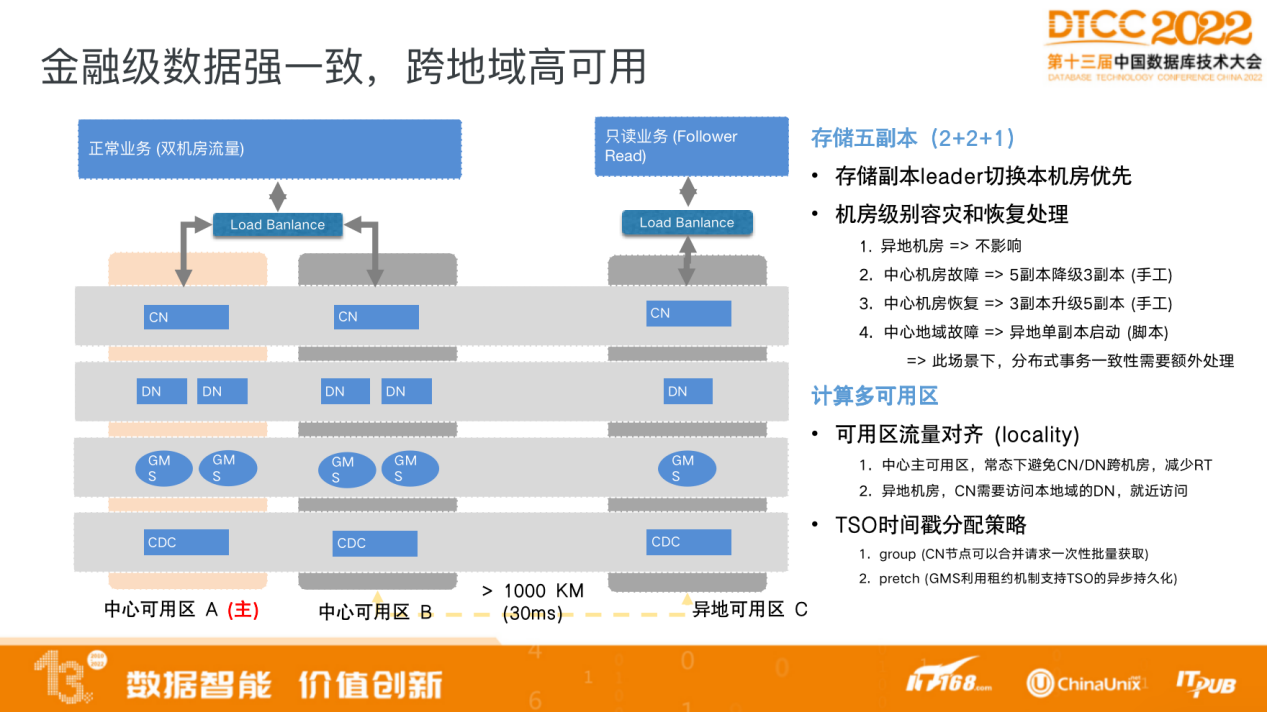
针对金融场景的数据强一致需求,PolarDB-X也能提供非常完备的高可用解决方案以及灾备方案,包括同城多机房、两地三中心等解决方案,能够保证跨地域的高可用、机房级别的容灾以及保证数据的一致性。
未来,PolarDB-X将持续往一体化方向演进。
包括集中分布式一体化:要使分布式数据库更加接近于单机数据库的体验;负载处理一体化:能够处理 transaction 和 analytic 的负载。也包括在线和历史数据一体化,与云的基础设施更加深度的融合,利用云底下的共享存储、云的芯片做硬件结合的一体化。
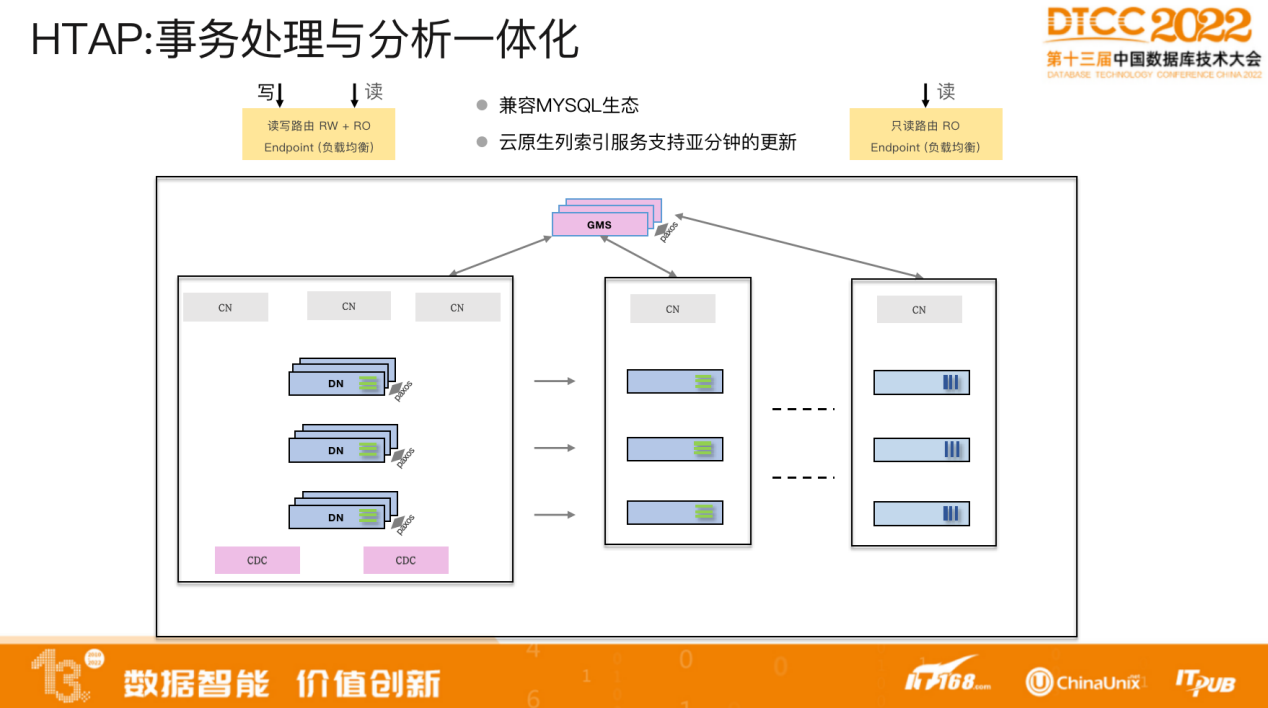
事务处理与分析一体化利用CDC做实时同步,存放到云存储上,以列式的压缩格式做存储。同时 CN 也支持行列混合的分析查询,对优化器具有较高要求,需要能够识别出处理事务与查询事务,判断将其放于行存执行还是列存上执行,计算具体的cost。
未来,我们也计划通过ADB数仓利用大规模数据分析的计算引擎做一体化的分析工作。
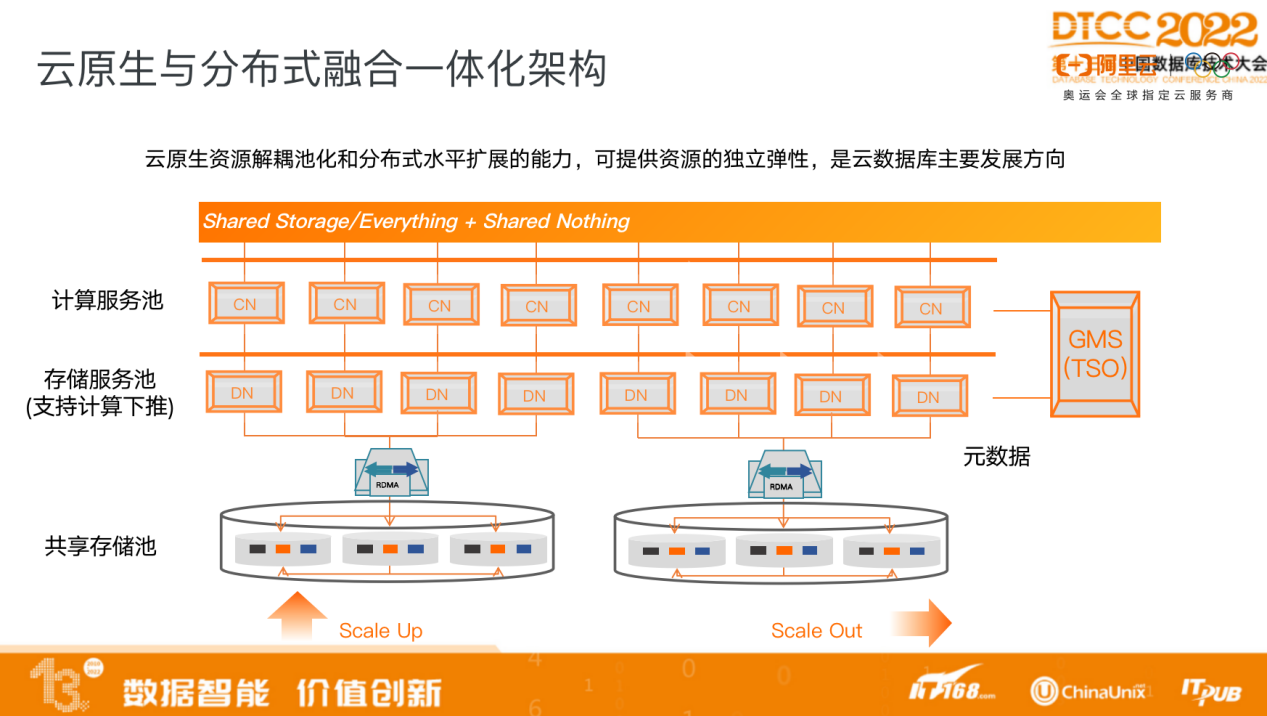
云原生与分布式融合一体化架构也是未来发展趋势。
目前所有的DN数据存储在本地磁盘,未来会将其存储到共享存储池,这是未来分布式数据库发展的重要方向。
我们在做扩展时应尽量不动数据,而是实时或独立地扩展计算节点和存储节点。扩展了节点以后,数据要做大量搬迁工作。而如果底下是共享存储,则无须进行搬迁工作,新增节点后即可投入服务。
另外,共享存储能够存储的数据量会远远超过单机的数据规模,也更有可能减少数据跨分区的可能性,从而有效减少分布式事务带来的代价。
如何更好地利用云的基础设施提供更好的扩展能力以及弹性能力的分布式数据库,是未来云原生分布式数据库的重要发展方向。

