对于InfluxDB来说,这是一个令人振奋的时代,它是世界上最受欢迎的时间序列数据库,根据DB-Engines.com,它是过去两年中增长最快的数据库类别。不过当Paul Dix和他的伙伴在十年前创立它的时候,并不是今天看到的InfluxDB的样子。事实上,InfluxDB经历了几次转型,才有了今天的成就,这反映了时间序列数据库类别的演变。而且,更多的变化也即将出现。
Dix和Todd Persen于2012年6月共同创办了InfluxData的前身Errplane,他们的想法是建立一个SaaS指标和监控平台,就像Datadog或New Relic一样。该公司已经从Y Combinator的2013年冬季班毕业,吸引了一些种子资金,并有大约20个付费客户。
拥有正确的基础技术对于Errplane的成功至关重要。几年前曾在一家金融技术公司从事大规模时间序列数据工作的Dix,评估了当时的技术。
当然,当时还没有打包的现成时间序列数据库,所以他基本上是利用开源组件从头开始建立一个。他用Apache Cassandra作为持久层,用Redis作为快速实时索引层,用Scala将其连接起来,并作为一个网络服务公开。这就是Errplane后台的第一版。
到2013年底,Dix已经开发了第二版,在Errplane内部运行,使得Errplane从市场上众多SaaS指标和监控供应商的中脱颖而出。他再一次从开源这个伟大的工具箱中寻找答案。

InfluxData联合创始人&CTO Paul Dix
“我拿起LevelDB,这是一个存储引擎,最初是由Jeff Dean和Sanjay Ghemawat在谷歌编写的,他们是谷歌有史以来最棒的两个程序员,”Dix说。他用一种叫做Go的新语言编写了V2的功能,并将这些功能作为REST API公开。
虽然产品运行良好,但越来越明显的是,该公司正在挣扎。“我说,'你知道吗,Errplane这个应用做得不好,是不可能起飞的。我们不会在这方面脱颖而出,”Dix说。“但我认为这里的基础设施有搞头”。
事实证明,Errplane的客户对该产品的服务器指标和监控方面并不感兴趣,而是对处理大量时间序列数据的能力感兴趣。他的注意力被激起,Dix在那年秋天参加了在德国柏林举行的Monitorama会议,这时他的怀疑得到了证实。
“我看到的是,从后端技术的角度来看,每个人都在试图解决同样的问题,”Dix告诉Datanami。“大公司的人正试图推出自己的堆栈。他们正在寻找一个解决方案来存储、查询和处理大规模的时间序列数据。我们试图建立更高级别的应用程序,而我们自己也在尝试这样做,这对供应商来说是一样的。”
“退化”的用例
时间序列数据本身并不特别。任何数据都可以成为时间序列的一部分,这仅仅因为它有一个时间戳。但是,使用时间序列数据的应用类型确实有特殊的属性,正是这些属性推动了对管理时间序列数据的专业数据库的需求。
在Dix看来,大量使用时间序列数据的应用属于混合了OLAP和OLTP工作负载元素的类别,但两者都不适合。
“实时性方面使它看起来有点像交易型工作负载,但事实上,它是大规模运行的历史数据,你在上面做大量的分析,使它看起来像OLAP工作负载。”他说。
Dix说指出可以使用交易型数据库来处理时间序列数据,而且人们经常这样做,但是规模很快就会成为一个问题。“即便在达到真正的大规模之前,你每天都要插入几百万甚至几十亿条新记录。”他指出。
Dix介绍,OLAP系统,比如如面向列的MPP数据库和Hadoop风格的系统,常被设计用来处理大量的时间序列数据。但是OLAP系统的设计并不是为了对新数据提供连续的实时分析,使用时会有代价。
“他们(OLAP系统)会有一些时间段,在这些时间段里,你摄入数据并将其转换为更容易大规模查询的格式,然后你每小时或每天运行一次报告。”"Dix说。
数据驱逐是时间序列数据需要特别处理的另一个方面的问题。时间序列数据的价值通常会随着时间的推移而下降,因此为了降低成本,用户通常会删除旧的时间序列。
“现在,在事务性数据库中,它并不是设计来删除你放入数据库中的每一条记录的,”Dix说。“大多数事务性数据库实际上是为了永久保存数据而设计的。就像,你永远不想失去它。因此,这些数据库设计的目的不是为了自动清除过时的数据。”
由于这些挑战,所有的大型服务器指标和监控公司最终都建立了他们自己的时间序列数据库,Dix说。“他们甚至不再使用现成的数据库,因为这些不同的东西使时间序列成为我所说的‘退化’的用例。”
适时的新开端
到2015年,Dix和他的伙伴准备放弃Errplane,开始将后端作为时间序列数据库出售。好消息是他们已经走在了前面,因为他们已经有一个可以出售的数据库。
“当我们发布InfluxDB时,人们立即产生了兴趣,”Dix说。“很明显,我们马上就发现了一些东西。开发人员有这个问题,他们需要这种技术来解决它。你如何存储和查询时间序列数据?不仅仅是在大规模上,而是如何在较低的规模上也能轻松做到这一点?”Dix说。
InfluxDB不需要大量的工作就能落地。最初的版本和Errplane V2后台最大的不同是对查询语言的需求,Dix把查询语言比作洒在上面的 “语法糖”。这是以一种类似于SQL的语言的形式出现的,称之为InfluxQL,用户可以用它来编写查询(而不是仅仅使用REST API)。
但这项工作还没有完成。InfluxData筹集了一些额外的资金,并开始开发新版本的数据库,以及周边的工具(ETL,可视化,警报),最终成为TICK平台的一部分。
Dix也着手重建数据库,InfluxDB 1.0在2016年9月首次亮相。
“那个版本的InfluxDB,我们从头开始建立自己的存储引擎,”Dix解释说。“它在很大程度上受到LevelDB和那种设计的影响,但我们称它为时间序列合并树,LevelDB被称为分层合并树。因此,我们有自己的存储引擎,但其他一切仍然是Go,这就是开源部分。”
对云的开放
InfluxData在MIT许可下开放了源代码,允许任何人获得代码并使用它。这家旧金山公司还在AWS上开发了一个云产品,为客户提供了一个完全可管理的时间序列数据的体验。它还开发了一个有高可用性和扩展集群的闭源版本。
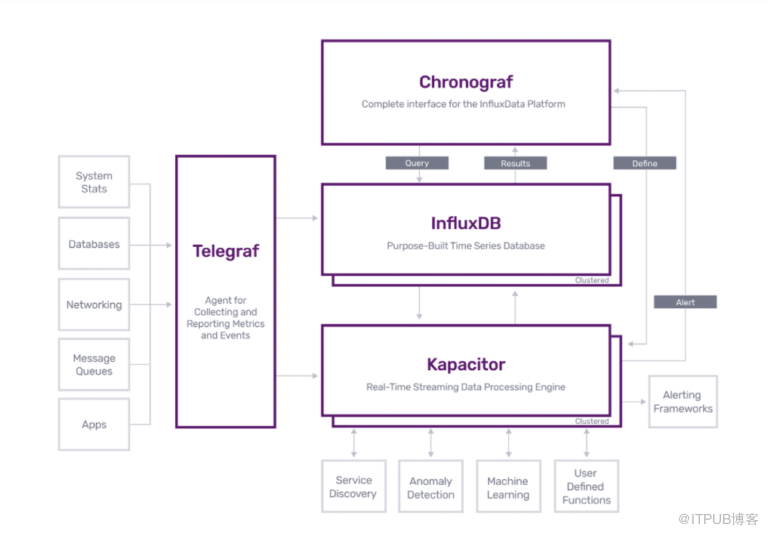
InfluxData TICK平台
与此同时,InfluxData的平台愿景也在增长。2018年推出的TICK由四个部分组成:一个名为Telegraf的数据收集器;InfuxDB数据库本身;可视化工具Chronograf;以及处理引擎Kapacitor。
“我们想找出一种方法,以一种更有意义的方式将这四个不同的组件联系在一起,它们有一个统一的语言,”Dix说,他们用一种名为Flux的新语言来解决这个问题。“我们想做的另一件事是转向云优先的交付模式。”
虽然当时InfluxData的大部分客户都是在本地部署,但Dix告诉开发团队,他希望能够在一年中的任何一天对平台的任何部分进行更新。这一转变在2019年完成,如今云成为InfluxData业务中增长最快的部分。
上周,InfluxData发布了几个旨在帮助客户处理物联网(IoT)数据的新功能,包括更好地从边缘复制到InfluxDB Cloud的集中实例;Telegraf对MQTT的支持;以及通过Flux更好地管理数据负载。
在不久的将来,InfluxDB的核心底层技术也会有一次重写。
“我个人关注的感到兴奋的大事是,我们基本上正在建立一个新的存储技术核心,这将在今年取代云环境中的一切。”"Dix说,“它是用Rust编写的,而我们几乎所有的其他东西都是用Go编写的。现在广泛使用Apache Arrow。”
Dix说介绍,使用Arrow将大大提高InfluxDB查询的速度,以及查询更大数据集的能力,公司还将增加使用老式SQL查询数据库的能力。他说它还将通过添加Python和JavaScript来增强Flux语言(用于定义后台处理任务)。
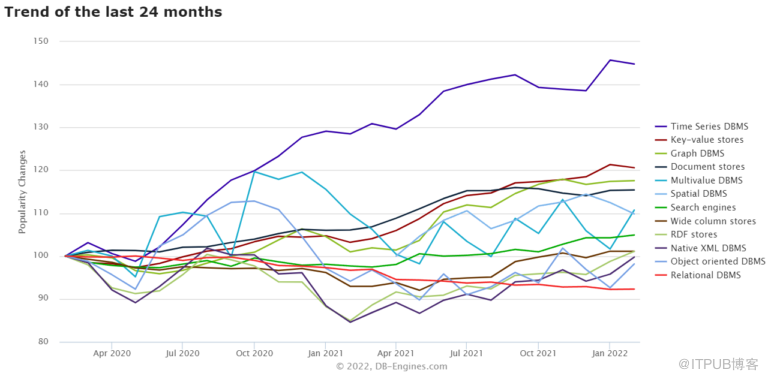
虽然InfluxDB在时间序列数据库领域有很大的领先优势,但根据DB-Engines.com,该类别作为一个整体是相当年轻的,仍然处于成长阶段。对于Dix来说,这意味着更广阔的机会。
“对我来说,关于创建InfluxDB的关键见解是,时间序列是一种有用的抽象,可以解决许多不同领域的问题,”他说。“比如,服务器监控是一个,用户分析是另一个。金融市场数据、传感器数据、商业智能等等不胜枚举。”
当你加入物联网和机器学习这些时,时间序列分析的潜在机会变得更大。它最终会有多大?只有时间会告诉我们答案。

