B站运维数仓建设和数据治理实践
本文由ITPUB整理自哔哩哔哩SRE资深研发工程师袁帅在中国系统架构师大会(SACC2022)的演讲《B站运维数仓建设和数据治理实践》,内容将围绕B站运维数仓的建设,分别从引擎侧、平台侧和业务侧展开介绍,分享在落地实践中面临的挑战和问题。
随着B站业务的高速发展,公司内部业务、基础架构和运维对于通用运维性数据的多样性、实时性和集成性需求越来越多,对数据质量的要求越来越高。而伴随着大数据技术的不断发展和成熟,B站也对公司内部基础数据的治理和管控进行了大量尝试和实践,最终建设了一体化运维数仓,来支撑满足内部业务/基础架构/工程效率/SRE团队对于数据的强烈需求。

▲哔哩哔哩SRE资深研发工程师 袁帅
嘉宾介绍:2020年加入B站,先后从事过大数据运维平台,TIDB数据库管控平台,运维作业流引擎及服务树&CMDB等运维数据中台研发工作。个人擅长基础架构、Devops和SRE等领域架构设计和落地建设,目前专注于SRE体系下效能平台建设,致力于通过工程化和产品化来提升SRE和运维工作的整体效能。
B站SRE体系是如何构建元数据和使用
早在几年前,B站内各个平台基于对服务元信息统一管控的强烈诉求,诞生了一个新项目,它就是我们内部所称的服务树。服务树的主要功能是以服务的形式来提供周边平台的资源对接支撑。服务树是一个以应用为视角来组织服务的树形目录,基于这个目录来做资源的细分类和权限隔离。

事实上,服务对应着应用。服务树所做的事就是为应用分配全局唯一Appid,周边平台业务数据组织,聚合均已Appid标识。服务树具备实例管理功能,提供应用部署相关的元信息(比如,IP、机房、云厂商等)。
服务树具备节点角色管理功能,负责一些基于RBAC鉴权的场景。基于内部统一用户,托管各个系统角色用户管理功能,实现鉴权。从图上可以看得出来,服务树第一层是应用层,第二层是实例层,第三层是人员和角色层。
周边平台像资产管理系统、Discovery、跳板机、容器平台、CICD、日志、Moni监控、Trace等,都是以服务树为支撑来进行数据的整合。
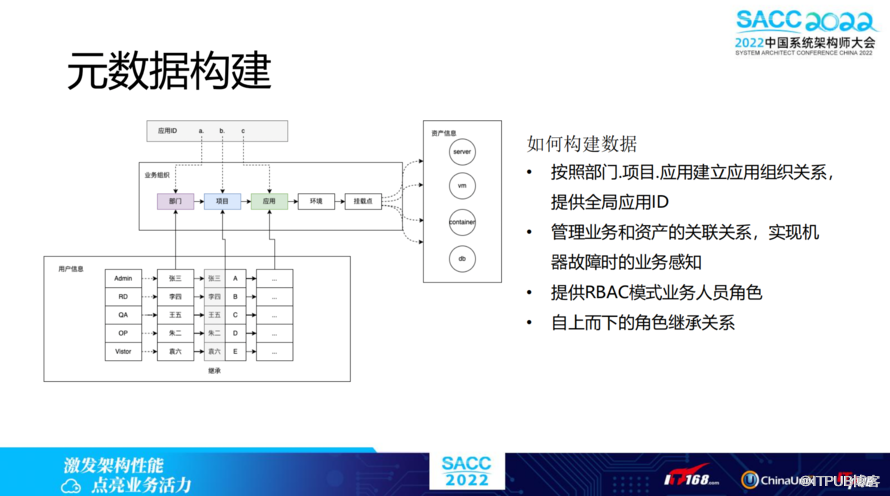
如何构建应用的元数据?主要采用三段式来进行构建,按照部门、项目、应用建立应用组织关系,提供全局应用ID。
那么,如何产生管理业务和资产的关联关系?图中有提到,在应用的视角出发,会有环境和挂载点,可以区分机器的环境,挂载server、vm、container、db等资产信息,从而实现机器故障时的业务感知。
此外,元数据提供RBAC模式业务角色,提供Admin、RD、QA、OP、Vistor默认的五种角色,也就是在部门、项目、应用这三层节点上,绑定用户和角色的信息,由于节点之间存在自上而下的继承,所以权限也是往下继承的。
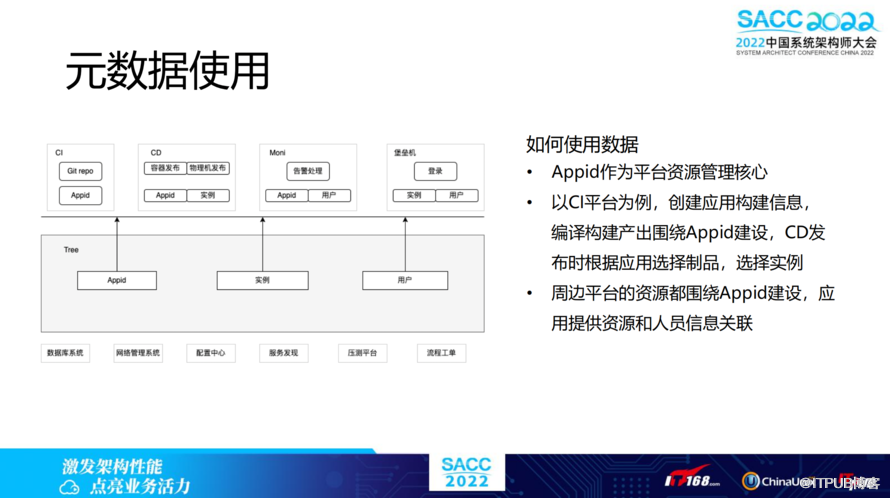
如何使用元数据?Appid作为平台资源管理核心。以CI平台为例,如果以APP视角来构建,就需要APP与Git repo、镜像进行关联,通过编译镜像来构建它的编译产物。
在CD平台,无论是容器发布,还是物理机发布,都是根据应用选择制品,选择实例。周边平台的资源都围绕Appid建设,应用提供资源和人员信息关联。
一步步,服务树沦为一个毫无边界的数据中心
事实上,服务树是围绕人事物产生的元数据中心,伴随着长期数据注入,却没有一个简单治理的过程,服务树就一步步沦为一个毫无边界的数据中心。服务树具备的四大核心问题:
数据治理不足,灵活性不足。数据直接关联关系缺失,围绕应用做的资产关系缺乏统一的规范注册上报,上报的逻辑不能很好的支持配置项的自定义和扩展,导致接入新资源时缓慢,不具备持续治理的能力。
权限管控不足。RBAC场景无法满足细粒度、精细化的权限管控。直接或间接导致周边平台乱用服务树角色,导致角色人员混乱,无法治理。
自动化能力缺失。传统的资源,自动化能力严重不足,很多物理机、云主机销毁后无法感知,导致数据准确性降低。对于容器类信息,同样面临该问题。
消费场景考虑欠缺。围绕应用建设的运维数仓,本身从设计上没有考虑应用变动所带来的消费场景,周边平台对接完,发现应用改动后,缺乏感知。
对于API的暴露来说,有个很明显的问题,在前期缺乏设计的情况下,OpenAPI会出现混乱。主要体现在四方面:缺乏规范和制度,快速迭代,快速满足需求;平台调用方缺乏治理和维护;接口替换代码不处理,接口文档长期不维护;消费场景太多,平台定制接口太多,很多功能可以复用接口。
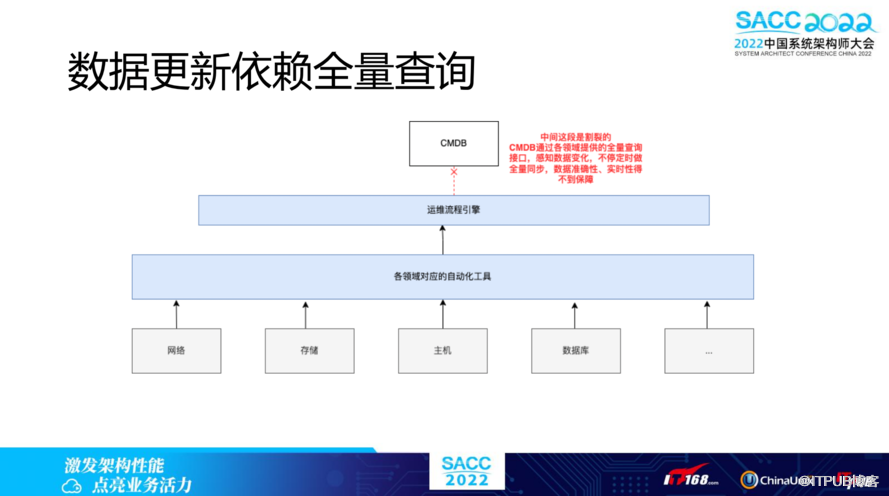
数据更新依赖没有合理的消费场景,是通过全量查询来闭环所有操作。举例来讲,
服务CMDB和资产CMDB之间是割裂的,CMDB通过各领域提供的全量查询接口来感知数据变化,不停定时做全量同步,数据准确性、实时性得不到保障。
如果每次都是全量查询,在数据库层面是一个比较大的性能损耗。
此外,非标的使用方式太多,总共有六大块应用的非标使用:应用作为其他平台的资源概念出现,实现权限管控;应用存在多个唯一ID;应用组概念强行套用;没有使用应用,而使用部门和项目,导致部门,项目变动,部门组织调整出错;应用下的环境和挂载点使用非标;应用作为集群,组件出现。

无法为应用进行画像。目前核心的问题在于应用缺乏应用资源注册,应用上下游依赖关系没有梳理,导致在水平层面或垂直层面缺乏围绕应用构建拓扑的能力。
针对上述痛点,SRE团队做过一些努力,但治理数据却无从下手。因为最小权限安全控制原则,服务树权限申请审批没有限制导致人员、权限信息混乱,导致应用无法迁移,应用无法交接,应用下所使用的资源,无法做关联,覆盖不全。
B站运维数仓建设的整体思路
B站建设运维数仓的目标和准则是什么?围绕应用来建设CMDB,大概有以下几点:以应用为中心,提供统一的元数据管理中心;CMDB建设的核心诉求就是做好应用的全生命周期管理;资源为辅,构建应用与资源的关联和拓扑;CMDB核心消费场景就是持续的交付,CMDB是一个持续迭代的过程;
按照场景和能力拆分基础资源CMDB和应用维度的CMDB,本质上应用也是资源;资源的注册和消费需要闭环;数据质量的保障:“自动发现,标准流程,人工维护”;边界,边界,边界,有哪些是我们坚决不会做的事情。
元数据中心作为SRE体系中核心的服务存在,元数据中心的数据来自CMDB,支持基础架构服务平台运转;元数据中心为端到端的服务运行时的过程提供数据支撑。

如图所示,元数据中心在基础架构SRE体系最上层。下层会有配置管理数据库CMDB,基础配置信息(人员组织、角色权限、流程管控),Adapter(数据管理工具、Plugin、OpenAPI)。底层会有资产采购、LDAP/AD、第三方系统、数仓平台、DB、Cache等。
往上看,元数据中心是为基础架构的所有平台进行服务,包括:事件运营平台、作业平台、流程平台、微服务平台、可观测平台、CICD平台、中间件平台、容量平台、多活平台等。最终,这些平台会形成统一的门户入口,给到研发部门使用。
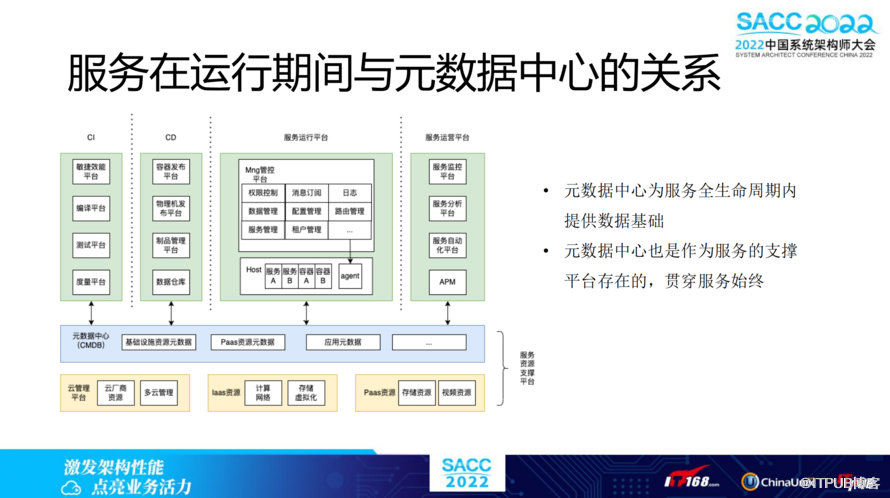
服务在运行期间,如何与元数据中心产生关系?元数据中心为服务全生命周期内提供数据基础,元数据中心也是作为服务的支撑平台存在的,贯穿服务始终。服务资源支撑平台有云管理平台、Iaas资源,以及Paas资源,这些统一的资产CMDB数据汇聚到每个数据中心,向上提供服务。
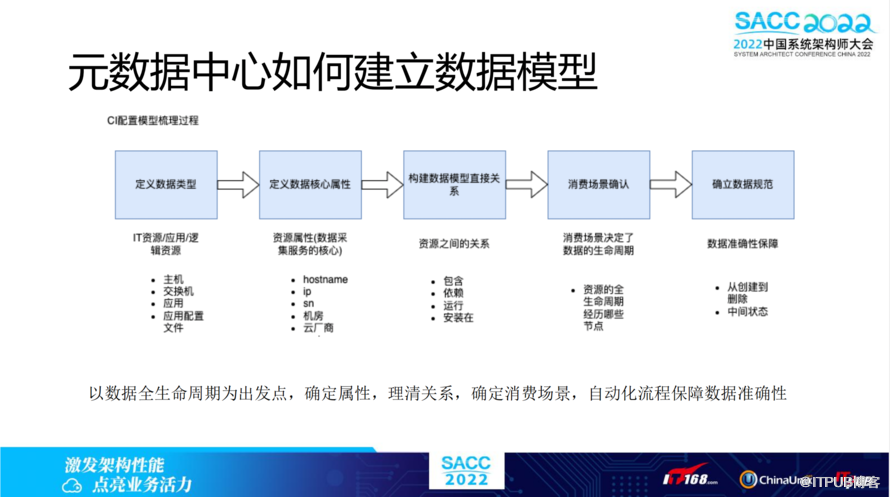
元数据中心如何建立数据模型?CI配置模型梳理过程有五个核心步骤:定义数据类型、定义数据核心属性、构建数据模型直接关系、消费场景确认、确立数据规范。总结来看,以数据全生命周期为出发点,确定属性,理清关系,确定消费场景,自动化流程来保障数据准确性,让我们建立一个规范的数据模型。
举例来看,应用数据模型的创建。创建思路基本按照流程一步步细分,自定义一个数据模型,需要产品、研发一起界定数据规范,需要各方遵守。
应用属性包括,应用名称/别名、应用等级、应用唯一ID(Appid)、组织/业务、extra。数据模型关系包括,所属组织/业务、人员/角色、所使用IT资源、依赖的微服务组件、依赖的中间件、extra。
消费场景确认围绕几点,分别是应用创建(平台创建申请)、应用更新(更新等级、名称、别名、数据关系变更)、应用删除(废弃应用)。数据规范包括,明确应用的创建入口,明确应用元信息变更后,周边平台的消费感知。

上图是元数据中心产品架构,从上到下分别是Apiserver层、Mng(管控平台层)、资源采集层、资源对象层。具体而言,所有人都是通过Apiserver来访问元数据中心。
Mng(管控平台层)包括模型管理、拓扑关系管理、事件处理、权限管理。资源采集层包括Agent采集、SDK上报、定时任务采集、数据校验采集规则配置下发。资源对象有应用、公/私有云、网络、服务器、机房、交换机等。

上图是元数据中心技术架构,分为接入层、服务层、存储层、三方服务、运营分析五大块。接入层可以用http和grpc来调用。服务层分为功能层和资源层。存储层包括Mysql、Redis、内部KV存储。三方服务包括统一认证、流程Flow。通过ES、Clickhouse、neo4j来做运营分析。
元数据中心数据采集的核心就是Data-Collector数据采集模块是如何设计?其中包括数据源(Origin)、DataCollection集群、数据存储三部分。其中,数据源(Origin)是指采集的数据节点采集器会将数据发送到指定的内部消息队列里,DataCollection订阅指定Topics接收采集数据。
DataCollection集群是指分布式,连接Topics消费数据。数据存储是指数据经DataCollection处理,最终落在Mysql、Redis和内部KV存储上。
如何处理原始数据关联关系?把CI和CI之间的关系种类列出来,前提需要产品、业务方进行充分沟通。当我们列出关联关系之后,需要进行确认。
以应用为例,应用运行在物理主机上,应用的DB安装在服务器上,服务器链接网络交换机,机柜支撑物理设备。按照梳理的关系分析,整理出节点类型和边类型,最后定义出以应用视角的图模型。

上图是B站元数据中心落地实施流程,拥有现状评估、项目启动、数据实例化、数据校验、数据场景消费五个核心点。在项目启动过程,B站会开设项目启动会,会上介绍整体的建设思路、核心概念、核心指标等,确立CI模型和关系整理。在数据校验过程,需要校验数据导入情况,确认数据准确性,为生产环境做准备。
关注数据质量
在落地之后,我们要持续关注数据质量。制度规范分为规范要求、流程要求、组织要求、平台要求四部分。
规范要求是明确定义CMDB平台的作用,以及与其它业务系统间的关系;明确定义资源的管理过程以及责任人和责任平台;明确定义资源的基线标准以及偏差管理办法;从服务业务场景的视角来规划和建设配置管理能力。
流程要求是能够真是反映资源状况;能够完整的包含所有的资源信息以及资源间关系;全局唯一的权威数据源;数据能够被用户及系统方便,及时和高效的获取。
组织要求是成立统一的配置管理能力建设主体;各个业务团队明确配置消费和完善的责任;形成配置管理讨论、优化和需求收集的机制。
平台要求要做到以下几点:逐步实现配置自动发现,自动维护;实时跟踪资源的状态及配置变化;模型灵活,能够根据业务需求实时扩展和调整;配置可视化,能够支持资源问题的分析和快速定位。
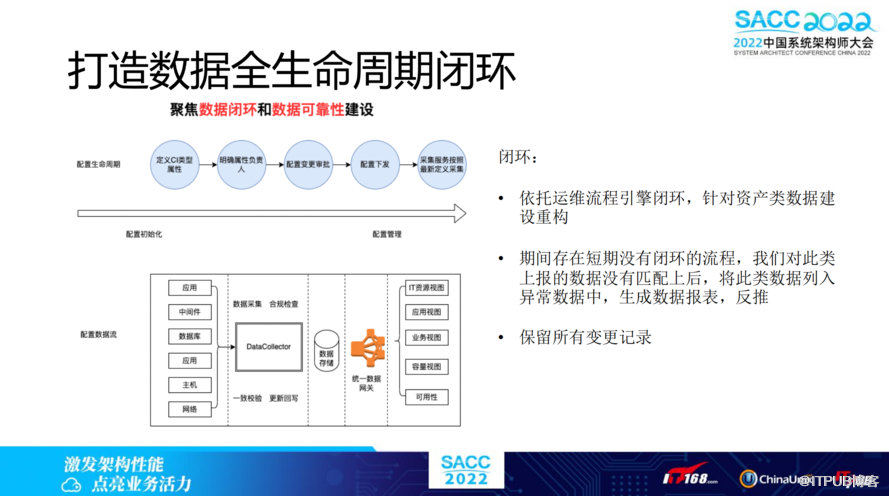
打造数据全生命周期闭环,聚焦数据闭环和数据可靠性建设。依托运维流程引擎闭环,针对资产类数据建设重构。期间存在短期没有闭环的流程,B站对此类上报的数据没有匹配上后,将此类数据列入异常数据中,生成数据报表,并且保留所有变更记录。
数据治理是一个持续的运营和改进的过程。部门导向,信息分散、孤立、管理无规范。不论是否有CMDB系统,实际都存在CMDB需求,以部门为单元维护配置信息。
数据导向,共享型CMDB,参考业界标准数据模型。构建共享型CMDB,将各部门都关心的数据及相互关系统一纳入CMDB管理,并建立配置管理流程制度。由于消费场景不明确,造成消费价值与生产成本的失衡。
场景导向,面向特定使用场景,如资产管理,流程关联。局部数据标准化程度,准确性较高。由于使用场景单一,总体消费价值不高,生产成本相对较高。
服务导向,整合型CMDB,整合更多的管理对象,对外提供数据服务。使用场景全面,提供数据供给服务,支撑日常操作管控,如自动化,监控,作业流管理,运维分析等。引入多样化的数据生产手段,逐步平衡消费价值与生产成本。
价值导向,面向业务,支撑业务发展。CMDB全面支撑服务及业务发展,如服务容量管理,可用性管理,成为IT运维的基石。配置管理主动推动组织IT管理水平的提升。
总结
无论我们身处CMDB建设的哪个环节,最终都是要面向价值保障。我们可以按照不同阶段进行整合,快速迭代,完成CMDB在业务方面的一些价值。

