-
TDSQL-C 产品介绍
https://cloud.tencent.com/product/cynosdb
列存技术比较 Abadi, D. J., Madden, S. R., & Hachem, N. (2008, June). Column-stores vs. row-stores: how different are they really?
-
TDSQL-C 并行查询用户手册
https://cloud.tencent.com/document/product/1003/81872
-
TPC-H 规范
https://www.tpc.org/tpch/default5.asp
-
阿姆达罕定律
https://en.wikipedia.org/wiki/Amdahl%27s_law
SQL 计算模型 Astrahan, M. M., & Chamberlin, D. D. (1975). Implementation of a structured English query language.
行迭代器 Graefe, G. (1994). Volcano - an extensible and parallel query evaluation system.
即时触发式并行调度 Graefe, G. (1990). Encapsulation of parallelism in the volcano query processing system.
HASH 分区 Kitsuregawa, M., Nakayama, M., & Takagi, M. (1989, August). The Effect of Bucket Size Tuning in the Dynamic Hybrid GRACE Hash Join Method.
-
可分解聚合函数
https://en.wikipedia.org/wiki/Aggregate_function
调度的控制流与数据流实现 Teeuw, W. B., & Blanken, H. M. (1993). Control versus data flow in parallel database machines
-
CSP 交互模型
https://en.wikipedia.org/wiki/Communicating_sequential_processes
以下是文字稿内容:
主持人好,各位嘉宾下午好,很荣幸有这个机会向大家分享一下,我们近期在大查询性能上的一些工作。

这次分享有几个环节:首先是云原生数据库产品的介绍,以及我们遇到的业务挑战,并做一些策略分析。然后,从用户视角来感受一下并行查询的功能使用和性能表现。然后,用一个简单的例子,演示并行查询如何进行加速,以及技术方案涉及的一些基本概念和数学定律。最后,梳理一下并行查询方案的技术要点,以及实践过程中所做的一些选择,并简单介绍一下未来的工作。

Part 1. 产品简介
虽然每个云厂商的叫法有点不一样,云上的关系数据库一般来说有四种形态。TDSQL-C 的定位是云原生数据库,它在架构上是基于物理日志复制和共享存储的高可用集群。

云原生数据库,对于业务而言是非常友好的。MySQL 兼容性几乎是 100% 。除非是使用了云厂商特色的扩展功能,否则,业务可以自由迁入迁出,不会产生云厂商锁定。这可能是大家在选型时比较关注的一个点。另外,由于它采用了物理复制,数据同步性能很高,扩缩容也很方便,这就可以灵活控制成本。在现在的大环境中,成本还是一个很重要的东西。
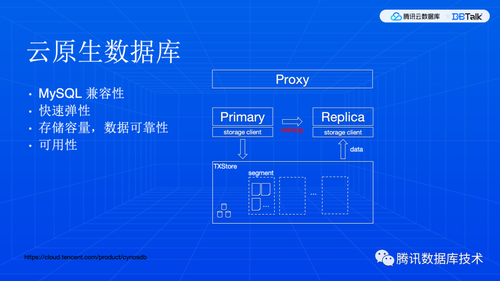
随着业务数据量增长,就产生了新的问题:需要处理的数据量比较大的查询(分析型查询),无法充分利用计算资源(空闲资源),响应时间会拉的比较长。这是因为传统 MySQL 中,SQL 处理是单线程的。我们一般说的并发,是指查询间并发,有多个CPU 核心就可以支持同时跑多条语句进行,但是一条 SQL 语句只能由同一个核来处理。
分析型通常可以从三个方面优化。我们今天的主题是如何调动多个核心来加速同一个查询,称为查询内并发。并行查询,不管是单机的还是多机的,在本质上是做计算任务的拆解和分发,它没有去改变计算的形式,而是在现有架构基础上进行扩展性改造,通过投入更多资源来提高性能。所以,它不算是一个颠覆式创新,但是体验上是很平滑的,使用门槛很低。相对来说,其他两个方面,由于需要结合向量运算和列式存储,实现起来会比较重,使用门槛也会高一些,我们后续也会有相应的能力发布。并行查询和这些 AP 技术的加速效果是可以叠加的。
在架构选择上,也有三种形态。其中 (a) 一般是分库分表,经过一些包装后,现在也叫透明分布式,(b) 是传统的双系统方案。但我们采用的是改造原生内核支持并行,业务使用和运维都比较简单。

Part 2. 功能体验
下面,我们来直观感受一下并行查询带来的变化。

在使用时,要有一个“资源“的概念。一旦规划了核心资源,查询可以立即获得提速,不需要额外操作。
我们可以看到执行计划发生了一些变化。并行计划会有多个线程协商完成,在边界处有一些特殊算子来支持数据交换,这里有 4 个核心各自独立扫描数据,计算结果汇总到用户线程返回汇总处理后返回给用户。除此之外,我们还可以从 process list 和系统指标里看到更多内容,这里就不展开了,大家可以查看左下方链接里的用户手册。

OK ,这是单条语句演示,下面来看看整体表现。这里用的是 TPC-H 业务。TPC-H 是行业基准测试,里面有 22 条查询模拟一个分析型业务,这里面单表、多表、分组、聚合,排序,独立子查询、相关子查询都有。我没有去特别强调函数,因为我们技术方案上对函数是直接继承原生能力的,这个后面会进一步展开。
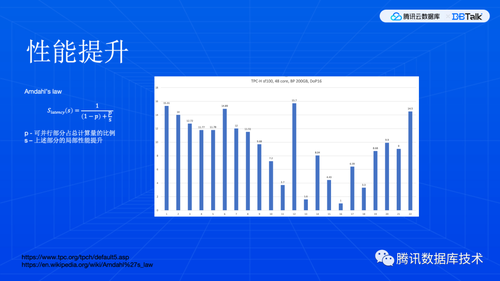
这里是 16 并发性能数据。可以看到 22 条查询中加速效果各自都不同。大部分有比较好的加速效果,但是仍然有个别查询没有明显提升。并行查询加速分析,可以参考阿姆达罕定律。简单的讲,一个程序的加速效果,是由可并行部分的占比 p 决定的。p 越大加速效果越好。如果 p 很小,那么即使投入很多资源来提高局部加速比 s ,整体上也不会有很好的加速效果。所以,并行查询的加速效果,其实是跟业务相关的,每个业务语句都有不同的性能表现。当然,图中 p 值很小的那几条,我们在后续版本还会有相应的改进。
Part 3. 并行原理
OK 下面开始进入干货环节。先看一下技术原理。

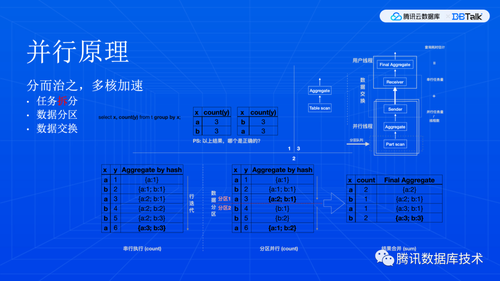
并行查询,本质上讲就是一个字,“拆“。任务拆细,数据集拆小。拆开了大家一起干,自然就干得快。当然,大家一起干,就需要一些协调,协调效率也是很关键的。
这里用一个简单的聚合查询来演示并行查询。在图 1 里是 SQL 文本,还是个附加问题,可以先想想,稍后回答。在图 2 左边,我们看到,计算过程是对于每行都会更新聚合状态,这里借助了哈希表进行计数,所有行处理完了结果就出来了。在图 2 右侧的并行查询里,原始数据集被划分成两半,同时开始算,显然这部分计算速度就可以翻一倍,但是,后面还有一个汇总操作,所以,整体加速其实是到不了两倍的。在图 3 里,用算子和任务图的方式来表达了这个计算逻辑,我们可以看到,聚合运算和底下的数据访问都发生了变化,这就是拆任务和拆数据。同时,图 3 右边也是阿姆达罕定律的一个直观解读。
那么,回到图 1 的附加问题。这个问题也是线上业务反馈比较多的。答案是两个都对。这本质上不是一个并行查询问题,而是业务程序与数据库之间的编程契约问题。这个契约就是SQL 标准,当然也有一些事实标准,我们知道,SQL 集合顺序是在语言标准里是未定义的。业务逻辑依赖于“未定义行为“,其实是比较危险的。类似的问题,大家在日常开发上也可能遇到,因为通用编程语言也有未定义行为,只不过是业务程序和编译器之间的编程契约。
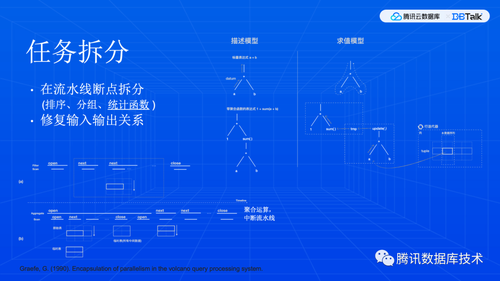
下面我们借一个稍微复杂一点的虚构查询来看看 SQL 计算模型。这个模型其实是分为三个层次的。图 1 中是原始 SQL 和标记,图 2 是其拆解形式,图 3 是图形化的计算结构。图 3 看上去比较复杂。但是这三个查询块的基本形式是一样的,我们只需要关注到数据的流动。查询块输入输出隐含了数据依赖关系。一般是从主查询开始计算,但如果有独立子查询,它不依赖主查询提供输入, MySQL 也可以先计算子查询。查询块内部是关系代数运算,数据自下而上流动。底层操作是集合迭代,每次行迭代都可能会计算一下表达式(函数),表达式数据也是自下而上流动。表达式计算又分普通函数和统计函数。sum count 这些统计函数比较特殊,我们在下一页展开。

统计函数有什么特殊呢?我们知道 SQL 是声明式语言,从描述到实现的差异是很大的。普通表达式,例如 a+b ,是给一行算一个结果,数据随时可以流动。所以,虽然关系代数定义的是集合运算,但是这个集合是一个概念上的东西,不一定要有一个物理上的集合,基于一个行缓冲区就可以有多个运算,这称之为流水线。但统计函数不一样,它要读完整个集合才能出结果,这种称之为流水线断点,我们看到它需要两轮迭代,第一轮迭代读输入集合构造中间结果(例如,并行原理中的哈希表),第二轮迭代输出最终统计结果。
显然,一个自然的任务划分方式,就是在迭代运算的边界上进行拆分,并重新建立输入和输出关系。
那么,哪些计算是可以分解成更小的计算任务,从而并行地执行的呢?大体上分为关系运算和统计函数两类。
关系运算里最常见的是条件过滤,显然子集过滤结果汇总起来就是整体过滤结果。连接操作还有更多优化空间。右边图里表示了对集合进行划分,连接操作可以基于子集运算结果合并而完成,但是两种划分方式,一种不限划分机制,另一种是用同一个哈希函数来进行划分。我们知道,哈希划分有个特点,就是可以筛选出相关数据,这可以让子问题更小,例如,原来 Ri 要和完整的 S 连接,现在只需要和 Si 连接。具体可以看 GRACE 论文里的 Figure 2 。
当然,不同运算的拆解逻辑不一样,这个是由基本运算的语义决定的。这些内容也比较直观,这里就不过多展开了。

Part 4. 技术方案
基于这些原理,来看看具体方案。我们在方案选择上,主要考虑复用和扩展两个点。

首先,要有一个调度框架来负责协调任务的执行顺序。我们从原始执行计划树上构造出来的一个任务图,表示了计算任务之间的依赖关系。显然,所有线程都要用同一个任务大图。
协调线程负责下发任务,其他线程里面就是命令循环,负责执行任务和上报状态。注意这里协调线程是指一个角色,它可以是一个独立的线程,也可以是某个线程兼任的。用户线程是指跟客户端交互的线程,也是最开始的那个线程,它是前台线程,负责向客户端返结果,其他线程都是后台线程。
因为任务执行过程中随时都有可能产生意外,需要中止整个调度,所以,这个调度执行框架要和 MySQL 异常处理框架整合在一起。
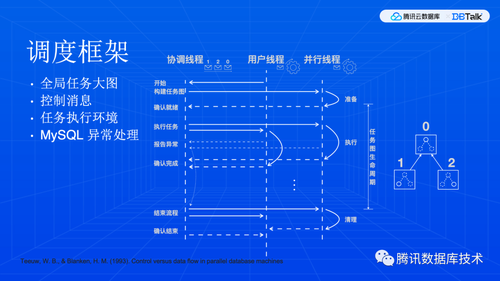
前面的原理部分,大家应该还有印象,就是说大多数计算逻辑内部实现与并行其实没什么关系,我们其实只需要在任务边界上做好输入输出的对接,就可以把多个任务拼成一个逻辑上的大图,至于每个线程上是完整的大图还是大图的一部分,其实是一个实现问题。这种任务的表示,称为任务形态。通常有三种形态,最直观的是控制消息包含完整的物理描述结构,当然也可以用结构相同的图,用约定的标识来定位到任务,或者还原成 SQL 然后重走流程描述。我们采用的是第二种形态,这个主要是从代码复用上考虑,MySQL 工程设计上有点独特,物理结构拷贝的支持比较差,但是优化器已经有能力生成完整的结构,我们只需要干预优化器来产生相同的计算结构,然后做一些修改就可以了,当然,这个修改也是比较有挑战的。此外,这个干预能力还有复用到更多应用场景。第三种通常用在分库分表中间件里,因为中间件和数据库内核实现不一样,传递物理结构更麻烦。
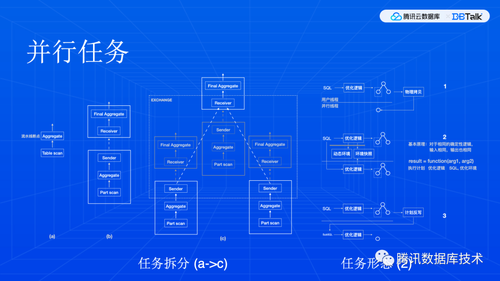
那么,第二种形态是如何达成的呢?我们知道优化过程是本质上是一个搜索过程,从搜索空间中的很多计算结构里找到最好的那个。只要判断逻辑是相同的,就能定位到同一个结果。这个判断逻辑会受到模型参数和一些数据的影响。所以,我们只需要把这些接口进行拦截,将结果缓存下来,新的优化过程里直接用这些缓存结果,就可以实现干预而产生相同的结果。
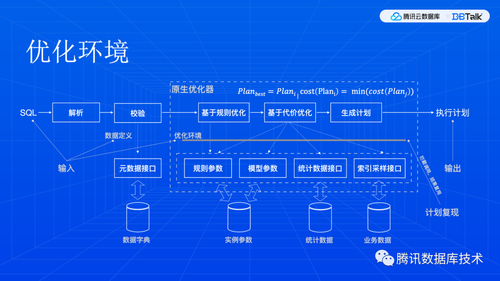
然后,可以开始考虑并行流程了。简单地说,一条查询,要经过串行优化,产生一个计算结构,然后进行检测看看哪些运算逻辑支持并行,然后就要决定并行策略和任务边界,然后把任务数据重新对接好,就可以申请资源来调度执行了。用户手册中有控制各个模块的参数,这里就不展开了。前面说到我们要干预优化器,所以,这里优化环境就记录了如何干预。
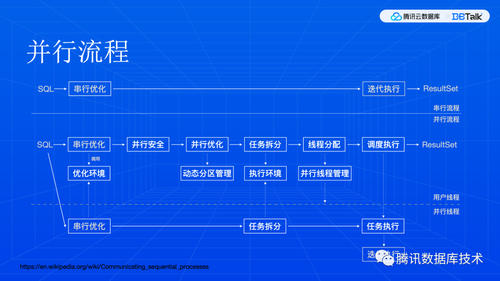
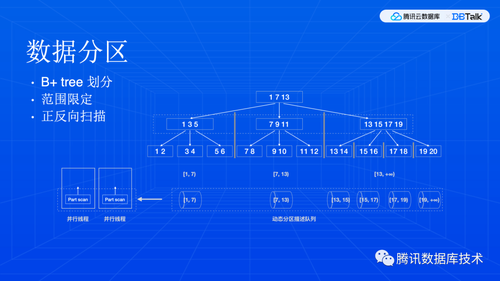
最后,我们来看看数据分区和数据交换两个基础模块。MySQL InnoDB 存储是 B+ 树,这是一颗平衡树,所以,分区其实就是在一个层级上,把元素都取出来,作为分区边界,如果不能够均匀地分给并行线程,那就将剩余的分区进行更低层次的划分,直到大家都有足够的事情可干,而且剩余部分又比较小。当然,这个划分逻辑是社区代码里自带的,我们只需要对它进行扩展,支持对子树进行划分,支持正反向扫描和不同的索引。
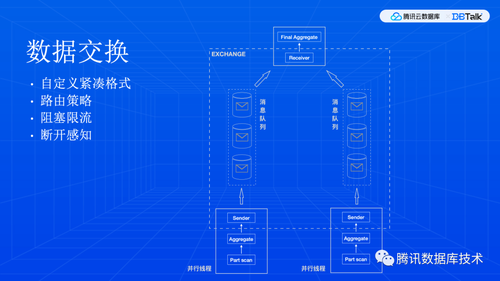
数据交换本质上就是上下游线程之间收发数据。这里其实是一个数据网络,每个线程都有接入网络的算子,一边收发数据,一边用来和任务内部的计算逻辑进行对接。这种算子也称为“桥接”算子。
Part 5. 展望
最后,简单介绍一下未来的工作。
我们在 AP 能力上,后续工作分为两个方向。
一方面是扩大并行查询覆盖范围,做一些深度性能优化,以及支持行列混合调度,发挥各自的优势产生叠加效果。
另一方面,对于 SQL 的使用,也会有一些工作来提高 SQL 执行过程的透明程度,便于问题分析和性能改进。这些工作也不限于并行查询,更重要的是对基础内核的改进,让数据的使用更加便利。

这就是我今天的分享。谢谢大家。


