【IT168 专稿】本文根据【2016 第七届中国数据库技术大会】(微信搜索DTCC2014,关注中国数据库技术大会公众号)现场演讲嘉宾窦贤明老师分享内容整理而成。录音整理及文字编辑IT168@胡晴。
讲师简介

▲窦贤明(执白)
窦贤明老师是阿里云资深研发工程师,有六年程序开发经验,关注分布式数据库、关系型数据库、云计算、分布式存储等技术,PostgreSQL信徒。现就职于阿里云数据库技术组内核服务组,负责ApsaraDB(RDS) For PostgreSQL/Greenplum的内核、自动化运维等研发工作,旨在实现用户在云数据库上的良好体验。
正文
大家好,我是窦贤明,在阿里云做工程师。今天给大家简单介绍在PostgreSQL上做索引优化的简单思路,不做过多的深入,就是大概的介绍,让大家了解一下。
在接触客户过程中,我们遇到非常多的性能问题,是他们在公开执行方面的问题。解决过程中发现一些通用的东西。
性能问题遇到最多的情况在哪里?比如一个查询时间长,可能几秒或者更长时间结束。客户用的处理技术参差不齐,互联网客户比较多,数据也有些参差不齐,所以会遇到各种各样的性能问题。然后他们会经常问,我的CPU怎么占满了?我的IO为什么这么高?内存值也这么高?
性能问题:
其实有一个解决思路,给大家简单介绍我们主要面临的问题。
查询时间长
资源占用:这里提的是两个比较典型的CPU高和IO高。
1、CPU高:数据在内存里
2、IO高:数据在磁盘里
这是两个非常典型的性能出现瓶颈的地方。
其实都是索引的问题。当出现所有问题的时候,往往面临全盘扫描。而当数据出现在内存中时就耗CPU,在磁盘里的时候就耗IO。怎么解决这个问题?就是建立一个合适的索引。
选择一个索引通常有两步,第一步选择对哪些列进行索引;第二步是创造什么类型的索引。
列的选择:
第一步就是怎样选择这一列,当我们选择列的时候,往往看SQL语句。
1、where子句:所以首先会看到后面的where子句,where子句用于过滤所查询的结果,代表我们要查询多少行、查询多少数据,这个就是我们的核心。
2、order by子句
3、group by子句
4、函数参数
还有order by、group by、函数参数,这就是函数索引。
索引的选择:
第二步是索引的选择,但一般不可能对所有列建立索引。大家都知道索引是有代价的,比如插入速度的减缓、空间占有都会有代价。选择一个比较关键的字段就可以了。
1、基数:判断的标准就是索引字段值的基数
2、相关性:索引和磁盘相关性的问题
3、代价(选择性、直方图、MCV\MCF):最终评判标准就是看哪个代价更低
通过这个基本原理,我们可以找到针对哪些列做索引,再选择做什么样的索引。

PostgreSQL提供了很多信息来辅助我们UA、应用者,和开发者。我们关注几个系统表里跟索引相关的:
1、stat_user_tables:记录索引表的所有相关信息,包括进行多少次全表扫描、更新情况。
2、stat_all_indexes:记录索引的扫描情况,也可以用于判断建立这个索引对于索引数据的有效性。
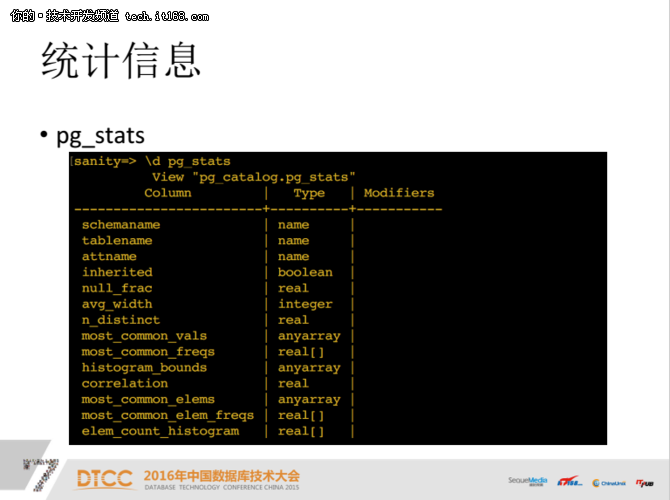
3、pg_stats / pg_statistics:这个是后面主要用到的地方,会记录非常多的统计信息。

这是它的表结构,涉及到null_frac、avg_width、n_distinct几个比较重要的字段。后面我们会用,大家要记住。
第一个叫n_distinct,很多情况下是一个比值,基本上来算基数。当基数个数并不多的时候,它会是一个正整数,表示有多少个基数。比如最典型的性别,有两个,没有三个,所以它的基数就是2;当基数数值都不一样的时候就是-1;当它是一个比值的时候,基数是一定范围,大概是30%—50%。
第二个是比较重要的是most_common_vals,就是哪些字段出现的频率最高。most_common_vals也是一个数字类型叫数组,下面的most_common_freqs是它占用的比例,这个比例表示一个字段在所有基数中占有的比例是多少。
还有一个histogram_bounds,就是直方图。
方法:
第一步应该把SQL拆解,拆开之后看写法。
倒数第二条的filter条件,是指过滤条件。
上面的Seq Scan on vtbl是指这个地方没有索引,所以只能全盘扫描。
后面还有一个cost,是很关键的一个数字。它会帮助我们决定这个索引有没有作用、有没有帮助、帮助有多大。所有产业计划的核心就是cost,这个代价是不是够低?代价比较少,扫描就比较少,占用时间就比较少。
要注意一点,pg的数据都是采样,它的数据只能说达到一定比例,不是百分之百精确。所以cost值也是估算的,不是绝对精确的值。

案例一:
这是一个非常典型的例子,也是非常复杂的一张表,因为涉及到ID、key。
key相当于一个值,不过没有什么意义。
shape是我自己构造的一个多维向量,是一个非常复杂的数据类型,可以任意组合任何数据,如IP数据、点数据和几何数据。它一个三维的数据,可以用来表现它的三维位置。
Location是一个geography的数据,location_geometry是一个几何数据,comment是test,是随机的状态。
这边看完以后我们看一下上面的语句,这条语句其实非常典型,就是一个简单的查询。然后有两个条件,一个是key,一个是shape。
刚才例子中的where语句分成两个字段,key和shape。我们第一反应看这个数据是不是应该在key和shape上做过滤,在这个上面去索引。
但是那怎么建呢?是这两个都建吗?很多时候是没有必要的,往往针对某一个做到比较高的过滤性的时候,这个索引就已经足够了,建两个的时候空间是有一点浪费。

correlation就是一个典型的磁盘和他的数据的相关性。
如果是完全顺序的话比较好,就是一个索引。如果不是顺序,放在磁盘中间比较有效。例如不是1或者-1的时候,它的随机IO比较高,但如果它是零点几的时候,就不是完全顺序的。但这个时候最好的地方是相关性,因为都涉及到IO,这样会IO效果会更好一点。
n_distinct是一个基数,等于-1是说这个key每一条基数都是唯一的,大家如果有经验就会知道这个非常适合检索。correlation并不是很高,索引对我们来说是有一定帮助的。mcv、mcf没有值,因为所有频率都是一样的。

而shape不一样,大约是几十万条构成的,是一个三维的值。
n_distinct其实并不是2000个,大约是有几十万个n_distinct的基数,因为它也是估计值,是根据采样出来的结果。但是n_distinct大约是几十万条,所以这个大家要注意一点。一般来讲为正数的时候是有限度的,可以这样理解。
correlation非常低,它的行和行的随机排列比较多,这个时候的索引属于有帮助的。
mcv的取值跟它的采样数据有关,重新进行采样或计算时,每次采样都不一样,mcv肯定每次都会变。correlation可能会有点变化,n_distinct变化不会太大,但是mcv会变化。
其中一个值70,103,206,它是第一条数据,大家可以看到频率并不算高,相对来讲频率比较低,是它上面的值对应的一个频率。这个很简单,是来计算代价的。大家了解之后就知道这个的代价是什么,后面就会讲代价计算的问题。

选择性:
大家看选择性的问题,n_distinct基数的个数是-1,就意味着6990419这条语句一定只有一条,一条数据其实就是他的selectivity。
selectivity是一段过滤的长度,实际上就是过滤性。如果有这个条件和没有条件之间的差别非常大,说明这个条件的过滤性非常高。如果最后根据索引找到那个地方的值,那么价值就非常大,这种情况是价值最大的情况。
那么再看shape,一千万条基数很容易就找到这个值,这个值的选择性就是70103206。
计算有索引情况的代价:
有索引情况首先会进行全盘扫描,它的代价就是所有的全盘扫描的的IO,加上每次操作符判断的成本,然后再把那条记录去扫描。
回头看一下前面的执行计划,cost其实就两个,一个是Filter,一个是Seq Scan。回到这个问题,这个地方有什么意义呢?当有索引的时候,只要找到对应的索引,找到对应的文件就可以。所以它只有一条记录的IO,加上一个索引的查找,这个成本就非常低了,尤其在基数非常多的情况下。
有一个很有意思的情况,当你基数不是特别多的时候,加索引也没有意义了,因为可能整个全盘扫描的成本,还低于进行随机扫描再加上取IO的成本,基本上这个成本是无所谓的。所以在基数比较少的时候,它的成本比较低。
这个索引之前有一个条件是key和shape共同的条件,成本是33万,这个成本的单位是它自己的单位,是执行前的成本。
要注意几个问题,第一个是Filter条件;第二个是Seq Scan的类型;第三个是cost的值;还有一个是rows,这个是最后的值。这个值比较大的时候,这个索引建不建无所谓。
但是索引之后的情况,一定要注意成本,前面是0.33到8.46,就是33万到8的差别。但shape就没有这么高,我没有把例子放在这里,大家可以自己试一下,这个值不多的时候怎样计算。rows是一样的值,为1。
执行计划其实不一定是执行的情况,不一定准,因为cost毕竟是一个估计值。


建索引前,time是 1673毫秒,就是1.6秒。这个听起来也不长,但是到手机上肯定成问题。
再看建索引之后,28毫秒,大约是50分。一般这个地方比例比较大,最好前面都有ID,效果比较明显。而且记录的数据越多,下面8.46的值基本上不会变化。当mcv、mvf变化,并不是完全唯一时,这个值就不一样。
这是第一个结构,我们最终选择的也是这个。

刚才运气比较好,key的值正好是唯一的。如果key值不一样怎么办?比如key值是0.1、0.008,这个算作大家的一个思考题吧!当这个key的值也不唯一的时候,可以把key和shape结合起来。
案例二:
我们看看第二个,这个看起来很复杂,其实也挺简单,select*from后面是一个子查询,子查询里面又有一个from vtbl,而这vtbl和前面的一样,只不过我把两个不同的字段换了一个标准。
我们注意有几个标识,第一个是ST_distance是一个计算距离的函数,所以这里涉及到函数的关系。
location_geometry这个值用于计算distance,distance的过滤性和选择性就依赖于as distance的计算结果,但是其实这个特别难估计,这个先放着。
我们看order by、where条件、函数等条件,他们都指向location_geometry,那么肯定要看location_geometry。

基数、相关性:
n_distinct是-1,是近似值,那么我们说n_distinct这个值不可靠。我们需要把n_distinct转换成可读的值。


这里遇到一个比较特殊的gist索引,针对几何类型的索引类型。

我们直接看一下结果。


思考题:
然后我们留了几个思考题,大家可以想一下。


这个是大家经常用到的工具。



这里就是我们今天讲的内容。

