数据库选型越来越难,据DB-Engines数据库流行度排行榜显示,目前全球有多达359个开源和商业的数据库。
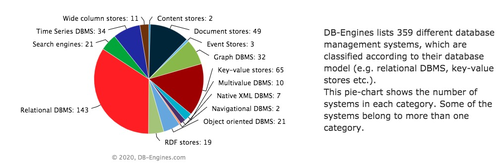
从应用类型看,有OLTP事务型数据库,有OLAP分析型数据库,还有HTAP混合型数据库。
从存储方式看,有关系型数据库和非关系型数据库(NoSQL)之分。而NoSQL数据库又依据支持的数据模型不同,分为键值数据库、文档数据库,列式数据库,图形数据库等。
如果从架构类型看,又分Share Everything、Share Storage、Share Nothing。
数据库市场百花齐放虽然给企业带来了更多选择,但也导致选型变得更加困难。
专用 VS 多模
关于专用数据库与多模数据库之争,由来已久。其中,AWS属于专用数据库派,认为数据库就应该像汽车一样,不同的汽车解决不同的运输需求,不同数据库去解决不同场景需求,而不是通过关系数据库来一刀切。

因此,AWS提供的数据库产品组合多达十几种。
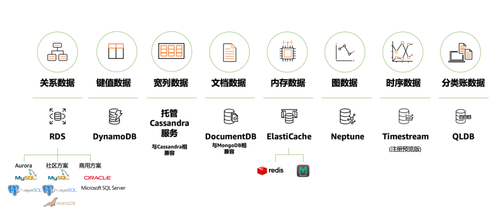
AWS 数据库服务一览图
而甲骨文、微软、SAP则属于“瑞士军刀”派,即多模数据库派。通过扩展其SQL查询功能或添加功能(如R或Python支持)来实现多模功能。
去年,DeveloperWeek一组调查数据显示。有将近一半受访者实际上使用了不止一种数据库来支持其业务应用程序,而不是单个数据库!使用多个数据库的比例为44.3%,使用一个数据库的比例为55.7%。虽然看起来使用一个数据库的比例还是更多,但不能忽略一点,多数据库的使用在过去10年出现了爆炸式增长。
数据显示,75.6%的多数据库类型组合使用了SQL和NoSQL数据库。这进一步说明,对于许多企业来说,并不能一刀切。
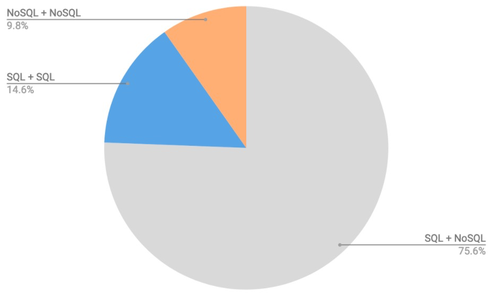
图片及数据来源:ScaleGrid
显然,数据格式、应用场景纷繁复杂,很多需求已经不是单一数据库能解决的。同时,微服务架构的崛起,也在推动企业不同业务场景采用不同的数据库,如果选择不当,会导致服务的性能上不去。
因此,选型时不要将企业的数据库限制在一种数据库上,相互补充才能填补数据库需求的空白。
选型要点
1、业务场景
任何脱离业务场景需求的数据库选型都是耍流氓。
数据库选型的决定性因素是结合业务应用场景,分析目前已有的需求和未来可能会出现的新需求,来考量选择何种数据库。
业务用数据库来做什么?分析还是交易?或者两者兼而有之?业务要处理什么样的数据?对数据库性能需求是什么?
如果是传统的ERP、CRM、财务等企业内部应用,需要事务完整性,保证ACID事务,那么,毫无疑问,关系型数据库是非常好的选择。如果业务要做物联网数据采集和监控,需要高频、实时、持续的写入,那么,时序数据库是正确的选择。
业务要处理什么样的数据?结构化?半结构化?非结构化数据?决定需要支持的数据模型。原则上“什么数据模型,就用什么库。”
如果你要存储和处理的是图片、音频、视频等非结构化数据,那么,NoSQL数据库会是非常好的选择。进一步来说,业务要存储游戏场景中的角色信息、经验道具信息、好友排名等信息,而这些信息一般都和 ID(键)挂钩,那么,键值数据库是个很好的选择。
业务需要处理的多大的数据规模、并发吞吐量、响应时间需求是什么?决定了对数据库的性能需求。
如果业务是秒杀,春节火车票等,有超高峰值业务,那么,分布式数据库会是一个不错的选择。
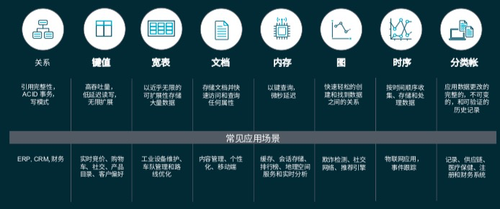
常见的数据类型和应用场景(图片来源:AWS)
不清楚什么业务场景下应该选用哪种数据库系统的,可以参考上图。
2、可运维性
有种说法,数据库选型不考虑可运维性的都应该枪毙。虽然说法夸张,但也有其道理,毕竟,数据库买来最后是DBA来运维,DBA的意见不能忽视。
自身团队技术储备如何?选型要考虑现有开发、运维人员的技能,尽量选择学习曲线短的。
数据库选型,很多人会忽略生态,一个好的数据库不仅自身强大,周边生态完善很重要。与周边上下游产品的兼容性,配套软件、工具、技术人才等都对可运维性产生极大影响。
每一种数据库都不简单,掌握都需要一个过程。数据库发生问题,如何快速定位并解决问题?如果有个活跃的用户社区,DBA会有信心很多。
如果选择了一种数据库,但招不到DBA,一旦人员流失,让数据库处于无人维护的境地,那也挺要命的。
良好的工具生态可以节省企业的开发及运维人员投入。例如:迁移工具,AWS DMS早在2016年3月就已推出,可以让用户轻松地将其数据库迁移过来,同时避免停机。事实证明该服务很受欢迎,AWS官方数据显示,截止到目前,DMS已经帮助20万个数据库进行迁移。
如果你选择的是云数据库,那么,有Serverless(无服务器)模式的云数据库会让运维更轻松,以AWS为例,Amazon Aurora Serverless,Amazon DynamoDB,Amazon TimeStream,Amazon Keyspaces,这些都是无服务器版本的数据库,数据库可以根应用程序需求来自动启动、关闭以及扩展或缩减,而无需管理任何数据库实例,能极大降低数据库管理的工作量。因为,手动管理数据库容量需要占用宝贵的时间,也可能导致数据库资源的使用效率低下。
3、成本
数据库选型不仅要考虑部署数据库的硬件资源成本、软件成本、服务成本和人力成本,还要考虑隐形的成本,比如迁移成本、维护成本、学习成本,运营成本等。
随着开源数据库的流行,存在一种选型误区,认为开源数据库省钱。其实,开源数据库未必就比商业数据库成本低,虽然没有License费用,但对技术团队要求很高,对于一般传统行业是玩不转的,如果你的技术团队不具备这种能力,还不如商用数据库更省心甚至省钱。
如果想在两者中取得平衡,那么,一些结合了新技术新硬件的新兴数据库可能是不错的选择。比如:AWS Aurora,既兼容主流的开源数据库MySQL和PostgreSQL,又具备商业数据库的性能优势。用大白话说,就是既能省钱,性能又要优于开源数据库。
分布式数据库虽然很火,但也不要盲目赶时髦,要用对地方,要清楚什么场景适合分布式数据库,什么场景不适合,否则,不仅达不到预期效果还更费钱。
写在最后
虽然,数据库领域各种新技术新概念不断涌现,但还谈不上谁替代谁。
目前,没有功能较多的数据库,只有最合适的数据库。数据库选型还是要根据业务需求来选择最合适的产品,切勿盲目赶时髦,去追新求热。

