探秘星环科技多模型数据统一存储的大数据数字底座设计
中国信通院在《数据库发展研究报告(2021 年)》中指出,在后关系型数据库阶段,数据结构越来越灵活多样、业务类型越来越复杂多变,为应对此类现状,越来越多的用户选择通过多模型数据库实现“一库多用“,将各种类型的数据进行集中存储、查询和处理,满足对结构化、半结构化和非结构化数据的统一管理需求。
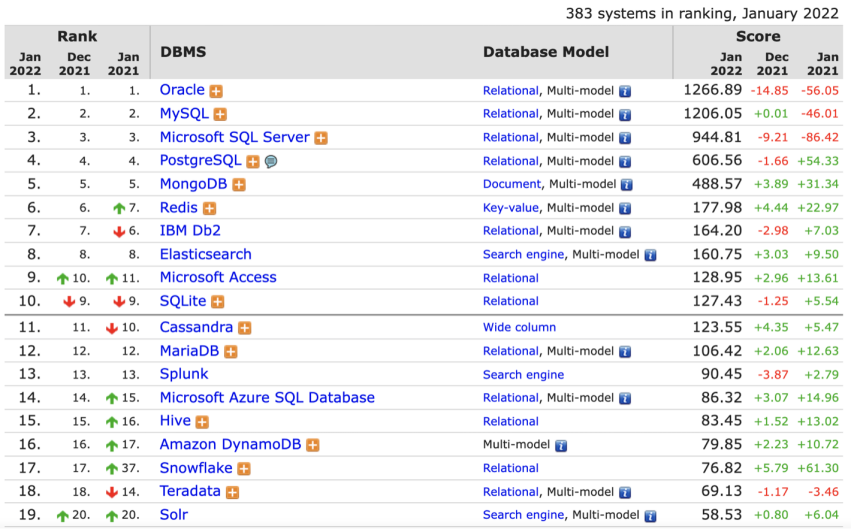
从DB Ranking的一项排名数据也可以看出:前二十中有十三个产品中已经支持多模型,这无疑从对用户需求最敏感的厂商行为中看出,多模数据库是一个趋势。
那么,什么是多模数据库?星环信息科技(上海)股份有限公司高级系统架构师郭卓异用维基百科的定义做了解读。多模数据库(Multi-modeldatabase)是下一代新型数据库,与传统的数据库系统只支持单一数据模型不同,多模数据库是一种在统一、综合的平台下同时支持多种不同的数据模型的数据库,这些数据模型可包括传统的关系模型和NoSQL数据模型(文档模型,键值模型,图模型),一个重要的特性是,多模数据库拥有自己的一种或多种查询语言,可以非常灵活的方式访问多种不同数据模型,甚至是跨模型的JOIN操作,这使得数据组织、存储、操作较以往更加灵活、便捷。
多模型大数据数字底座是如何打造的?
接下来,我们看看星环科技的多模型大数据底座是如何构建的。
既然要管理不同模型的数据,那么首先要做的就是对不同的数据库进行模块分层拆解。
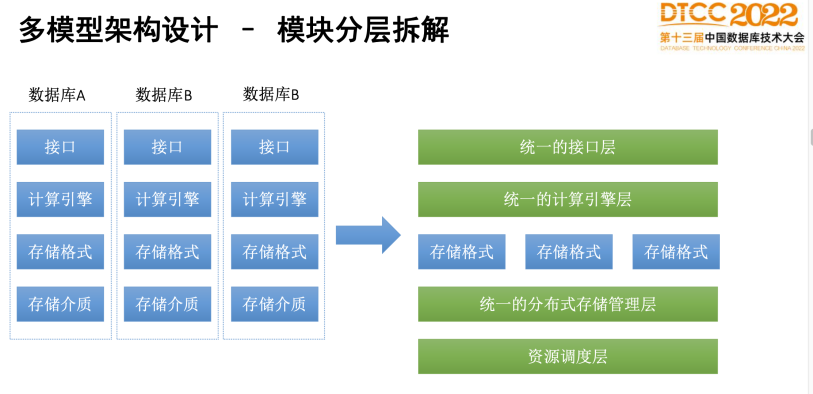
郭卓异表示,星环科技对市场上不同数据库拆解后发现,数据库都包括接口、计算引擎、存储格式以及存储介质等四个模块。而多模数据库应该是一种原生支持各种数据模型,有着统一访问接口,能自动化管理各模型的数据转化,模式进化且避免数据冗余的新型数据库系统。
星环科技对每层功能做了细分设计,具体来说,计算接口层就是做好SQL编译,针对不同语法编译可以做适配优化,不仅仅是兼容不同数据库语法,也可以兼容不同模型语法。计算引擎层实现的是分布式计算的抽象通用功能,比如可以统一实现通用算子和通用执行优化、向量化等等通用计算引擎的优化技术。存储引擎层要实现的是针对不同的存储模型用不同的存储引擎来处理,例如关系型引擎选取的就是TP或者AP引擎。存储管理层是做统一的分布式存储管理,包括灾备、负载均衡、副本、一致性协议、数据分布、弹性伸缩,这些抽象的分布式数据管理,都可以在这一层运作。资源管理层,就是统一对CPU、内存、网络、磁盘,包括容器做统一的资源管理,整个架构设计都是基于容器化部署,所以资源管理层会有容器编排工作。
以资源调度层为例,星环科技在做统一资源管理时,是基于容器技术和容器编排技术对平台所有的服务和进程进行统一管理和隔离的。这样可以保证不同业务和不同进程之间可以做到资源隔离,不会互相影响。
基于容器化的设计方式让星环科技产品在很多场景上都有比较大的优势。
例如在做Overlay容器网络时,可以将内部和外部网络做一个隔断,将网络权限管理做得更精细化,保证整个集群的安全。
基于容器化还可以让平台和产品可以快速地适配各种公有云、私有云、混合云、多态云,因为现在大部分的云技术都是容器化的平台,本身也是基于容器化去实现的,所以对接起来会非常方便。在可扩展方面,也可以实现模块化、插件化、可挂载和可组合等优势。最后是自修复方面,可以实现自动部署、自动重启、自动复制和自动伸缩。
郭卓异特别强调,基于容器化的部署,可以方便地支持国产化操作系统:容器平台和各种国产软硬件以及不同操作系统适配以后,上层容器应用基本上不会有太大的改动。
在与客户的沟通过程中,星环科技注意到大数据客户面临两大挑战,其一,Hadoop自身的局限性不断暴露出来,例如HDFS存储的文件总数受限于namenode的2亿内存总量,已经无法满足用户的需求。其二,用户开始有了对象存储的需求,因此会增加系统管理的复杂性。
星环科技对于这两大问题做了非常有针对性的应对。
例如在元数据层面,可以说是读写性能俱佳,新的分布式文件系统TDFS(Transwarp Distributed File System)支持10亿以上文件数,远超开源HDFS 5倍,在4亿文件规模下,服务启动时间比开源HDFS快16倍,元数据QPS比开源HDFS快1.7倍。此外,还可以支持Hadoop上层生态组件,支持HDFS原地升级,不影响原有数据。星环科技也做了S3协议兼容,客户直接可以通过S3协议使用TDFS作为对象存储使用,避免部署多套系统,一套TDFS可以同时满足分布式存储和对象存储。
TDH9.0:基于多模型统一架构搭建出来的平台有多香
星环科技基于多模型统一架构设计,打造了星环多模型大数据基础平台TDH9.0,根据不同模型处理的业务需求包装成了十一个产品,除了实时流计算引擎SlipStream以及Sophon Discover数据科学平台没有存储模型,其他9种存储引擎可支持10种数据模型,同时对存储引擎进行升级,提供更高的性能和更强的功能,帮助企业用户满足更多以及要求更高的业务场景。

郭卓异强调,星环科技的TDH基于多模型统一技术架构,提供统一的接口层、统一的计算引擎层、统一的分布式存储管理层和统一的资源调度层,在保障不同数据模型高性能、高可靠、高可用的同时,实现了资源配置更灵活、操作运维更简洁易用的目标。
首先,基于统一的SQL编译器Transwarp Quark,可以实现统一接口处理不同的业务和不同数据模型,降低了开发和迁移成本,并且有很强的兼容性。
其次,基于分布式计算引擎Transwarp Nucleon,可以根据不同的存储引擎自动匹配高性能算法,可以支持批处理、流处理等不同类型计算任务,可以做跨模型数据流转和复杂关联分析、跨平台联邦计算,降低开发难度,提升开发效率。
再次,用户不需要为不同模型建立单独的存储系统,而是通过统一的分布式数据管理系统,一个平台支持多种模型数据的统一存储管理,降低了运维管理成本,也避免了数据孤岛,并且可以灵活地拓展业务。
最后,星环科技自主研发的云原生操作系统TCOS,可以提供统一的资源管理框架,基于容器编排操作系统统一管理配置资源,通过容器化编排,能够统一调度计算、存储、网络等各基础资源,并且保证资源隔离互不影响,部署扩容更加便捷。
那么在星环科技的TDH 9.0的帮助下,用户可以很轻松地通过多模型联合分析应用来应对很多场景,包括关系型数据导入图、图数据导出至关系型表、事件数据实时消费处理、跨模型数据流转以及全文检索+精确检索、时空查询等等。
以跨模型数据流转为例,HBase单条数据插入随机读写很快,但是批量插入数据的时候性能会比较差。业内比较常见的做法是写一段程序,提前把要插入的HBase数据组装成一个HFile,但这需要去写程序、做开发。而对于星环科技而言,用户可以直接通过SQL语法实现数据从关系型数据,用Bulkload的方式批量导入到宽表数据库,一个SQL就能够实现,不需要写很复杂的程序,直接用一个SQL就可以实现跨模型Bulkload。
正是通过这一个个数据库基础应用场景和案例的打造,星环科技成为数据库行业创新的典范,同时,星环科技对多模数据库领域趋势的把握也得到了业界的肯定。近期,星环科技作为中国四家多模数据库代表之一入选Gartner《中国数据库管理系统供应商甄选》。除了多模数据库之外,星环科技入选的数据库产品还覆盖了交易型数据库、图数据库、时序数据库、键值数据库、文档数据库、宽表数据库等,堪称中国数据库产品最全厂商之一。

