DTCC 2022 | 具备混合负载能力的分布式KV存储-KeeWiDB
【嘉宾介绍:
伍旭飞 腾讯云 数据库专家工程师。拥有10余年工作经验,在游戏和数据库领域有丰富的开发经验,目前专注数据库内核方向的开发和技术演进。】
———————————————————————————————————
以下为DTCC大会腾讯云 数据库专家工程师伍旭飞的演讲实录:
互联网业务的挑战
互联网的在线业务场景中,80%的数据是KV结构,其访问模型也以点读、批读和点更新为主。为了提升服务的用户体验,分布式缓存是业务架构中不可缺失的一环,同一份数据需要在缓存和存储组建中流动,而且是靠业务来实现,对开发者和维护者并不友好。
在硬件和软件持续发展的今天,是否有更好的KV存储方案,能够提供缓存和存储的混合负载能力,是腾讯云NoSQL数据库团队一直在研究的方向,这次分享将介绍腾讯云自研分布式KV数据库KeeWiDB,缓存+存储一体化能力,简化开发,为开发者带来全新的存储解决方案。
很早以前其实并无NoSQL和KV这种数据库类型,不禁思考为何会有?
SQL的出现我觉得是比较自然的,当年在学关系型数据库的时侯都会以管理系统或者交易系统作为案例加以研究,因此SQL本质上是从学术界发展起来,然后再到工程界实现出来,最后到实际应用中加以应用,这是一个完整的过程,从理论推导到最后的实现。
NoSQL的出现,流程上恰恰相反,其实当时内部研发的时段也是2011年到2012年左右,与互联网的发展同步,包括腾讯内部早期也是在此阶段,甚至还要更早一点。
互联网业务的主要特点
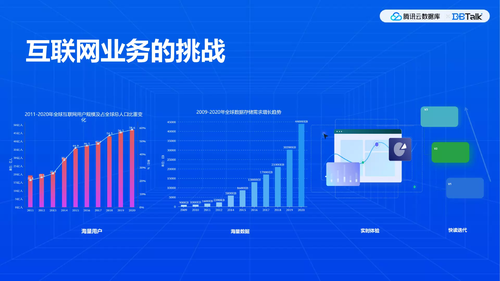
首先是用户量越来越大。跟传统的银行的交易系统相比,服务的人很多,但其实并发量并不高,而互联网业务到2020年已占到几十亿人口的比重,量越来越大,我们将其归纳为海量用户。
数据存储量也在增加,传统银行的交易数据,每个用户无非是一些关于存款和交易记录的,业务模型相对稳定,数据量是有限的。互联网业务起来之后,各种数据增长的幅度接近指数级,到2020年整个增长曲线非常之快,并非线性增长的环节,数据量越来越大,传统的关系型数据库也不一定能够很好地适应。
实时体验是针对移动时代来临之后,随着竞争逐步加剧,要求越来越高而产生的需求,以前对SQL关系型数据库的延时要求并不高,比如在玩魔兽世界时,最初均要排队,除了是因为新手村之外,很大一部分原因是数据库扛不住服务几十万用户瞬间秒进来,担心把数据库打爆,所以互联网业务对实时性、延迟性能要求越来越高,很难理解登录QQ和微信需要排队。
当然,我觉得对研发来说最主要的是因为快速迭代。做互联网和做软件大不一样,做软件有正常的迭代计划,产品按部就班来做即可。互联网产品叫做快速试错,无论是电商业务还是游戏业务,各种数据字段随着业务的变化加得非常快,所以在此种情况下若仍旧用关系型数据库去做,存储这一端的变动很难跟上迭代节奏,我认为这是一个重要的驱动点。
NoSQL的自发诞生
面临诸多挑战,慢慢地诞生了NoSQL数据库。
我也是很多年前做游戏的时候用SQL Server和MySQL,每个用户属性、字段加得越来越多,今天加一点,明天加一点,不停地加,后来觉得太麻烦,索性能否直接存成一个BLOB?关系型数据库好像等于弱化成KV了,慢慢地就会有这些组件产生,这些均为自发产生的原因。
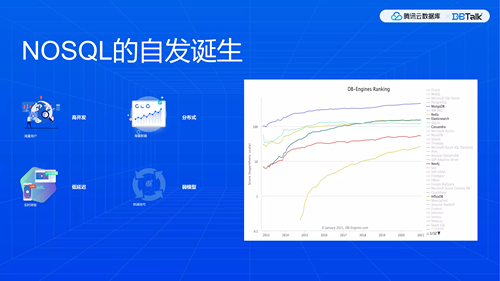
就上述内容加以总结,梳理以下几点:
高并发,并发量的要求非常之高,超过以往对关系型数据库、TP数据库的要求。
分布式,因为数据量特别大,其实我们并不想像以前在用关系型拆库拆表的做法,这种方法最开始大致预定好一个用户数规模数,拆完以后用户量上来,实则操作起来比较麻烦。
低延迟,就是竞争。这与用户对体验的极致追求有关系。
弱模型,还是为了业务的快速迭代开发。
人生很短-Redis很快
大家可以从下图发现,随着移动时代的发展,整个非关系型的数据库的发展节奏非常快,且会越来越快。
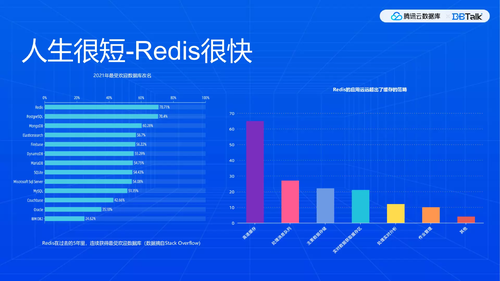
讲一讲Redis,因为keewiDB是兼容Redis的数据库。
Redis设计之初是当作缓存的,我们相信作者包括开发者、我们自己运营腾讯云,也是希望用户将其当作缓存来用。不过用户一般来说不会按照我们的设想去用,原因是什么呢?包括与其他一些用户也探讨过,其核心原因就在于现在研发节奏很快,产品需要快速试错的话,很多时候都是通过原型试错。
而此时若只是把Redis当作缓存,或者挂MySQL这样的传输型数据库,开发起来需要花很多时间。我们认为人生太短了,成功要快,所以目前Redis应用,远远超出了缓存的范畴。
“不要你觉得,我要我觉得”
“我觉得”客户应该这样用,客户觉得“不要你觉得,我要我觉得”,就是喜欢这样用。什么原因呢?
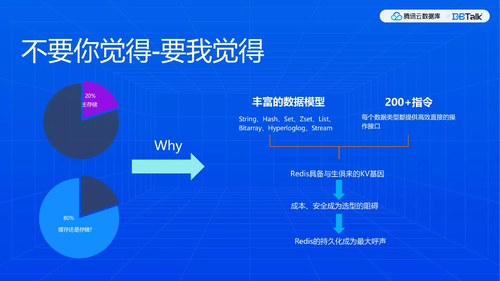
Redis本身提供了诸多丰富的数据模型和与生俱来的KV基因,很多时候成本对开发者原型阶段,其实倒是问题不大,很容易Cover。原型验证以后,要是业务一旦火爆起来,实则会面临很大挑战。挑战重重,原因为何?
互联网业务用户量很大,实则活跃用户量并不一定是在大部分,按照经典二八原则,若有20%的活跃用户其实算是不错了。从这一点来说,用户喜欢把redis当存储用,我们没办法教育用户,有的时候被用户推着走,怎么办呢?
欲练神功-各显神通
其实是从用户的角度,推动行业内需要高性能、持久化的兼容Redis协议的存储数据库。
下述所举的例子,友商和其他行业有很多都是这样做的,大家各显神通想要解决问题。
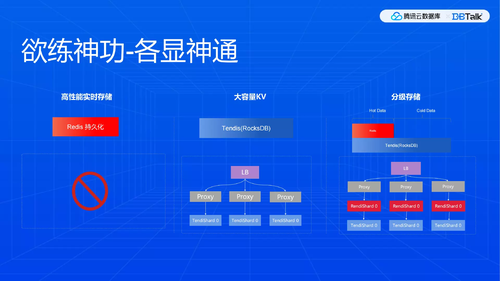
最早Redis有一种持久化方案,即RDB,保证数据尽可能不丢,本身还是在内存里面。不过该成本太高,不具有现实意义。
RedisLab有一个RedisFlash版本,可以支持一部分冷热分离,目前从社区和其他一些客户侧也并未看到特别好的反馈,许是样本数太少,这条路基本上是直接在Redis修改代码, 实则不太现实,因为Redis本身是为内存设计的,数据结构都是基于内存设计的,需要改装成磁盘型数据库并非易事。Redis2.4做过一个尝试,即用户态Virtual Memory机制,2.6版本就已经移除了,因为效果太差,根本无法使用。
大部分的kv是底层拿RocksDB来做,模拟Redis,其实这种做法也可以,当前也在运营这样的版本,但我们觉得这并非是一个好未来。通过Rocks模拟Redis结构不是那么自然,很多场景下很难做到想要达到的效果。
很多客户自己内部也在实现冷热分级,中间做一个缓存,缓存读不到再去下层读,就是从缓存慢慢地到最终的底层存储。但是此种方案存在一个比较大的问题,对存储安全性很难得以真正解决。
最后一种方案感觉上很自然,redis+ mysql,大家可能直接觉得性能应该不错,感觉很自然,但解决不了根本问题。最难解决的是缓存的一致性,击穿其实也比较难解决,雪崩是因为一致性和击穿导致。最主要的核心问题还是一致性,非常难处理,如果写入内存以后要保证持久化,必须要到磁盘存储,这个缓存只用于读加速。
先天缺陷
然而读加速依然存在一个问题,即比较大的哈希。若命中不了,便要从磁盘将整个哈希读到内存里面,工作量非常之大。几百万field的hash从磁盘读到里面的话可能会很久,需要分钟级别。
线上有些血泪史,早期无论是在友商还是腾讯云都会踩到该种问题,这是一个先天缺陷。
我经常思考,做一件事情时若你觉得很难,行业领军人物会怎么做?图灵奖得主会怎么做?
得到的结论是:他们可能一样做不好,因为这条路就是错的,没有人能做得好。果然,行业内友商和我们一样放弃了这条路,在Pika、HBase、MySQL、TiKV加上Redis的独立缓存方式,是做不好的。
年轻人的第一本武功秘籍
到了这一步,我们就在想,要做一个兼容Redis持久化的数据库,怎么办?
假如我们对存储型数据库一无所知,准备年轻人的第一本武功秘籍。
B+树:
大部分TP数据库,包括MySQL和PG都是用B+树做底层的存储引擎,也是很自然的。
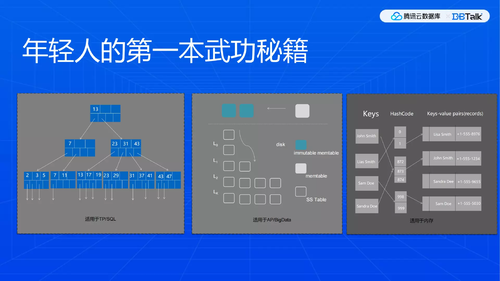
正常情况下,SQL一般是range查询非常多,所以用B+树是非常自然的也是目前为止非常有效的一种办法。
LSM Tree:
我理解真的是因为大数据的到来才有这种场景,特点就是写得快,通过compaction,避免数据量过高。Lsm tree牺牲了读性能,读取路径比较长,最长可能是L0的所有文件加上后面每个level都要读取一个文件, 不适合我们keewiDB的目标场景读多写少。
内存hash:
最后就是Redis和其他的内存数据库都在用的哈希,内存最快,这是没有疑问的。
道法自然-KeewiDB 存储引擎
了解一般数据库是怎么做的以后,再思考下要做一个KeewiDB该从何着手。
上述讲了通过rocksdb实现Redis,我觉得是不自然的,为何?因为了解的都觉得有点像小无相功模拟少林寺七十二绝技,倒也能用,但效果没那么好。因为RocksDB本身还是KV数据库,所以如果要直接用KV模拟,特别是后面的哈希、ZSet这些数据结构,其实没有那么自然,也很难达到好的效果。
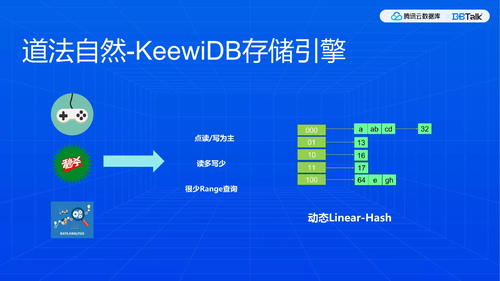
基于此种思考,keewiDB的目标场景其实是点读写为主。一般来说读会多一点,因为写大部分意味着创造,其实互联网创造的东西没有那么多,但看的人更多,无论是微博还是其他均是如此。Range查询相对比较少,也不是完全没有,所以我们觉得这应该是用哈希作为底层最核心的存储引擎。
哈希分为两种,静态哈希就像Redis,每次不够就会Double一下, 这个特性在Redis也会有问题,Double很容易导致慢查询,线上常遇到此种问题,要是磁盘上更不能Double,非常大的Copy量,整个数据库就会被长时间卡住。
腾讯云数据库最后的选型就是动态线性哈希,动态hash分为两种:Extendible Hash和linear Hash,每次只扩一个,这里是从2个Bit扩到3个Bit,不够用了再扩到100,会从000那里拆出一半过来,按照Hash Bit拆出一部分。如此一来有个好处,即只会扩一个位置,其实是一个渐进式的扩展概念,对延迟更加平稳,我们觉得这是一个比较好的方法,至少适合腾讯云作为主引擎不错的一个选择。
神兵利器-持久内存
有了好的内功以后,便一定能够特别强吗?是否仍旧需要一些好的设备?
其实是在持久化能力上,目前KeewiDB混合存储版就是利用OPTANE这样的持久化能力,大家可能也知道一些消息。目前从我们的角度来说,未来还是会有替代品出现。

当然,腾讯云的方案也不完全依赖于此,有了好的内功,就算没有好的兵器也能够做得很好,有就先用着。还需要提升表现,下文会再提到最终效果。
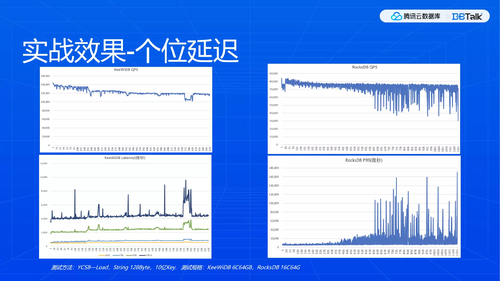
实战效果-个位延迟
下图为实战效果,比RocksDB占用资源更少,但在QPS更稳定,延迟更低。再跟友商对比,现在依然领先。可以看到10亿Key、128字节的测试,基本上是个位数延迟,在如此大量持久的场景下,用更少的核心,实现了更高的QPS和更稳定的低延迟。
我们这个地方是不是只是做了这样一些东西,引擎放进去就好了?其实不是,我们还有很多软件上的优化。
软件上目前数据库大部分都会用多线程,上述也讲过一个例子,MySQL可以并发,单SQL只能有一个线程处理SQL查询。我们如果真的这样做,其实资源等无法控制,长久来看一定会有互相影响。软件其实是用了多线程和异步IO方案以及协程编程,可以做到用更少的资源能够更大地并发,更好的资源隔离性做到上述效果。
可以这样讲,当前基本上已经达到预期目标,就是命令级持久化,个位数延迟。KeeWiDB足够稳定,不像RocksDB的QPS和延迟抖动非常厉害。可预测的性能稳定是最关键的要点,甚至超过对极致性能的诉求。延时也是一样,测试场景下保证在10毫秒以下,简称为个位数毫秒的延时。
以上就是当前的效果,过两天KeeWiDB就会完全商业化,正式对外开放,欢迎大家去体验。
我们已经做到这一阶段,将来怎么样?未来是什么趋势?
未来趋势
目前我们其实是Share Nothing的架构,Proxy+DB。该种架构有一个不太友好的地方,要是涉及到数据划片的话,KeeWiDB其实是支持单点事务级别的数据库,Redis没有办法做到事务级别。
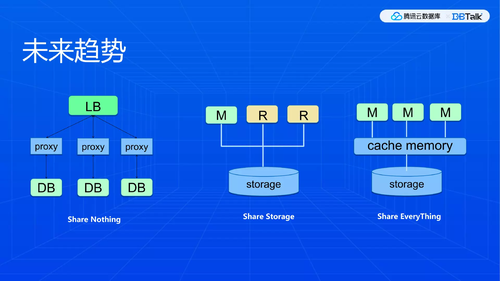
举个例子,Redis执行事务失败了无法回滚,KeeWiDB是存储型数据库,能够支持原子性和一致性,即支持事务的ACID。Share Nothing有一个问题,我们要做分布式事务只能在Proxy上来做,兼容性很难做得非常完美,而且对开发量也非常大,稍不留神就会跟不上。若100%做到,需要投入很大精力,并非易事。我认为未来Share Nothing不一定是一个好的趋势,可能只是特定场景下的妥协。
Share Storage 前几年比较火,但Oracle二十年前就做了,对客户的意义不一定那么明显,因为用起来和单机数据库一样。作为云厂商对资源的利用有很大用处,优点就是兼容性特别好,容量非常大,扩容很快,缺点也是一样,不太容易做到性能水平扩展。
随着CXL和RDMA技术的进展越来越快,Share Everything或许会是一个更好的办法。CXL发展过后,将来可能会在Share Everything重新大放异彩。以前Oracle做的模式叫做Real Application Clusters,我们也会长期关注,等待新硬件发展以后,未来三五年内会大放异彩,会有很多新的产品跟进。KeeWiDB也是一样,时刻关注前沿技术,并与大家一起探讨。

