数据库运维监控中基线预警的局限性
基线预警数据库运维监控中的重要手段之一,通过基线发现系统中某些指标存在的不合理波动,进而提前预警,是一种数据库运维监控中最为常用的手段,也是目前大多数企业正在使用的主要监控方案。
虽然大家都用基线预警,不过大家关注的基线指标与阈值都存在较大的差异。因为虽然大家使用的数据库的种类相同,但是大家的系统都存在较大的差异。具体用哪些指标来做预警,以及设定什么样的阈值,这是十分个性化的。实际上一个能够真正起作用的基线预警系统,里面都包含了大量的运维经验。
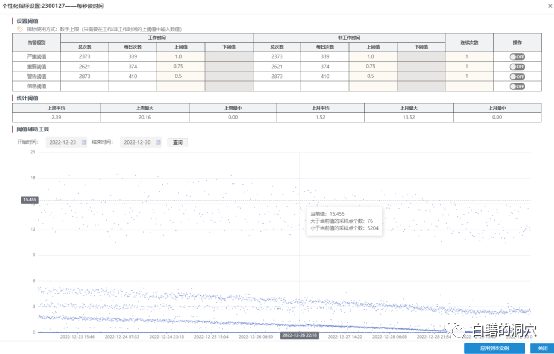
以每秒读时间这个指标为例,我们可以看出其取值范围波动是较大的,并且没有明显的聚集特性,此类指标我们该如何设置基线呢?确实也是有些头疼的事情。
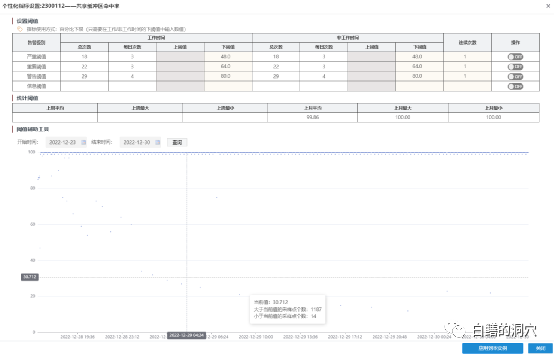
再来看看另外一个数据库的共享缓存区命中率,其点的集中度还是比较集中,但是还是存在散落分布的,差异很大的值。这些值要不要告警呢?告警对我们的运维有什么意义呢?也真的说不清楚。而且如果我们运维数百套,甚至上千套类似的数据库系统,我们也无法对这些数据库系统设置合理的基线阈值。如果不去做个性化的设置,那么基线告警就不准确,运维告警工作陷入了两难的境地。
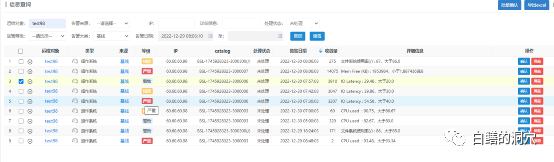
可能有朋友会说,干嘛不用动态基线或者智能基线。确实动态基线可以避免上面说的问题,但是动态基线就一定有意义吗?我们来看上面有一个严重的IO LATCNCY基线告警。
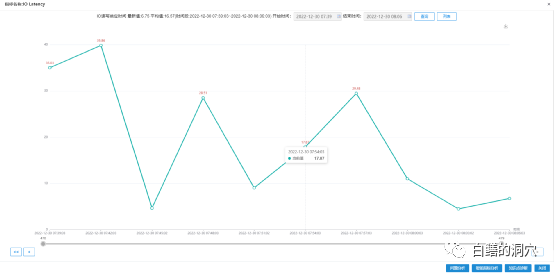
IO延时出现了较为严重的波动,但是这有代表了什么含义呢?要不要发短信告警呢?运维人员收到短信要不要去处置呢?要不要对这个告警做闭环管理呢?我们还是搞不清楚,运维告警的意义一方面是发现系统的隐患,另外一方面是在系统出现严重故障前提前警示。似乎这个被标称为“严重”的基线告警,对我们运维的帮助也没有那么大。
从上面的例子我们看到了基线告警的局限性,简单的单一指标异常为核心的基线告警并不能预示某类故障的发生,因此基线告警对于运维的作用就大大降低了。对基线告警进行简单的升级,通过规则引擎构建故障模型,会有更好的效果。比如刚才的这个通过动态基线产生的IO延时基线异常,如果再叠加一些其他的条件,就可以构建出一个更有指向性的告警出来。比如IO延时基线异常,同时操作系统出现大量的IO方面的告警,或者出现多路径链路切换,这样的告警其指向性就更强了,而且告警的价值也大大提高了。
从另外一个角度来看,IO延时基线异常,同时IO吞吐量也大幅提高,某条关键SQL的执行时间也变长了,这种告警也更具有价值。也更值得做闭环管理。
通过故障模型替代基线告警,还有一个好处,那就是告警的指向性更强,因此当告警发生时,诊断问题的原因也变得简单了很多,因为单一指标异常的可能原因过于复杂,大多数情况下让人无法入手分析。而故障模型叠加了很多其他因素,因此故障的指向性也更强了,分析问题的时候也就更容易了。这也是现在D-SMART的基线告警并不推送到告警台,而用故障模型告警替代的主要原因。

