星环科技TDH多模型统一架构VS CDH散装架构
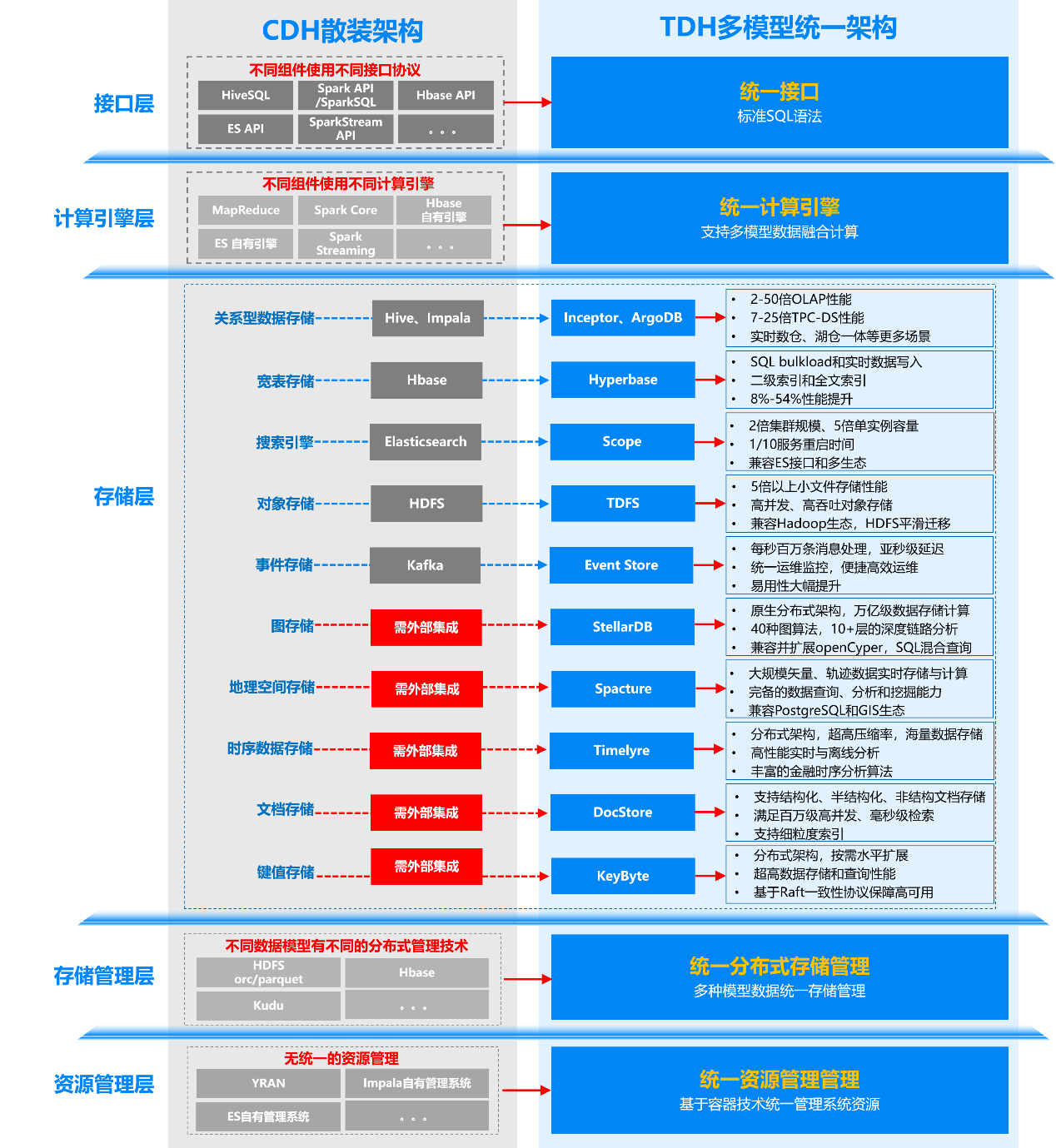
一图看懂CDH散装架构和TDH多模型统一架构
CDH是Cloudera的开源平台发行版,通过将Hadoop与其他十几个开源项目集成,为企业大数据业务提供服务。
在CDH开源大数据方案中,是通过多个互相独立的组件提供相应的能力,每个场景需要一个组件独立交付,为了实现不同业务需求,通常用户需要部署多个不同的产品。比如为了做数仓需要Hive,为了做精确查询需要Hbase,为了做搜索业务需要Elasticsearch等等。那客户为了实现图计算和分析,需要另外单独部署如开源图数据库Neo4j,为了实现时序数据存储分析,需要另外单独部署开源时序数据库InfluxDB等等。
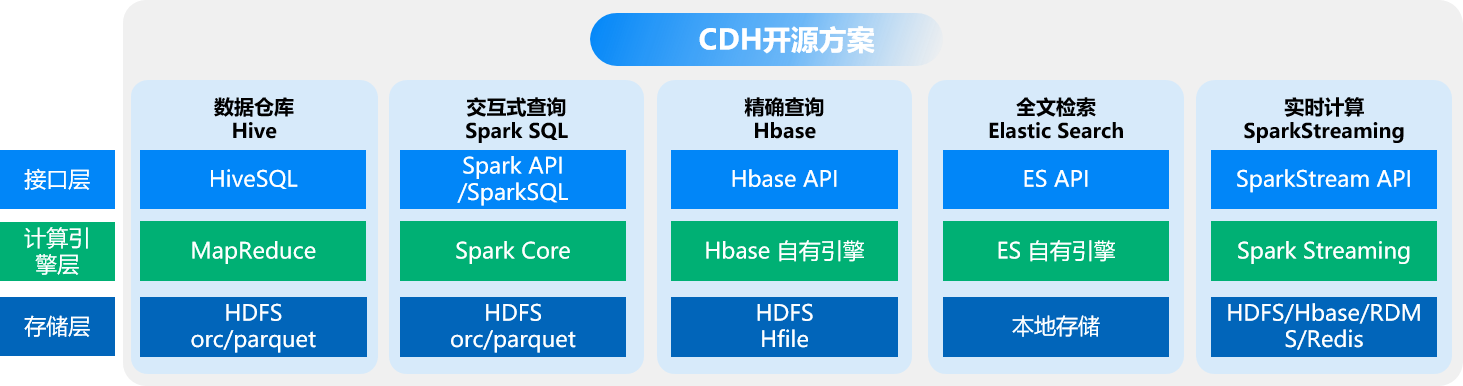
在复杂场景下,CDH需要多个组件配合完成,多个组件的开发语言和接口基本完全不同,用户需要学习适配多个产品的不同接口,开发成本高。同样的,这些产品也使用了各自独立的计算引擎和存储,数据存储在各自的生态中难以互通,若需要把数据从一个产品导入到另一个产品中,需要通过文本离线导入导出,ETL流转效率低,同时也难以保证数据的准确性、一致性和实效性。数据往往在离线流转过程中,可能因为编码或浮点数精度问题,导致数据不一致,最终影响业务准确性。各自独立的计算引擎若部署在同一节点上,也可能会引起计算资源竞争等问题。
总体来说,CDH拼凑起来的散装架构复杂度高,客户新业务开发、业务需求变更开发成本极高,运维成本也极高,数据流转和融合分析等数据处理效率低。
CDH散装架构跨模型分析方案
下面我们来举个例子。
比如当用户需要研究某特定年纪人群消费习惯和喜好时,可以通过将该人群消费的商品评价作为一个参考。为了获得该人群对某商品的评价数据,用户需要单独搭建3个独立的数据库,如单独部署图数据库,关系型数据库和搜索引擎。为了完成此次业务,用户需要进行三次检索,并需要使用到图数据库中的人群关系型数据,关系型数据库中的人群消费记录数据,以及搜索引擎中消费商品评价数据。
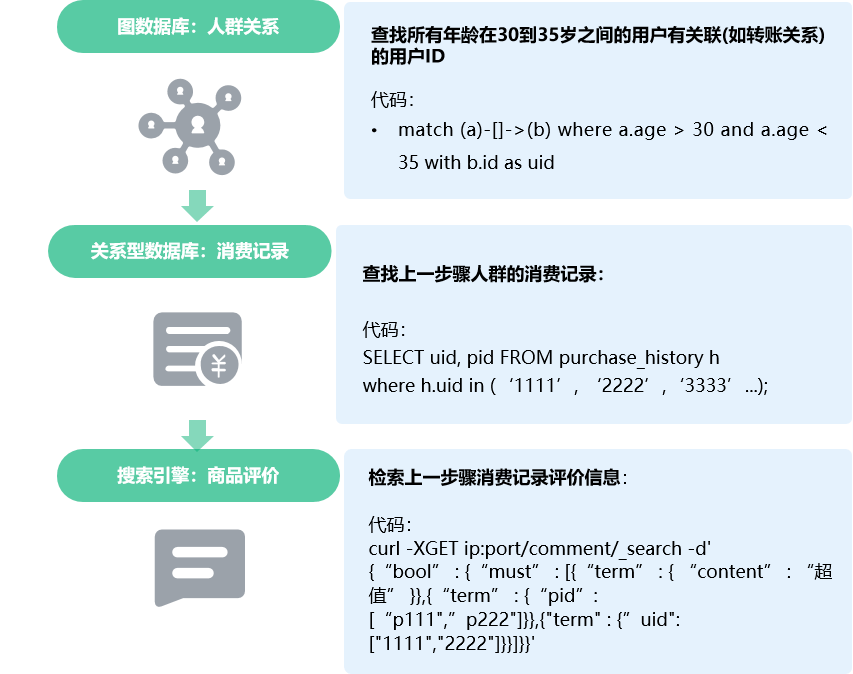
第一步,定位某特定年龄段的人群。用户需要连接到图数据库中,使用图数据库查询语言Cyper,找出30岁到35岁之间的有如转账关系的人群。
第二步,获取该人群的消费记录。基于第一步中获取的人群,用户需要再连接到关系型数据库中,使用SQL查询语言,获取该人群消费商品信息。
第三步,获取包含特定关键词的商品评价。用户需要再连到搜索引擎,编写RESTful API请求,使用前两步获取的人群信息和消费商品信息,检索商品评价。
为了完成这个业务,用户单独搭建了3个独立的数据库,并在应用适配3种数据库的连接方式和查询语言,同时还要求开发人员同时了解这3种数据库的开发技术,整个流程非常复杂,技术要求非常高。
此外,由于是3个独立的系统,数据很可能存在不一致,比如说消费记录更新到了关系型数据库,但是相应的评价没有更新到搜索引擎中,导致分析语句的结果不准确。
TDH统一架构跨模型联合分析方案
那有没有一种架构或者方案,不需要为不同的业务需求单独部署不同的产品,一套平台就可以全部搞定,实现不同模型数据的统一存储管理,同时也不需要根据不同的产品平台学习和使用不同的接口语言,一套语言就可以搞定呢?
答案是,有的。
下面我们来看看星环科技自主研发的基于多模型统一技术架构的大数据基础平台TDH是如何实现以上业务场景的(下图右侧)。

基于星环科技的多模型统一技术架构,用户只需用一句SQL就能同时访问这3种存储模型进行联合分析,替代了之前3段代码。一句SQL里,同时对图数据人群关系表,关系型数据消费记录表,全文数据商品评价表,3个表进行了跨模型关联,一次操作完成了之前三次操作才能完成的业务,大大简化了开发复杂度,简化用户操作。同时数据也仍保留在原存储引擎中,也不用对数据进行导入导出或者转换,不会存在数据不一致或数据冗余存储的问题。
TDH多模型统一架构
那TDH的多模型统一架构是什么样子呢?
TDH基于领先的多模型统一技术架构,提供统一的 SQL 接口、统一的计算引擎、统一的数据管理系统和统一的资源管理系统,通过9种独立的存储引擎,支持业界主流的10种存储模型:关系型数据存储、宽表存储、搜索引擎、地理空间 存储、图存储、键值存储、事件存储、时序存储、文本存储、对象存储。在一个数据库中实现多种数据模型(例如关系表、文本和图片)的统一存储管理,一个SQL就可以实现不同数据模型的操作和查询,模型转化流转以及跨模型关联分析,解决了不同模型数据之间的组合使用问题。
与CDH散装架构相比,TDH统一的多模型架构具有复杂度低、开发成本低、运维成本低、数据处理效率高等优点。

统一的接口
CDH不同组件使用不同SQL编译引擎,如HiveQL,SparkSQL,Impala SQL,Phoenix SQL等,SQL无统一规范,用户需要学习适配多个产品的不同接口,学习和开发成本高。缺少统一的访问接口,不同的大数据技术采用不同的API编程接口, 开发不同的数据模型效率低。
当有新业务需要新增模型时,需要单独部署新的独立产品组件,新的产品组件往往使用的是不同的接口和分布式数据管理系统,系统开发复杂度高,难度大,周期长。
此外,对ANSI SQL标准和传统关系型数据库方言支持度较低,企业业务迁移成本高。
Hive、SparkSQL、Impala、其他在Hadoop基础上的SQL引擎、NoSQL或者关系型数据库之上的实现存储过程语法非常有限。
TDH基于自研的统一的SQL编译器Transwarp Quark可以实现统一接口处理不同的业务和不同数据模型,只需要简单的SQL语句即可完成各种复合跨模型数据查询,无需访问不同接口即可操作不同的数据模型。对于新增场景、数据库切换而造成接口、开发语言切换的问题就不存在了,开发和迁移成本大大降低。
TDH通过统一SQL语言(而不是API编程接口)进行大数据应用开发,支持绝大部分ANSI 92、99、2003 SQL标准,降低了应用开发门槛。
同时还兼容传统关系型数据库方言,如Oracle、IBM DB2、Teradata,降低了用户从传统数据库的迁移成本,具备国产化替代的能力。此外,TDH提供存储过程支持,降低开发大型复杂数据业务系统的技术门槛。
统一的计算引擎
CDH使用一系列孤立的计算引擎,Flink比较适合实时数据分析,而Spark适合离线数据处理与分析。计算引擎Impala仅适合交互式查询分析等简单场景,批处理场景需要使用Hive/MapReduce,而传统的MapReduce计算引擎计算延迟长,不适合交互式分析场景和多轮迭代的复杂离线处理场景。企业内因为多种模型的数据处理需求,因此需要学习和使用多个计算引擎,因此学习成本高,运维的复杂度也比较高。
多种计算引擎的部署一般都缺少支持多租户的计算调度器,因为在支持不同优先级的任务上能力不足,需要依赖第三方调度技术。
此外,对图数据、时空数据等多模型数据的计算和分析能力,尤其是多种模型数据之间的交叉式分析,其计算引擎一般不支持或者支持得不够全面。
TDH采用自研统一计算引擎,可以根据不同的存储引擎自动匹配高性能算法,能够在不同的数据量级上(从GB到PB级别)提供优化的分析性能,支持广泛的大数据使用场景,支持实时和离线等复杂场景,可用于建设一站式数据服务,统一数据湖、数据仓库和数据集市等数据系统到一个平台上,不需要采用混合架构或多种计算引擎,降低了开发和运维难度。
统一的计算引擎能够处理不同模型的数据,无需采用混合多种数据库的技术架构,提升开发多模型应用的效率,降低不同模型间的开发难度和运维成本,提升运行性能。
统一的计算引擎可支持联邦计算,企业内部多种数据模型可与第三方数据库进行联合查询,消除数据孤岛。
此外,还支持多租户,统一规划计算资源、智能弹性调度不同计算模式并根据业务优先级灵活响应,可支持多种混合负载的复杂应用。
统一的存储管理
CDH 不同的数据模型有专有的分布式管理技术,数据的分片、复制,存取、一致性算法和故障恢复等方面都有完全不同的实现策略,各有优劣,没有统一的最优管理策略。用户需要理解不同模型的数据管理策略,应用开发和运维难度大。
TDH 基于统一通用的分布式存储管理系统技术,实现统一的元数据管理、事务管理和数据一致性管理,可以实现多种模型之间的数据一致性,同时还极大的降低了企业运维管理成本,避免数据孤岛。
统一的资源管理
CDH使用YARN做资源调度与管理,不能很好支持长生命周期的任务,比如企业需要 7*24小时运行的任务。其主要采用进程模式做资源分配,无法实现计算资源和内存资源在不同计算任务之间的隔离,也无法支持网络和存储资源的管理与调度。通过YARN做资源调度和管理,仅支持分布式计算框架的资源管理与调度,不支持有状态的分布式存储框架或通用应用的资源管理与调度。此外,不支持YRAN的产品组件需要使用自身的资源管理系统,如Impala,Elasticsearch等。
TDH基于容器的资源管理与调度技术,实现统一管理配置操作系统资源,具备更好的通用性,向上可以支持多种计算和存储框架,以及有状态/无状态应用。并且还具备更好的隔离能力,支持海量不同用户的各种应用独立运行,保证它们之间互不影响,部署扩容更加便捷。
性能提升
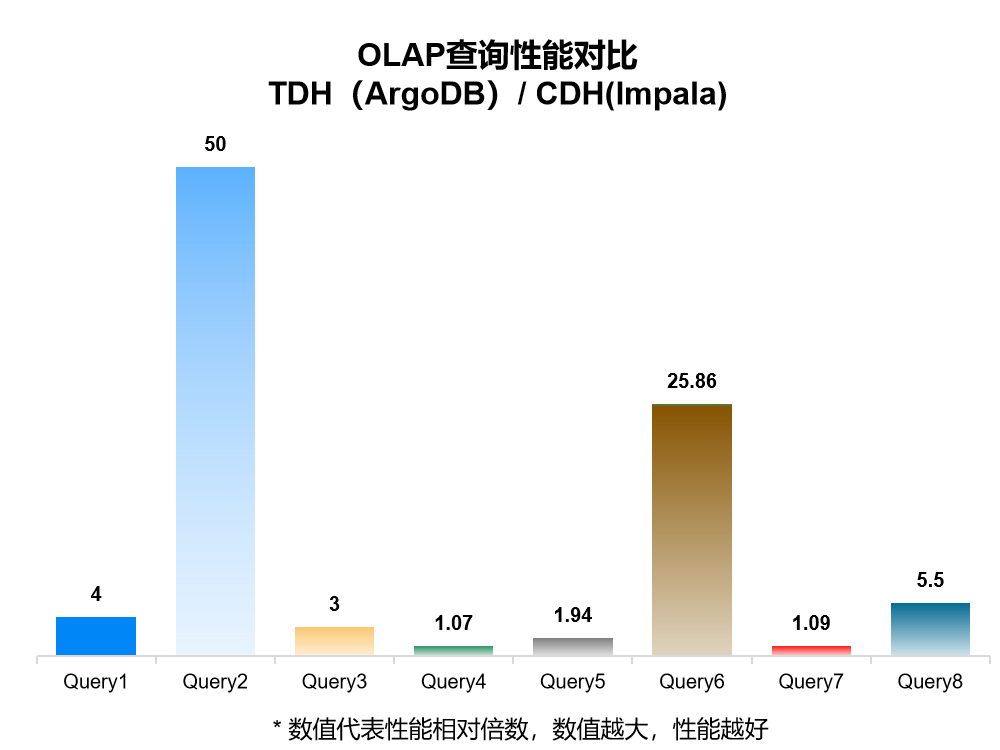
ArgoDB VS Impala
ArgoDB是星环科技自主研发的分布式分析型数据库,同等配置下,基于不同查询分析场景下,TDH(ArgoDB)在聚合统计、关联查询、精确查询类场景下是CDH(Impala)的2~50倍。
Inceptor VS Hive
Inceptor是星环科技自主研发的关系型分析引擎,基于TPCDS 1TB的数据规模,同等配置下(4X10cores),基于以下不同查询分析场景下,TDH(inceptor)性能是CDH(Hive on Tez)的7~25倍。

Slipstream VS Flink
Slipstream是星环科技自主研发的实时流计算引擎,在吞吐量性能方面,ETL测试项100万、500万数据量数据处理吞吐量,Slipstream比Flink性能分别提升25%和30%。Filter过滤场景100万、500万数据量Slipstream比Flink性能提升14%和6%。
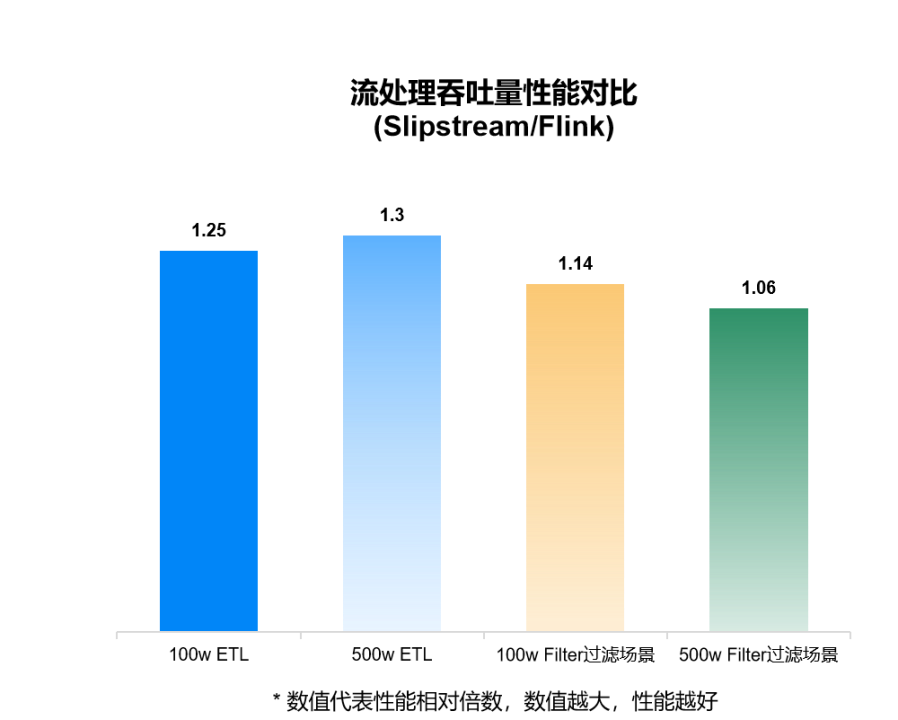
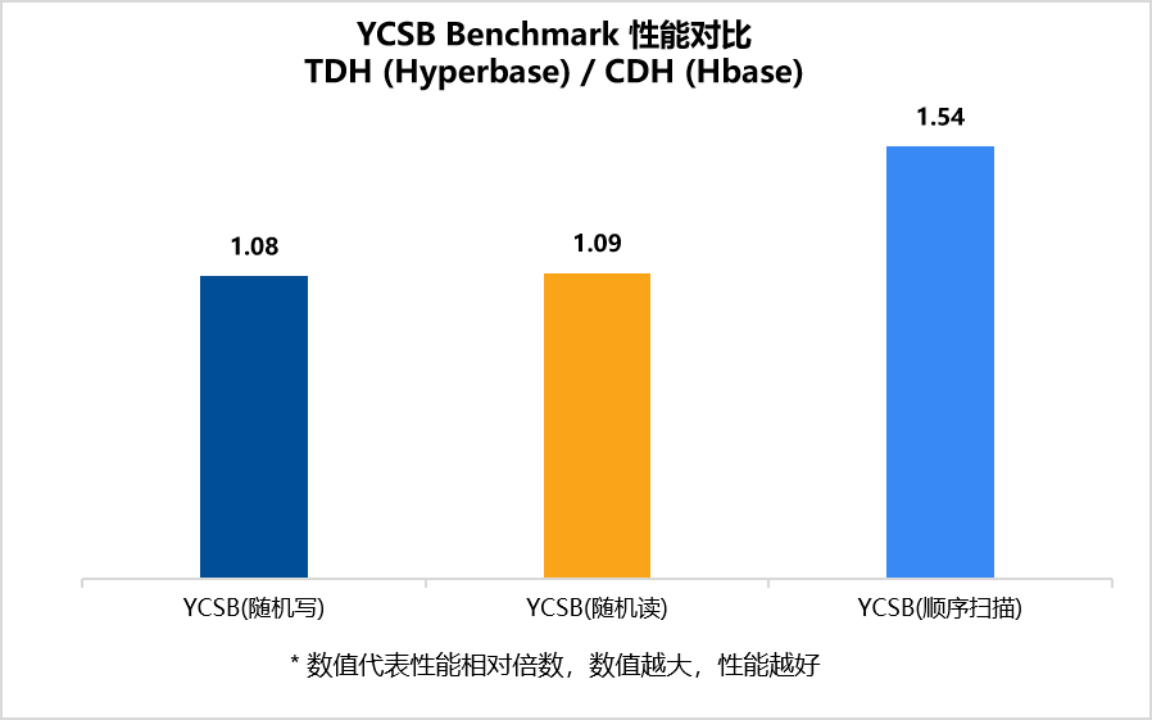
Hyperbase VS Hbase
HyperBase是星环科技的一款宽表数据库,使用统一的SQL接口,使用SQL bulkload批量数据入库和实时数据写入,支持二级索引和全文索引,并提供图形化灾备工具,在性能方面,基于1000W条的数据集,随机读写性能方面,TDH(Hyperbase)相较于CDH(Hbase)提升8%以上,顺序扫描性能提升54%。
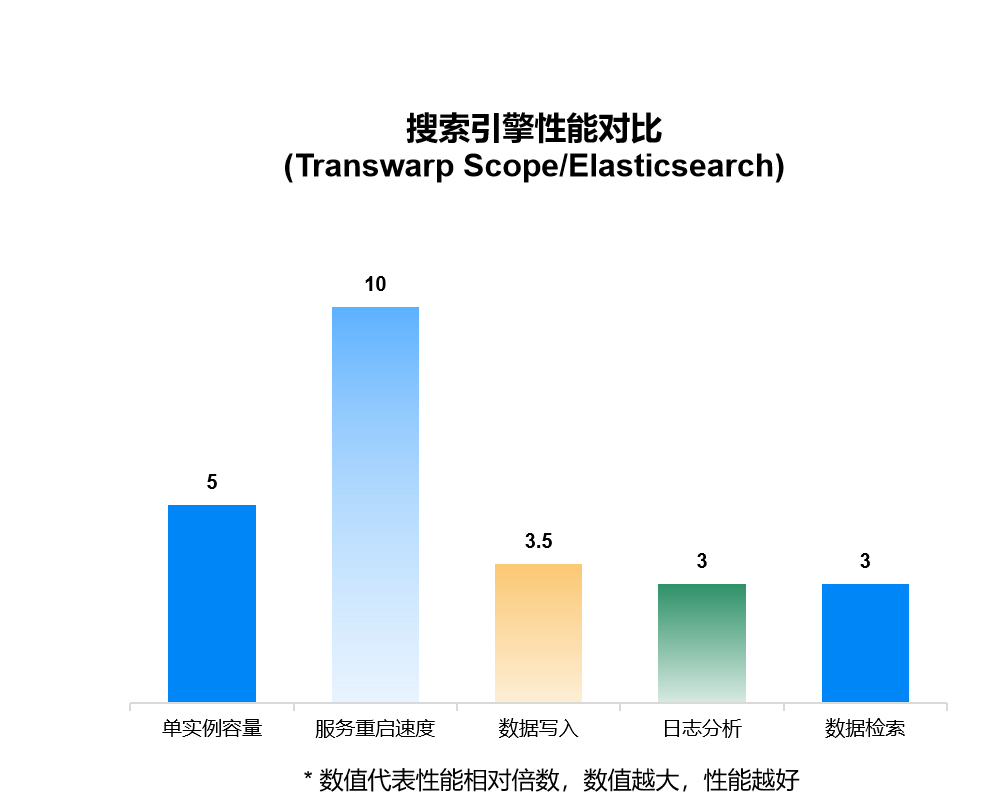
Scope VS Elasticsearch
Transwarp Scope是星环科技自主研发的分布式搜索引擎,提供PB级海量数据的交互式多维检索分析服务,单实例可突破至百TB的数据存储,是Elasticsearch的5倍以上,大大降低用户硬件成本。数据批量写入速度相对Elasticsearch提升40%。相对于Elasticsearch, Scope具有很强的容灾和数据恢复能力,重启恢复时间在TB级数据量下控制在分钟级,不到Elasticsearch的1/10。
多模型能力拓展
CDH的数据存储模型仅支持关系型、宽表、搜索引擎等数据模型,无法满足如图数据库、时序数据库等新场景业务需求。此外,新增组件需要增加额外的计算引擎,数据使用和数据处理割裂,架构设计、开发、运维复杂度高。
TDH 采用领先的多模型统一技术架构,通过9种独立的存储引擎,支持业界主流的10种存储模型:关系型数据存储、宽表存储、搜索引擎、地理空间 存储、图存储、键值存储、事件存储、时序存储、文本存储、对象存储。同时分布式数据管理系统的插件特性,也方便后续业务的灵活扩展,可以根据需要接入其他存储引擎。
使用CDH的用户,当因业务发展需要使用图数据,时序数据,时空数据等数据模型时,需要另外单独搭建数据库,比如开源图数据库Neo4j,开源时序数据库InfluxDB,开源时空数据库GeoMesa等,因此会进一步加剧散装架构带来架构复杂、开发和运维成本高等各种问题。同时,引入的单独开源数据库产品在架构、功能、性能、易用性等方面存在一定的局限性,无法满足国内用户海量数据存储计算以及复杂的业务需求,并且新增的数据模型一样难以实现跨模型关联分析。
图数据
CDH不支持图数据模型,用户可另外搭建如开源图数据库Neo4j来提供图计算和分析能力。Neo4j是集中式架构,扩展能力差,存储、计算能力和性能方面有限。在易用性方面,支持的数据源、可视化、运维管理方面均存储不足,无法满足用户多场景、高效图查询分析、便捷运维等要求。在集成Neo4j后,平台也不支持跨数据库查询,不支持异构模型数据关联查询。
TDH基于多模型统一架构,用户可灵活接入图数据库StellarDB。StellarDB具有原生分布式架构,存储和计算灵活扩展,轻松实现万亿级数据存储计算。StellarDB提供丰富的接口,支持更多的数据源,满足客户现场更多样、更复杂的业务场景。StellarDB提供2D和3D图和图算法可视化。在运维管理方面,StellarDB提供可视化的数据导入、集群监控、图查询任务和图计算任务监控等功能,进一步降低用户的运维门槛。性能方面,StellarDB数据批量导入速度约是Neo4j的2倍,常用算法是Neo4j的3-8倍,多跳查询是Neo4j的50倍以上。
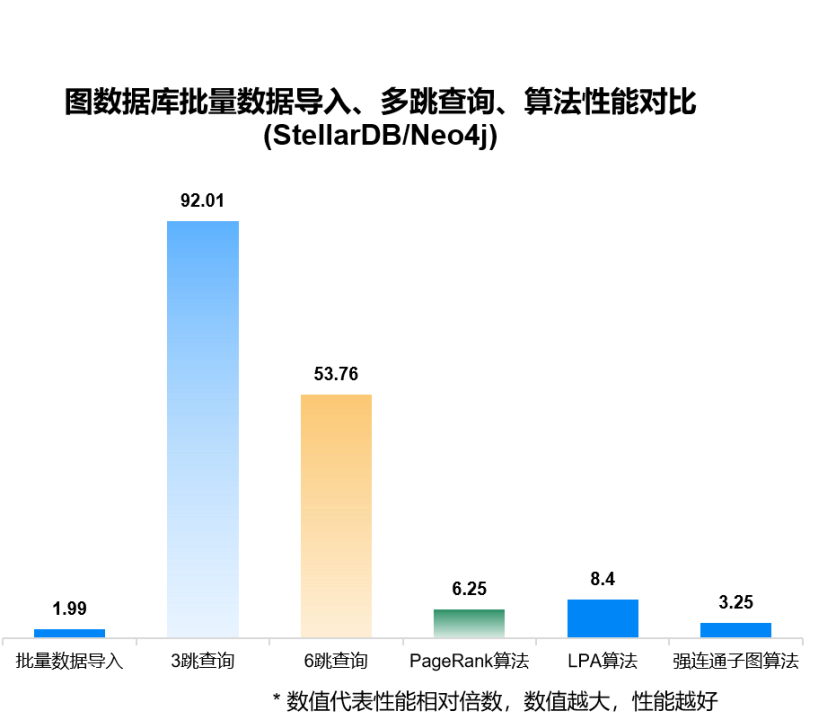
时序数据
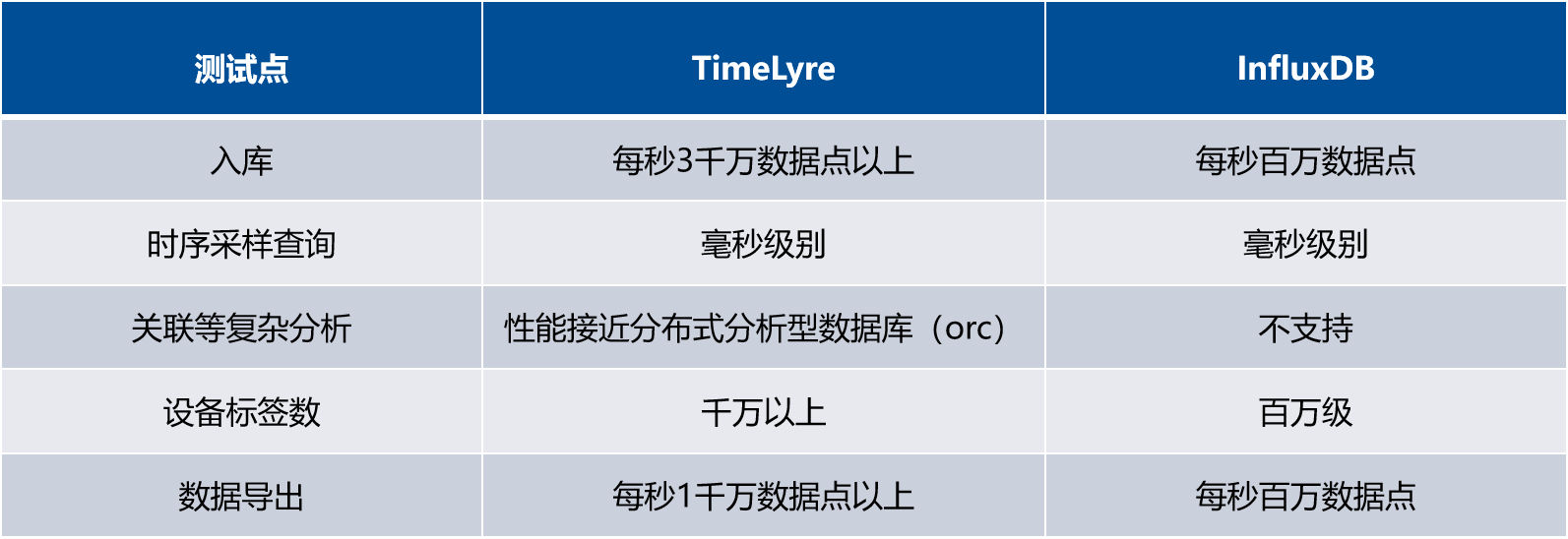
CDH不支持时序数据模型,用户可另外搭建如开源时序数据库InfluxDB来提供时序数据计算和分析能力。开源时序数据库InfluxDB采用单机部署,不支持分布式集群部署,存储和计算能力有限。使用InfluxQL作为查询语言,会带来较高的适配兼容门槛;不支持复杂分析,只能做简单点查或者指定设备分析。在大规模设备情况下,进程需要使用大量内存进行计算,服务的延迟波动较大,稳定性较差。
TDH基于多模型统一架构,用户可灵活接入的时序数据库Timelyre。Timelyre支持分布式水平扩展,同时具有极高的压缩率,可以支持海量时序数据的存储,提供高吞吐实时写入、时序精确查询、多维检索等功能。单节点情况下,数据导入速度、导出速度、支持的设备数量都是开源时序数据库InfluxDB的10倍,并且借助于分布式特性,理论上性能可以随着集群数据的扩展而线性提升。同时,Timelyre支持InfluxDB不支持的关联等复杂分析,性能接近分布式分析型数据库。
时空数据
CDH缺乏对于时间和空间数据的存储计算能力,用户可另外搭建如开源时空数据库GeoMesa或MobilitiyDB。但像GeoMesa和Mobility也只支持矢量数据存储,不支持对多维时空轨迹数据、栅格数据、瓦片数据的存储,时空数据索引和能力较弱,同时也缺乏对国内一些复杂场景如社会管理、态势分析等场景的支持。在标准支持方面,像GeoMesa不支持GeoSOT、北斗网格码等国家标准,无法使用GeoSOT及北斗网格对时空对象进行编码及管理。
TDH基于多模型统一架构,,用户可灵活接入时空数据库Spacture。Spacture支持大规模矢量数据、遥感影像数据、数字高程数据、时空轨迹数据的存储与计算,具有完备的数据查询、分析和挖掘能力,兼容PostgreSQL和GIS生态,可用于时空查询分析、时空模式挖掘、时空轨迹聚类等时空轨迹数据分析场景。
全套工具集
TDH提供SQL开发工具、轻量级ETL工具、数据调度工作流工具、图形化数据建模工具、交互式分析与Cube设计工具、元数据管理工具、可视化报表、大数据治理工具、灾备工具等大量易用性工具。

自主研发,国产软硬件兼容,满足信创要求
CDH完全是国外开源软件,不可控。Apache 软件基金会和GitHub官网都有公开说明,产品和技术受到美国的出口法律和法规限制。尽管此类软件的使用是免费的,但它的许可协议仍然存在诸多限制,包括禁止受制裁的国家使用原本对公众免费开放的代码。受美国出口管制的俄罗斯在近期俄乌事件中将这方面风险彻底暴露。
开源产品还可能会有license相关商业风险。如2021年初, Elastic公司决定将这款开源软件的 Apache License 2.0 变更为双授权许可,即Server Side Public License (SSPL) 和 Elastic License。其核心条款是“如果将程序的功能或修改后的版本作为服务提供给第三方,那么必须免费公开提供服务源代码”。这意味着不法分子可以获得其源代码并研究其漏洞,给企业用户带来巨大的安全风险。
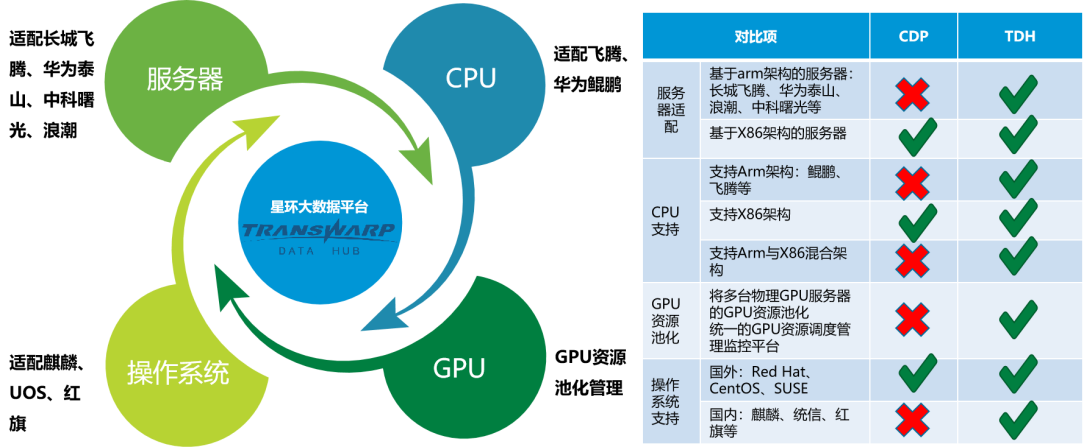
CDH在国产化服务器、CPU、GPU资源池化、操作系统等方面支持能力不足,无法很好地满足国产生态。
TDH是星环科技自主研发的国产大数据平台,通过工信部源代码扫描测试,1200万行代码里自研代码率超过70%以上,并且像分布式分析型数据库ArgoDB、分布式图数据库StellarDB等自研率都超过90%,在自主可控方面TDH有绝对优势。
此外, TDH已完成与主流信创生态厂商的适配互认工作,适配长城飞腾、华为泰山、浪潮等服务器,鲲鹏、飞腾CPU,麒麟、统信等OS,并有官方认证,支持基于ARM与X86服务器服务器混合部署并有大量落地案例,满足信创验收要求。

