昨天在南京搞了一场分布式数据库运维与优化的沙龙,对于分布式数据库的运维,我遇到过一个朋友,他说他们现在很头痛。分布式数据库是小问题不需要运维,大问题运维人员搞不定。搞得他请外包DBA觉得不划算,不请又心里不踏实,用原厂又用不起。目前的情况是有不少企业已经开始使用分布式数据库了,也还有些企业在观望,不太敢马上入坑。他们担心的问题主要还是运维的问题。运维领域有句名言“运维最大的困难是未知”。

这句话包含了多个层面的含义:对数据库运行状态的未知;对技术的未知;对可能遇到的问题的未知,这些未知汇聚起来就是恐惧。当年我们从foxpro转向大型数据库,转向Oracle的时候,也遇到过这样的时期,那时候出过几次大问题并且搞不定后,很多企业都有过想回到简单的不需要运维的foxpro。与我们熟知的集中式数据库相比,分布式数据库就像一只巨大的史前生物一样,神秘、未知、令人恐惧。
用过分布式数据库的朋友都知道,分布式数据库从组成结构上来说,更加复杂。甚至有些国产分布式数据库是由几十个不同的开源组件组合而成的。仅仅安装部署,我们就需要学习ETCD、ZOOKEEPER、KAFKA、Mysql、Myproxy、普罗米修斯等大型开源组件后才能完成。不过也有些朋友说分布式数据库运维其实没那么复杂,大部分的运行中遇到的软硬件故障,分布式数据库都会自动处置,不需要运维人员干预。
说句实在话,有一种说法。分布式数据库出小问题的时候比较容易处理,数据库本身的高可用就能自动规避一些小问题,不过分布式数据库最怕出大问题,最怕出了问题不知道如何处置。
在分布式数据库中最怕遇到的是两个事情,一个是后台自动任务没在维护窗口跑完,又不敢轻易停止。另外一个就是一个大查询好像总是跑不完,又不敢干掉重来。遇到这种事情我们是无能为力的,既不能杀掉会话,又不敢重启数据库,以往在运维集中式数据库中的利器似乎都不灵了。
在这种情况下,未知带来的恐惧是运维中最大的问题,因为恐惧而采取错误的处置措施,从而导致灾难性的后果,是运维中最不能承受的。所以说,我们需要更深入的去理解分布式数据库产品,去探讨分布式数据库产品运维的一些新的思路。既然未知是最大的困难,那么变未知为可知,甚至已知,是解决分布式数据库运维中的十分重要的措施。我们看到现在很多国产分布式数据库已经开始重视其可观测性的问题,不仅提供大量的运行指标,等待事件,也开始提供一些ASH,SQL执行状态的全面跟踪等接口都在不断的完善中。
虽然数据库提供了一些可观测性接口,但是我们如果不懂如何去使用它也是白搭。因此我们需要构建分布式数据库的可观测性接口的采集、分析能力。与集中式数据库不同,分布式数据库是多节点、多分区、多租户的,计算节点和存储节点都是分布式的。其指标体系十分复杂。比如一个简单的参数“IO读取队列延时”,就是关于数据库读磁盘时的AIO队列延时。

在分布式数据库中,这个指标有明细的清单,比如在每个服务,每个租户上都有一个指标。我们来分析这些指标的时候,直接用明细指标不太方便,我们还需要构建一组统计数据,比如最大值,最小值,标准差,平均值等。在分析的时候,也需要通过这些统计数据来进行分析,不能仅仅分析原始数据。这样就会导致原本就十分复杂的指标体系,变得更加复杂,更加难以人工监控了。因此对于分布式数据库的运维监控,必须构建自动化的体系,否则哪怕是专家,遇到一些他们没有见到过的问题,也很难完成快速分析与问题定位。
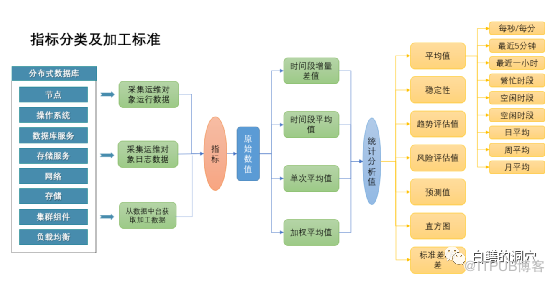
在分布式数据库的监控指标体系构建是十分复杂的,如上图是一个分布式思考指标体系构成的示意图。只有完成这样的指标体系,分布式数据库的健康管理才能进行。光有原始指标是不够的,我们必须理解指标背后的含义。因此我们需要构建分布式数据库指标体系的知识图谱。
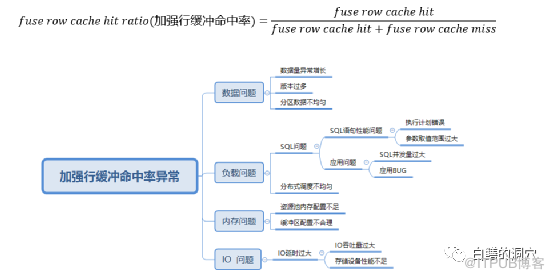
比如上面的加强缓冲命中率指标关联的问题就涉及到很多个方面。在构建知识图谱的时候,主因次因,直接关系,间接关系都要考虑到。这样在问题分析的时候,才能发现更多的衍生路径。这些知识的来源主要是原厂的文档、专家的运维知识、运维案例、甚至是开源数据库的源代码。因为目前我们的国产数据库的资料与运维案例相对匮乏,因此积累运维经验并不容易。但是这项工作必须开展起来,否则当国产数据库大规模应用的时候就抓瞎了。
最后我分享几点分布式数据库运维中的常见问题,首先是分布式数据库本身的高可用架构会屏蔽一定的故障。因此对于分布式数据库来说,某个组件的故障是最容易处置的。隔离故障硬件,修复后再加入集群就可以了。最怕的是硬件不稳定,时好时坏。比如某个网络接口一会儿UP,一会儿宕,并且是不是丢包。这种情况很可能引发分布式数据库的严重故障。不过如果能够尽早发现这个问题,并且尽快手工停掉这个网络端口,对数据库的影响就很小了。硬盘故障也是如此,特别是多路径故障,很容易形成时好时坏的局面,这时候IO读写变得十分不稳定,这个节点就会变得不稳定,从而可能引发整个数据库的问题。
对于硬件故障来说,网络故障对分布式数据库的影响是全方位的,偶发的网络延时增大,网络丢包等,可能会导致分布式数据库性能抖动甚至引发主从副本误切换,从而引发更大的故障。确保分布式数据库的网络带宽与网络延时在一个合理的范围内并且网络带宽不出现瓶颈十分关键。
集群数据分布不均衡和负载分布不均衡也可能会导致分布式数据库的严重故障,当某个节点出现资源瓶颈时,这个影响可能会引发大型故障。因此对节点资源的监控,一旦发现较长时间出现某些节点资源瓶颈,则需要尽快排查,避免引发大故障。
分布式数据库的慢SQL分析也是十分关键的,发现慢SQL,读懂分布式执行计划,发现执行计划中存在的问题,是分布式数据库运维DBA日常经常要干的事情。如果发现某个节点上的并行执行比较慢,那么就需要对某个节点进行分析,排除隐患了。
分布式数据库的运维,对于企业和DBA来说,都是处于刚刚起步的阶段,相关的运维知识、故障案例、专家经验都比较匮乏。数据库厂商也有义务梳理整理这方面的资料,并在自己的管网上发布,以便于大家遇到运维问题的时候,有个可参考的依据。我们也希望一些使用同种数据库产品的企业,也能建立起一个朋友圈,共同分享这方面的经验,尽快渡过这个运维知识与能力的空窗期。

