解读《2022 分布式数据库发展趋势研究报告》
分布式数据库近年来广受关注,目前,对分布式数据库的讨论,已经从什么是分布式数据库,为什么要用分布式数据库,转变为怎样规划应用分布式数据库。但分布式数据库有3条不同的技术路线,这无疑增加了选型难度,到底该怎么选?怎样选才能既满足企业未来五到十年业务发展需要,同时,所选数据库产品又符合产业发展趋势?
继Gartner点名原生分布式数据库之后,近日,由国家工业信息安全发展研究中心、中国电子学会、北京国家金融科技认证中心联合研究编制的《分布式数据库发展趋势研究报告》发布,该报告再次点名原生分布式数据库,指出原生分布式数据库是未来数据处理的发展趋势。
过去一年,我写的文章中,有很大部分与分布式数据库相关,比如:《话题探讨:GitHub不用分布式,能说明什么?》,《用分布式数据库后性能提高50%,为何还是放弃了?》《开源数据库虽香,但需警惕风险勿沦为“韭菜”》等等,有文章提到一些分布式数据库实践失败的案例,让一些人误认为我在唱衰分布式数据库。
其实不然,正好相反,我认为,中国数据库的机会在于“换道超车”而非“弯道超车”,分布式数据库就属于“换道超车”。所以,分布式数据库有着巨大的空间和无限的可能,而在多种分布式数据库技术路线中,原生分布式数据库更被看好,多份报告已经很说明问题,这是由底层结构决定的。
但作为一个新物种,原生分布式数据库产品成熟度还需要时间来锤炼,生态也需要完善。所以,有问题并不可怕,关键在于能不能不断的去解决问题。
为什么说分布式数据库是大势所趋
分布式是全球趋势而非中国特色,相比国外,国内的分布式更广泛,本质还是因为中国庞大的人口基数与人口密度、以及高度发展的经济。在数字化转型过程中,云计算、5G、IOT、人工智能、区块链等新兴技术的发展,带来了产品和应用在各行各业的不断更新和落地,随之而来的是数据量呈现几何级增长、数据结构复杂度与日攀升。
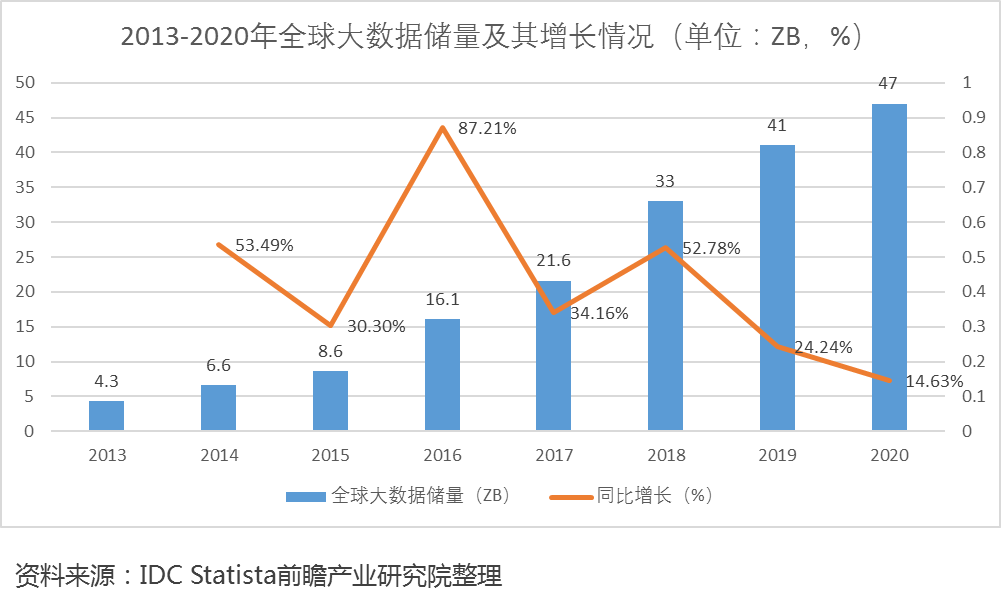
报告指出,从需求面看,随着数据量爆发增长,传统数据库面临挑战:
首先,是传统数据库遇到的性能瓶颈。
快速发展更新的业务驱动着数据规模无限增长,传统集中式数据库面对数据量的增长时难以维持性能,然而分布式数据库的性能可以水平扩展。
例如:二十年前,某电信运营商的业务以2G为主,业务比较单一,数据库仓库容量仅有10TB,分析形式以报告为主,引入4G后,业务范围扩展了很多,比如政企对公业务、视频内容业务、公有云业务、物联网业务等,数据容量已经超过800PB,因此,对数据库提出迫切的扩展性要求。
其次,是传统数据库面临分析能力的缺失
数据量爆发增长一定会带来数据分析需求的增长。
企业级应用的业务场景通常可以分为联机交易(OLTP)和实时分析(OLAP)两种,目前,多数企业使用两套系统分别支撑交易系统和分析系统,不仅造成了大量的数据冗余,同时增加了系统的复杂度和运维难度。
而分布式数据库的混合负载能力可大幅度提升分析时效性,并减少数据冗余,灵活性大大提高;
最后,是传统数据库的成本颇为高昂。
集中式数据库系统水平扩展难,需要按最大容量设计,可靠性需要付出高额的成本,反观分布式数据库,其架构支持灵活扩展,并可实现低成本的高可用解决方案。
从政策面看,当前,国家已出台多项政策扶持数据库行业的发展,并且信创政策也已经上升到国家战略层面,近三年部分相关政策见下图,其中不少政策都明确重点布局针对数据库分布式转型、应用创新战略。
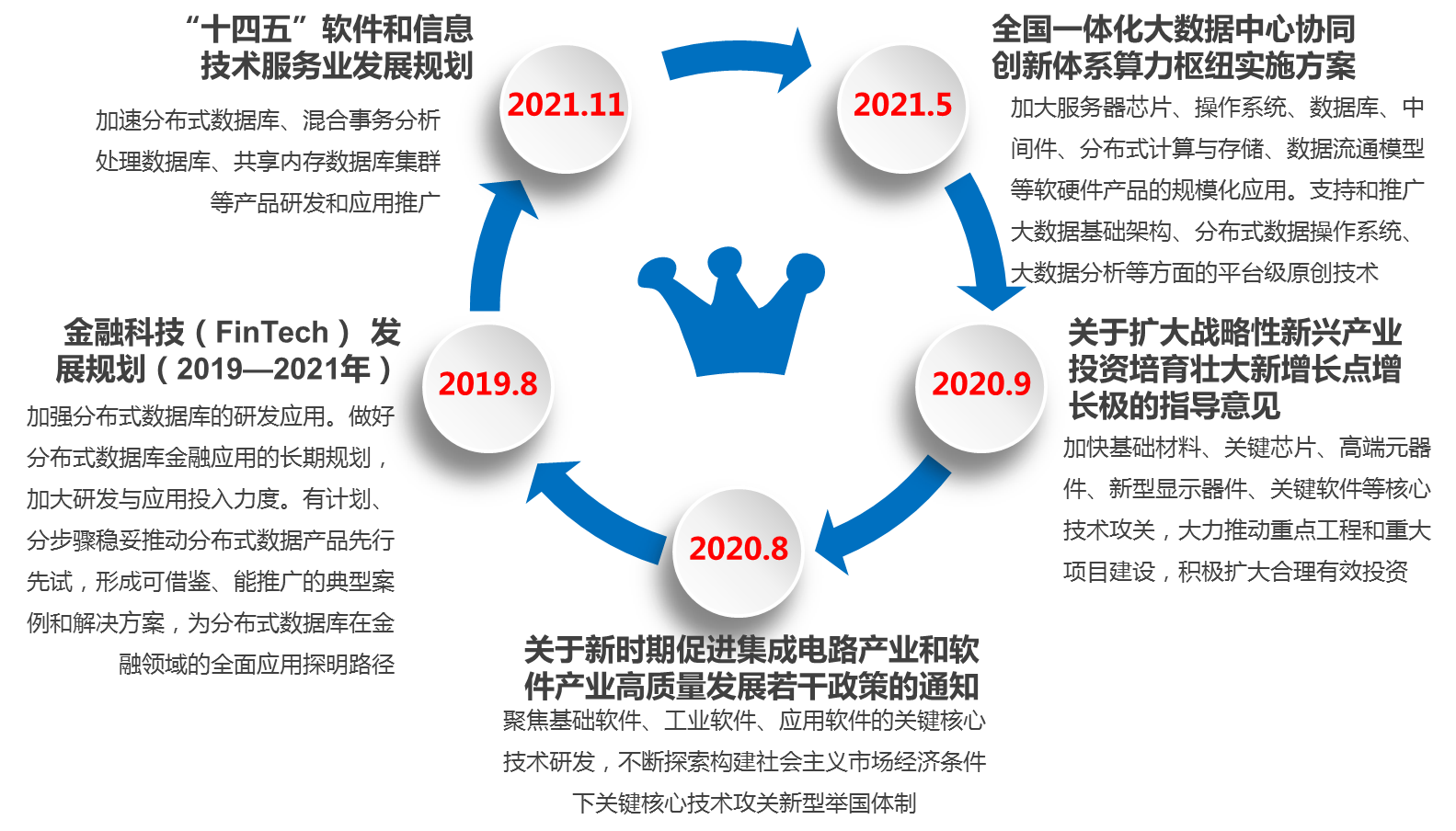
图片来源:《分布式数据库发展趋势研究报告》
例如:2019年中国人民银行印发《金融科技(FinTech)发展规划(2019-2021 年)》(银发〔2019〕209 号)金融科技发展三年规划中,就明确提到的“加强分布式数据库研发应用”的要求。
2021年11月30日,工业和信息化部发布的《“十四五”软件和信息技术服务业发展规划》,其中聚力攻坚基础软件部分,也明确提到了加速分布式数据库、混合事务分析处理数据库、共享内存数据库集群等产品研发和应用推广。
多项政策都明确提到了分布式数据库研发应用,为什么?因为“沿着同样的路线再造一个Oracle根本不可能,也没有意义”是国内数据库从业者的共识,分布式数据库被认为是国产数据库“换道超车”的唯一机会。
更明确的说,针对国内数据库存量市场,分布式数据库正在成为核心系统升级的首选。
从市场面看,借助政策红利,国产数据库的应用越来越广泛,主要体现在党政、金融、电信、交通等行业领域;
从技术层面,国产数据库技术也处于加速提升的关键阶段,各方面能力突飞猛进,在与国外高端数据库技术的抗衡中逐渐不落下风。例如:OceanBase打破了Oracle保持九年之久的TPC-C基准测试世界纪录,哪怕是九年前的纪录,从技术上说,这依然是巨大突破,因为,这并不容易,并不是随随便便就能刷出来的,否则,这纪录也不会9年无人打破。
因此,多重因素驱动下,分布式数据库是大势所趋是明确的。
为什么说原生是未来主流选择?
分布式数据库与单机数据库的不同在于其可以将核心功能,即查询、事务管理、存储等扩展到多台节点,甚至多个地域。目前,从实现方式上看,分布式数据库主要有3种不同的技术路线:
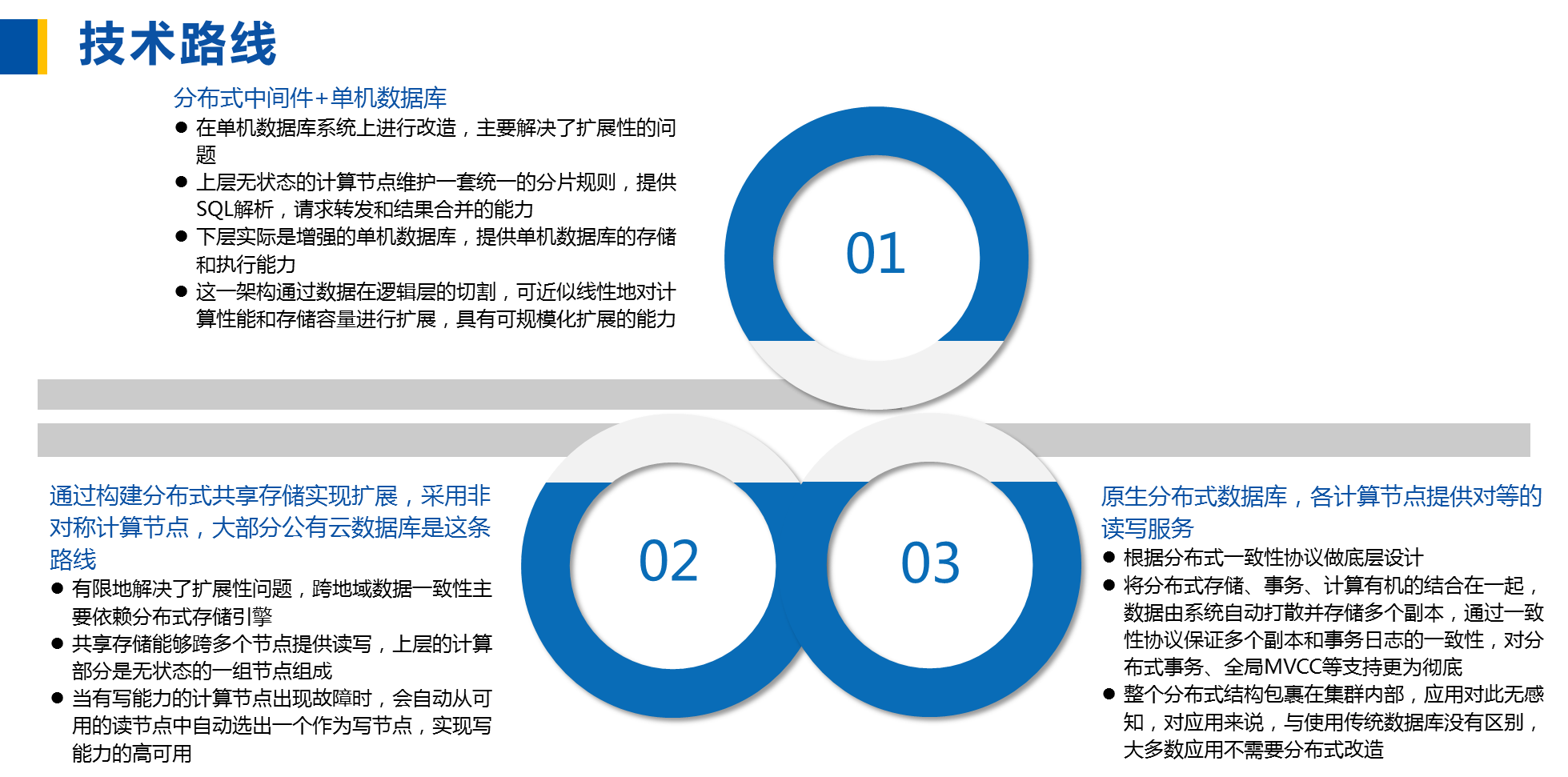
图片及代表产品来源:《分布式数据库发展趋势研究报告》
1、 分布式中间件+单机数据库
2、 通过分布式共享存储实现扩展,采用非对称计算节点(大部分公有云数据库都属此类)
3、 原生分布式数据库
先来看分布式中间件+单机数据库技术路线:
代表产品:TDSQL、GoldenDB、PolarDB-X等;
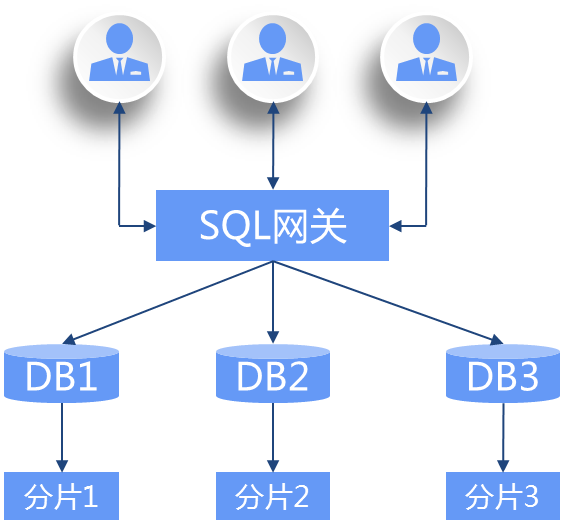
图片来源:《分布式数据库发展趋势研究报告》
这种路线在单机数据库系统上进行改造,主要解决了扩展性的问题,但能力受到单机数据库自身制约,有天花板。
优势:兼容性好,学习成本低;从原理上说,如果有足够的资源投入,比如:硬件资源、开发运维人员等,节点的扩展可以做到很大规模。
劣势:业务代码修改成本高;下层计算节点无法按需扩展;全局事务能力、高可用等方面有短板;复杂度高,机器冗余多。。
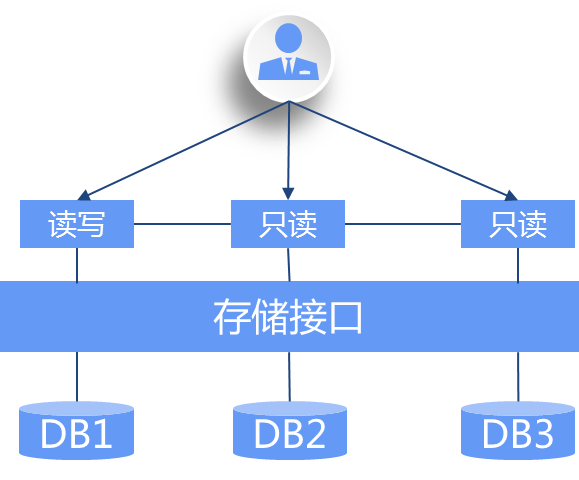
再来看通过构建分布式共享存储实现扩展,采用非对称计算节点,大部分公有云数据库是这条路线。
代表产品:GaussDB(for MySQL)、TDSQL-C、SequoiaDB等;
图片及代表产品来源:《分布式数据库发展趋势研究报告》
由于共享存储能够跨多个节点提供读写,在某种程度上讲,也算是一种分布式。这条路线有限地解决了扩展性问题,跨地域数据一致主要依赖分布式存储的部署形态。
优势:由于上层运行的来自单机数据库改造,兼容性好;日志和数据在分布式共享存储中保持冗余和一致性,产品整合度相对较高;应用不需要改造。
劣势:扩展性有限,尤其是写节点,当数据处理规模要求较高时,仍旧需要分库处理;并且很难做到跨地域高可用。另外,这种架构需要对底座有比较重的依赖,需要对基础设施进行大范围替换。
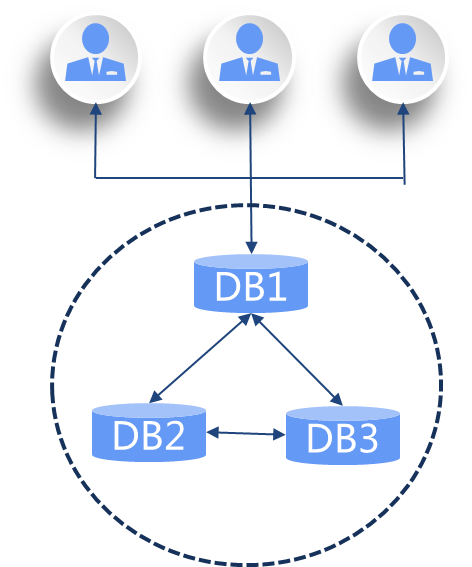
最后,看原生分布式数据库技术路线,各计算节点提供对等的读写服务;
代表产品:OceanBase、TiDB、ZNBase等
图片及代表产品来源:《分布式数据库发展趋势研究报告》
优势:可以按需扩展,没有数量和规模限制;数据一致性的安全保护机制更好;支持跨地域的访问和容灾;硬件依赖少,可灵活进行混合云和多云部署;硬件利用率高,可以通过普通PC服务器实现集群和高可用。
劣势:多数产品成熟度不足,仍需沉淀,没有经过长时间核心系统验证;架构与传统数据库不同,目前虽然一些金融、能源、电信等行业的业务场景已尝试原生分布式数据库的部署,但整体上下游生态适配还有待进一步完善。
总结一下,前两种路线明明更简单,为什么有些厂商会选择第三条路呢?
因为,前2种技术路线,并没有改变底层结构,其底层使用的是非原生分布式数据库,因此,性能和能力受到底层数据库的制约,而原生分布式架构则没有这种制约。
虽然原⽣分布式技术实现难度更⼤,但是下⼀代数据库产品的颠覆式创新⽅向之⼀,且和云计算天然契合。因此,报告认为,原生分布式的技术路线将是产业趋势。
从九大趋势看如何选型
既然,原生分布式数据库是未来主流选择,那么,原生分布式数据库又该怎么选?
在报告给出的分布式数据库九大发展趋势中,我们可以得到一些启示。九大趋势如下:
1、 分布式数据库走向原生设计
2、 分布式数据库架构的设计走向一体化
3、 分布式数据库的能力将向混合负载发展
4、 分布式数据库的场景将向云化发展
5、 分布式数据库的高可用能力不断在提升
6、 分布式数据库对数据一致性的支持将日臻完善
7、 分布式数据库的生态建设亟需推动
8、 分布式数据库需要支持异构芯片的混合部署
9、 分布式数据库应支持数据透明加密
其实,大部分趋势在不少研报中曾多次出现,比如:云、生态、加密等,很多人都有所了解,并不难理解,因此,这里只聊三点:
第一点,数据一致性
众所周知,数据库最重要的就是保管好数据,数据不能丢失,这是基础,如果连这一点都做不到,其它的都是白搭。
报告指出,在可靠数据库管理系统中,事务应该具有四个特性:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)。以往在处理单一事务时,事务的原子性和持久性可以确保在一个事务内,操作多条数据要么都成功,要么都失败。这样在一个系统内部,可以使用数据库事务来保证数据一致性。
但是,在微服务日益广泛的今天,一项操作会涉及到跨多个系统、多个数据库的时候,用单一的数据库事务就没办法解决了。并且,数据一致性不仅指在事务发生时的数据一致性,还需要考虑到主备副本之间、集群之间的数据一致性,以及是否有类似区块链似的校验,具备防篡改的能力和应对磁盘静默错误的能力。需要注意,这里其实提到了数据一致性的四条防线:
1、 数据多副本一致
2、 区块链级校验(防篡改)
3、 存量数据一致性主动校验
4、 磁盘静默错误防御
目前,从整个数据库行业看,不论是Oracle、MySQL还是其它大多数数据库都没有校验主备副本之间的数据一致性。而四道防线都能做到的就更少了。
第二点,一体化架构
什么是一体化架构?能解决什么问题?这是以往的一些分布式数据库研究报中没有出现过的一种新趋势。
报告指出,一体化设计思路是将传统商业数据库的强大单机能力与分布式融合,将多种负载能力在一套数据库上融合,甚至将多种兼容能力体现在一套数据库中。这些是国内重点行业的企业迫切需要的,能够为企业节省大量的迁移适配成本。
从分布式数据库的3种技术路线来看,前两条技术路线并不是真正一体化架构,只能说是分布式中间件或分布式系统,第三条技术路线(原生分布式)才是一体化。
而一体化之后性能、易用、兼容等各方面都会有显著提升,接下来要说的第三点就是如此。
第三点:HTAP
HTAP并不是什么新概念,自从2014年,Gartner首次提出 HTAP(Hybrid Transaction / Analytical Processing,混合事务分析处理)概念之后,HTAP就一直被热炒,因为确实有场景支持,所以,也备受关注,因此,号称HTAP的数据库产品也越来越多。
但什么才是真正的HTAP?是近年来特别火的话题,并不是具有同时处理TP 和AP的能力,就是HTAP数据库。
目前,比较主流的观点是,真正的HTAP,是高度融合的一个系统。这里需要注意,高度融合的一个系统,不是把两个不同的系统拼接在一起形成所谓的一个系统。这并不符合“一份数据”的要求,本质上还是使用两个系统,成本必然大幅上升,并且系统后续的开发和运维,也会有各种问题。另外,这种系统是无法保证对事务的支持能力、数据实效性的。
真正的HTAP,一定是基于一体化架构。当然,这种架构在技术上实现难度更大。但对事务的支持能力和数据的实效性等方面都能提供更好的保证。
最后,总结一下,可以预见的未来,更多的数据库产品最终会走向原生分布式的技术路线,未来原生分布式数据库才是主流选择。而原生分布式数据库到底应该具备怎样的能力?该怎么选?目前,在国内还没有明确的体系标准,但是,我们透过一些研报能发现一些关键指标的,这点在选型时,需要注意。

