【IT168 评论】Apache Ignite是一个高性能、分布式的内存计算平台,在用户应用层与数据层无缝插入,Apache Ignite改变了传统的磁盘存储方式,从基于磁盘的存储层把数据加载到内存,这一举措让Apache Ignite的性能提升了接近六个数量级(近100万倍)。
内存数据易于扩展,扩展时只需在集群中添加更多的节点即可。此外,Apache Ignite还支持ACID 事务和 SQL查询,Apache Ignite的性能、数据规模以及综合能力都远超传统内存数据库。
Apache Ignite不需要用户频繁更换他们现有的数据库,其支撑任何底层存储平台,不管是RDBMS、NoSQL,又或是Hadoop。Apache Ignite在数据访问和处理层能够实现高性能交易、实时流媒体和快速分析。Apache Ignite既可以在本地部署,也可以在云平台或混合环境中运行。
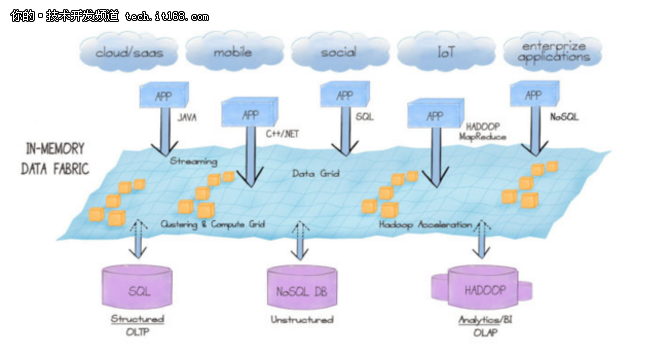
Apache Ignite统一API支持SQL,C++,.Net,Java,Scala,Groovy,PHP和Node.js。统一API连接 cloud-scale 应用与多种数据存储类型,包含结构化、半结构化和非结构化数据。它提供了一个高性能的数据环境,使公司能够处理full ACID事务,通过实时、互动和batch查询产生有价值的见解。
用户可以保留现有的RDBMS,并在RDBMS和应用层之间部署Apache Ignite,Apache Ignite自动集成了Oracle,MySQL,DB2,Postgres,Microsoft SQL Server以及其他的RDBMSes.该系统自动生成基于底层数据库的架构定义的应用程序域模型,然后加载数据。内存数据库通常只提供SQL接口,而Apache Ignite支持更广泛的访问和处理范例。Apache Ignite支持键/值存储、SQL访问、MapReduce、HPC / MPP处理、streaming/ CEP处理、聚类以及Hadoop加速器。
该项目最初是由GridGain Systems开发的,在2014年捐赠给了Apache软件基金会,2015年1月,GridGain通过Apache 2.0许可进入Apache的孵化器进行孵化,很快就于8月25日毕业并且成为Apache的优异项目,到2016年第二季度,Apache Ignite下载量为20万次,被世界各地的组织使用。
架构
Ignite的所有节点都是平等的,没有master节点或者server节点,也没有worker节点或者client节点,但是,可以将节点配置成master,worker,或者client以及data节点。 所有集群节点启动时都会自动将所有的环境和系统属性注册为节点的属性,但是也可以通过配置自定义节点属性。
SPI( service provider interface )是Apache Ignite的核心。基于SPI的设计可以使Apache Ignite的内部组成部分可定制和可插拔,同时这种设计也使得系统有巨大的可配置性,以适应任何现有的或未来的服务器基础设施。
Apache Ignite支持基于Fork-Join、MapReduce、MPP-style的分布式计算。
特性
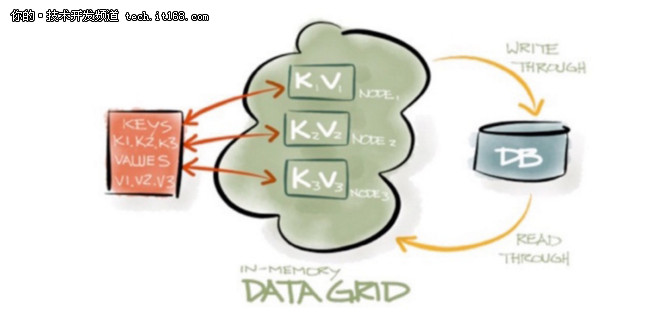
数据网格,Apache Ignite是一个基于内存的分布式键值存储,包括ACID 事务,故障转移,高级负载平衡和广泛的SQL支持。与以磁盘作为主要存储机制传统的数据库管理系统不同,Apache Ignite的数据存储是基于内存的,这一设计让Apache Ignite的速度比传统数据库提升了一百万倍。
SQL支持,Ignite支持完整SQL(ANSI-99)语法以查询内存中的数据,包括聚合、分组等等,并支持分布式非同位的SQL join和 cross-cache join,Apache Ignite还支持字段查询来减少网络和序列化开销。
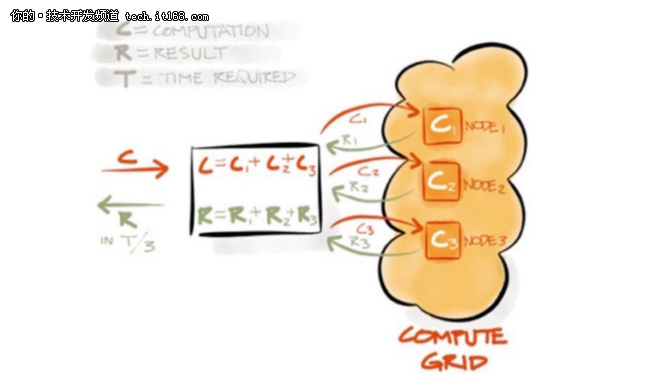
计算网格,Ignite计算网格提供了一组简单的API来允许用户在集群内的多台计算机中执行分布式计算和数据处理,同时支持Java异步处理。
服务网格,Apache Ignite服务网格提供给用户在集群上部署服务的完全控制权,比如自定义计数器,ID生成器,分级映射等。服务网格的主要应用场景是提供了在集群中部署各种单例服务的能力。但是,如果你需要一个服务的多实例,Ignite也能保证所有服务实例的正确部署和容错。
流处理,基于传统处理方法和磁盘存储的应用程序远远不能满足人们的需求的,而基于内存的流处理应用程序扩展了传统数据处理基础设施的限制,可以达到每秒处理百万级事件,最大程度上满足人们的需求。
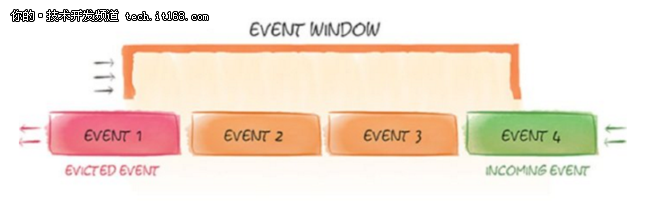
Ignite流功能允许在数据滑动窗口内进行查询。可以使用所有的Ignite数据索引功能,再加上Ignite SQL、TEXT,以及基于谓词的缓存查询,在数据流中进行查询。这使用户能够回答“在过去一个小时内的10个非常受欢迎的产品/产品较受欢迎是什么?”或“在过去的12个小时,某些产品类别的平均价格是多少?”
另一种常见的流处理用例是流水分布式事件工作流。随着事件进入系统,事件的处理被分为多个阶段,每个都必须在集群内进行适当的路由处理。这些可定制的事件流程支持复杂事件处理(CEP)应用。
Hadoop加速器,Apache Ignite Accelerator 通过现有的工具和技术在Hadoop环境中实现数据快速处理。Apache Ignite基于内存的Hadoop加速器与Hadoop HDFS和MapReduce实现百分之百的兼容优化。基于内存的HDFS和MapReduce要比传统基于磁盘的HDFS和MapReduce更简单易用,其性能要比MapReduce和Hive快百倍。

分布式存储文件系统,Apache Ignite的一个独特功能是Ignite File System(IGFS),这是一个内存数据的文件系统接口。IGFS的功能与Hadoop HDFS功能相似,它拥有在内存中创建一个功能齐全的文件系统的能力。IGFS 是Apache Ignited Hadoop加速器的核心模块。
每个文件的数据被分成一块一块的数据块然后存储在缓存中。每个文件中的数据可以用一个标准的java API访问。对于文件的每个部分,开发人员可以在相应节点计算和处理文件内容,避免不必要的网络开销。
统一API,Apache Ignite统一API支持应用层数据存取的各种常用协议。支持的协议包括SQL,java,C++,.Net,PHP,MapReduce,Scala,Groovy和Node.js。Ignite支持多个客户端连接协议,包括 Ignite Native Clients、REST/HTTP、 SSL/TLS和Memcached.SQL。
独立集群,Ignite节点之间会自动感知,这有助于集群的可扩展性,而不需要重启集群,简单地启动新加入的节点。开发者还可以利用Ignite的混合云支持,它允许用户可立私有云和公共云之间的连接,如AWS和微软的Azure。
附加功能,Apache Ignite提供高性能的通讯功能。它允许用户通过发布、订阅和直接点对点的通信模型交换数据。
Apache Ignite的分布式事件功能允许应用程序接收在分布式网格环境中发生的缓存事件的通知。开发人员可以使用此功能通知关于在集群内执行远程任务或任何缓存数据的更改的通知。事件通知可以分为分批发送和及时发送。分批事件通知有助于实现高性能和低延迟缓存。
Apache Ignite允许java.util.concurrent框架中的大多数数据结构使用分布式。例如,你可以在一个节点添加一些信息后,使用另一个节点来获取,或者你可以使用分布式的基本类型生成器来保证所有节点的唯一性。
Apache Ignite支持的分布式数据结构包括:Concurrent map, distributed queues and sets, AtomicLong, AtomicSequence, AtomicReference, and CountDownLatch.
集成
Apache Spark,Apache的Spark是一种快速易用的大数据处理框架。在内存计算解决方案中,Apache Ignite和Apache Ignite是互补的,他们一起配合使用,在许多事例上展现了卓越的性能
Apache Spark和Apache Ignite通常是用来解决不同的用例,因此很少会竞争同一个任务。下面的表格列出了一些它们之间的关键差异。

Apache Spark不提供共享存储,所以从HDFS或其他磁盘存储的数据必须加载到Apache Spark中加工。Apache Ignite可以在内存中直接共享Spark状态。
Ignite和Spark的另一重要集成就是Apache Ignite Shared RDD API。 Ignite RDD本质上对Ignite 缓存的展现,Ignite的所有改变都会对RDD用户立刻可见,Ignite RDD可以直接在Spark作业执行过程中部署。Ignite RDD也可以使用缓存模式,在内存中部署来自Spark的数据,这些数据仍然使用Spark RDD API来访问。
Apache Spark支持丰富的SQL语法,但不支持数据的索引,它必须做全扫描,所以Spark即使在中小型的数据集中的查询时间也需要几分钟。而Apache Ignite支持数据索引,所以查询速度要比 Spark SQL快1000倍以上。 Ignite Shared RDD返回的结果集中也符合 Spark Dataframe API,,因此进行进一步分析时仍然可以使用Spark。Spark和Ignite都集成了Apache YARN 和Apache Mesos,所以它们之间的互通性更多。
Apache Cassandra,Apache Cassandra可以作为结构化查询的一个高性能解决方案,其包括许多存储节点,并且在单个存储节点内存储每一个行。在每一行内,Cassandra 总是存储按照列名称排序的列,Cassandra的异步查询可以提供很高的性能。
虽然Cassandra在某些情况下非常强大,但是其缺乏一个内存选项,这将严重限制其性能。 Cassandra支持 OLAP应用但不支持事务,所以不适用OLTP。Cassandra支持预定义查询,但其不支持SQL支持,也就不支持连接,聚合,组合或可用性指标。这些限制意味着Cassandra无法支持即席查询。
Apache Ignite提供了Cassandra的原生支持。Ignite和Cassandra用户都获得了强大的功能,如利用内存计算减少查询次数。

