本文整理自DTCC2021大会分陈宏智博士的演讲,将深入介绍该团队在分布式图数据库、图计算、图训练这三个场景下的自研系统(ByteGraph、ByteGAP、ByteGNN)之架构设计,技术实现,关键挑战以及性能分析。并概述在部分业务场景上,如何通过GraphStudio图平台提供一站式图数据服务。
陈宏智博士,目前在字节跳动基础架构组担任高级研发工程师,本科毕业于华中科技大学计算机学院,博士毕业于香港中文大学计算机科学与工程系,在计算机系统及数据库领域发表顶会论文(EuroSys/SoCC/SIGMOD/KDD/TPDS等)十余篇,研究方向为分布式系统、分布式计算、大规模图系统,曾获微软研究院“明日之星”等荣誉称号。
图数据是一种由点和边组成的半结构化数据,已被广泛应用在社交网络、金融风控、生命科学等各个领域。字节跳动基础架构ByteGraph团队从2018年开始打造基于海量图数据的分布式存储/计算系统生态,并支持了抖音、头条、西瓜、火山等几乎字节跳动全部产品线。
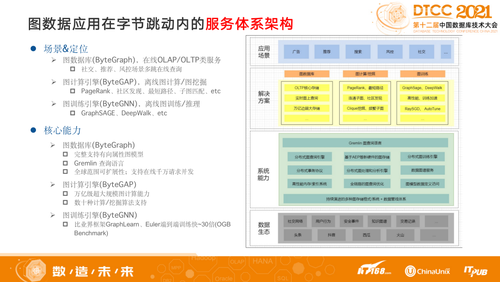
ByteGraph全球范围内多个机房都部署了实例,能够支持在线千万贴片,其图计算的愿景是支持百万亿级的边的规模,此前的图计算引擎是作为一个In-Memory System,没有办法做到百万亿级别的数据分析,所以字节跳动基础架构ByteGraph团队自研了这样一套系统。
图数据库
▶︎ 了解图数据库

图数据库相比传统关系数据库,最基本的区别是建模不同,图数据库是基于点、边和属性构成,关系型数据库是基于Staple来做。查询实现也不同,关系型数据库查询通常需要做多个表单JOIN,大数据量只能分库分表。图数据库在图上遍历(traverse),通过算子去执行,更为高效。字节跳动的图数据库是通过更细度的Message做Partition的方式去执行结果,然后把结果返回。
▶︎ 数据模型和查询语言
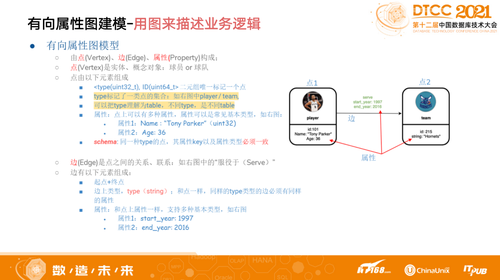
图数据库数据模型分为两种,RDF(俗称三元组)和属性图。ByteGraph采用有向属性图建模。有向属性图由点(Vertex)、边(Edge)、属性(Property)构成,其中点是实体、概念对象。边是点之间的关系、联系。
有向属性图映射真实世界的实体,见上图,比如一个自然人,我们是通过Unit32和Unit64,前者表示自然人,后者表示场景。通过有向属性图建模,可以把不同类型的应用基于同一个自然人关联起来,进行跨表查询。比如基于一个人在某些场景上的用户习惯,通过数据管理,希望借用这些查询结果能够在推荐场景使用,则可以关联一个真实的自然人,这样带标签的属性图,一定要有一个固定的Schema。如上图中,所有球员类型的点都有一个固定的Schema,球队的Schema是另外一种类型。
边是维护实体间的关系,需要用最基本的节点、终点和边上的类型,比如关注类型、点赞类型,基于这种类型绑定的Schema去存储信息,如一个人对一个视频点赞,针对这些用户的属性和视频属性做Sport,可以在边上对该事件信息建模。
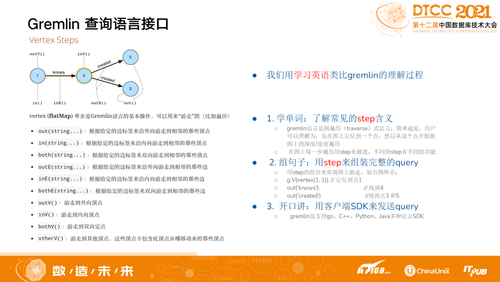
ByteGraph支持Gremlin查询语言。Gremlin语言是图遍历式语言,可以简单理解为,先在图上定位到一个点,然后从该点开始做图上的深度/宽度遍历,在图上每一步遍历用Step来描述,不同的Step有不同的功能。
通过不同功能的Step表示查询逻辑,比如需要去对一个自然人的二跳邻居做一个属性上的限制,能够Out,每次Out对应的参数就是Label,可以限制需要满足哪些属性,之后也可以通过计算方式的属性总和,一定要大于或小于某一个值去做限制。我们认为这样的方式对自己的业务方来说更友好一点,因为业务方不仅仅是有数据库背景的同学,更多的是分析类型的同学。
▶︎ ByteGraph架构与实现
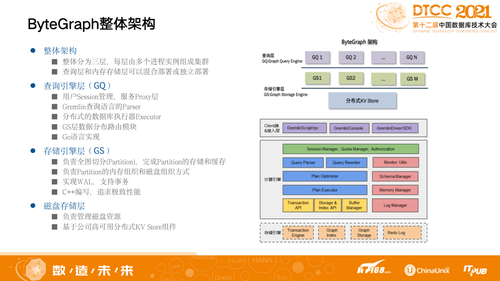
ByteGraph整体架构有三层:查询引擎层(GQ)、存储引擎层(GS)和磁盘存储层,我们是用高可用、高可靠来做三层的组件,每层由多个进程实例组成集群,查询层和内存存储层可以混合部署或独立部署。其中,查询引擎层主要做用户Session管理以及最核心的查询解析,解析之后变成语法数,接下来就会深入展开,然后去做数据分布的Road Mapping,查询更侧重于高并发实现。存储引擎层(GS)管理内存中的数据,如何去做数据切片,如何实现事务性,追求相对偏底层的极致性能,中间通过RPC去做关联。
具体来看ByteGraph查询引擎层(GQ),其实和MySQL的SQL层一样,主要工作是做查询的解析和处理,其中“处理”可以分为以下三个步骤:
Parser阶段:我们实现了一个手写的基于Gremlin递归下降解析器,将查询语言解析成一个查询语法树。
生成查询计划:把步骤1中的查询语法树按照一定的查询优化策略(RBO&CBO)转换成执行计划。为了减少解析和优化的开销,我们支持了查询计划缓存。
执行查询计划:和GraphStorage(GS)交互,完成查询计划。需要理解存储层数据分Partition的逻辑,找到数据,下推算子,merge查询结果,完成查询。
我们希望数据的计算是在数据所在的机器内部发生,会把这些查询下推到存储层去做一定的计算,不是把结果从存储层通过RPC回到查询层去做优化和计算,以减少数据传输。
查询优化器除了做基于规则的优化外,也做了基于代价(Cost-based)的查询优化,降低相关开销。
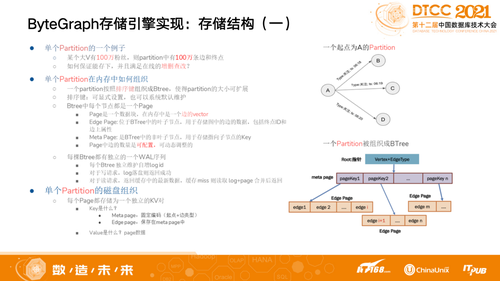
在第三层存储引擎层我们做了读写放大平衡,并不希望找一个点再把一个超大的Partition捞上来,所以我们单独去做拆分。如某大V(点)有100万粉丝,则Partition中有100万条边和终点。一个Partition按照排序键组织成Btree,拆成若干跨度,第一层记录当前的点和边,作为当前配置,假设现在基于100切分会有1万。
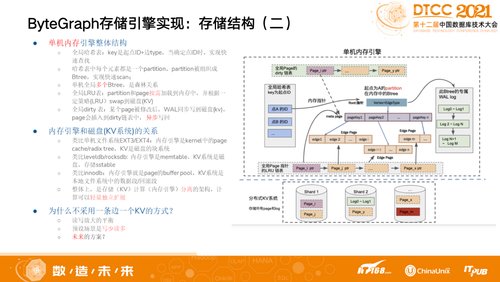
我们如何做到事务性?简单来说把一个单机引擎内存其中70%的Memory作为Catch,本身就是对刚才涉及到的若干个Part,其中每个元素表示一个Partition,基于我们自己特定优化的规则定义,当一个流量进来时会找当前Catch是不是有对应配置,如果没有就会Persistent,拿到以后记录当前Log ID。因为可能要考虑如果一台机器挂掉,Catch的数据没有及时更新,若干个机器能够组织在一起。
图训练引擎ByteGNN
▶︎ 什么是图训练
简单介绍一下什么是图训练,一切皆向量,图也不例外。
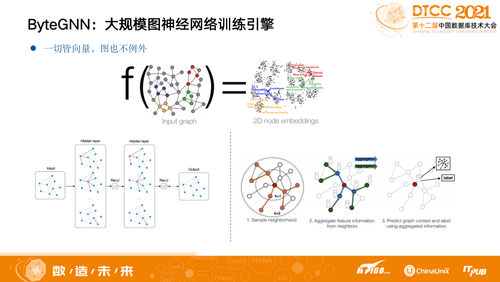
目前,业界的图数据库其实也做了跟AI和ML领域的结合,AI和ML的领域是一个向量作用,整体来说是要有一个方向,希望整个图上的每一个点能够预设到一个高维空间。以二维空间为例,比如图上红色的点和蓝色的点,局部的TOP性质比较相似,整个Model希望学出一个方式,让上图中红色和蓝色的点能够在二维空间中距离尽量近。
▶︎ 业界框架简介
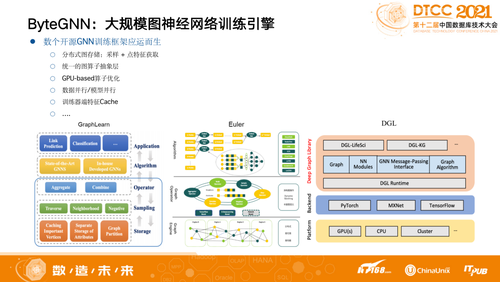
2019年开始,各个大厂都有自己开源的训练模型实践,都是基于分布式的,如GraphLearn、Euler、DGL、AGL等。但是整体来说这些开源框架遇到大规模数据时会有瓶颈,我们去拿这些框架做训练,比如一个千亿级别的图数据在真实场景上Run,可能训练需要三天三夜才能收尾,而高效地拿到最近的数据才能更好地去做推荐,所以训练有必要加速。希望做推荐可以看到的不是T+3的数据,而是T+1甚至T+0的数据。
▶︎ ByteGNN设计思想
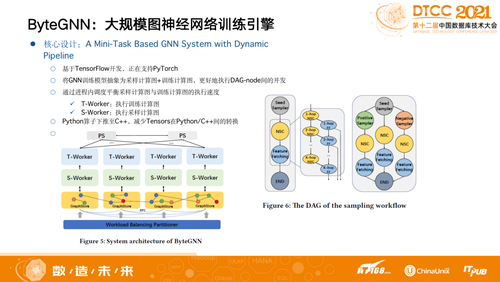
我们自研的ByteGNN 框架是基于Mini-Task的大规模图神经网络训练引擎,采样的过程抽象成了一个计算图,用户基于Python去做Programming,每个训练的OP对应C++里的实现,整体和TensorFlow比较相似,用户写完一个模型就在GNN生成采样和训练。原生的开源框架依赖于TensorFlow本身自带的逻辑去做训练层的训练。我们把采样和训练二者都抽象成了计算图,分别为执行训练计算图T-Worker,执行采样计算图S-Worker,通过动态调度使得整个计算资源的利用率更高,某个开源框架的执行效率可能是10%-20%,我们可以直接拉到80%。
我们每次采样其实没有Pipeline过程,可以理解为通过一个语法解析器把查询逻辑生成计算图,然后得到一个最优效果,做优化以后整体做一次训练的时长会显著变短。ByteGNN是通过Python算子下推至C++,减少Tensors在Python/C++间的数据转换。
当一张图非常大,ByteGNN设计了采样友好的图数据切分策略,按采样概率随机选择种子点集,基于点集做并行BFS将图划分成细粒度Blocks,保证数据的Locality,然后将Blocks基于数据局部性优化策略分配给score最大的Partition。比如,可以把整个图切成10万亿张的图,切成10万亿个Blocks,然后分别Assign到当前的100台机器,就是这样的平衡之后整个数据的Locality会变得很好,在采样的时候一跳和二跳都已经在普及,不需要进行网络发送。
图分析引擎
▶︎ 图分析及业内框架简介

简单来说,图分析就是在大规模图数据上做迭代式地、以点/边/子图为粒度地计算密集型任务。
传统的批处理系统如MapReduce/Spark运行图算法需要多轮迭代shuffle大量数据,效率低,资源消耗大。
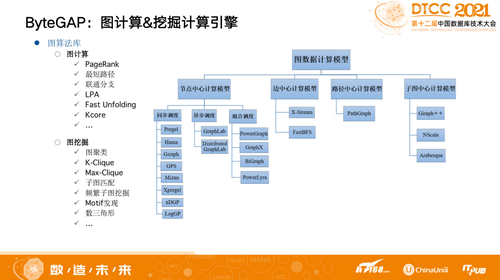
目前,业内图数据计算模型主要有节点中心计算模型、边中心计算模型、路径中心计算模型和子图中心数据模型,各有不同的优缺点。比如,节点中心计算模型,算法实现简单,但是通信开销大,随机访问严重;边中心计算模型,数据顺序访问,适合基于磁盘系统,但是通信开销大,适用算法范围小;子图中心计算模型,通信开销小,但是子图划分困难,抽象层次低,算法实现复杂。
▶︎ ByteGap设计思想
整体来说ByteGAP就是图计算和图挖掘两类,不同于以点为中心的编程模型,ByteGAP采用以Task为中心的编程模型,单个点或者边构成最基本的计算单元,单个子图候选集构成图挖掘计算单元,挖掘里面通常是有状态的,因为需要不断地去找,做了第一个Match之后要做第二个Match,每次Match过程中都有非常多的组合,内存又不够用了,那怎么办?
我们做成可扩展的系统,支持百万边规模的图数据离线计算,内存开销有上界,不容易OOM,搭载可扩展外存。
我们有自己的Partition算法,支持BSP和ASP两种计算模式,云原生相对更复杂。点需要无状态,一旦有状态就需要保证能够可恢复。整体来说,我们把相关信息分成两个Part存储:
一个Part是把点和Value、状态这些信息存在内存,要考虑机器挂掉了怎么办,对应的边以及边上的属性节点存在内存,通过CheckPoint机制保证数据不丢,如果丢了比如算到第二轮就挂掉,当前挂掉的机器会重新拉起进程,其它的机器会帮助恢复第二十一轮到第二十二轮的状态。
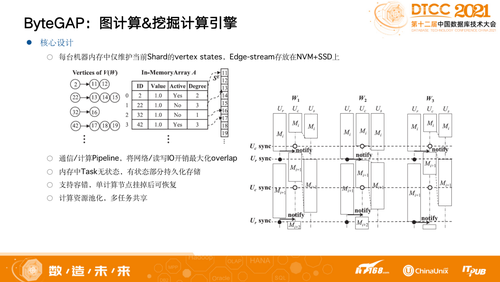
另一个Part是所有的边都存在于外侧存储NVM+SSD上,有了这样的Multi Layer存储之后整个系统就会变得可扩展。
此外,计算模型也做了很多优化,比如计算和通信的Pipeline,执行下一轮Receive时有一部分已经开始算起来,不需要等,同时也做了Message Combine。还有前面说的整个内存中Task无状态,有状态的部分持久化存储,保证数据不可丢失。同时也支持容错,计算资源池化,多任务共享。
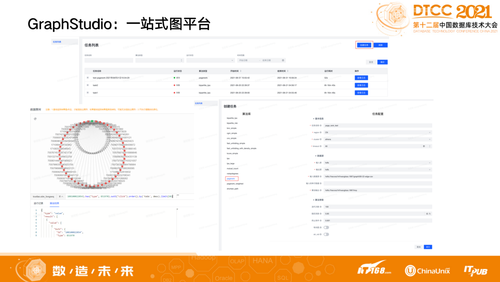
我们通过GraphStudio平台,把三个引擎串起来,比如要做图查询对应的Engine可以把结果可视化地显示出来,要做计算也有业务去选算法和参数,然后把GNN引擎拉起来,去做生命周期管理。
整体来看,字节跳动基础架构ByteGraph团队在分布式图数据库、图计算、图训练这三个场景下的自研系统(ByteGraph、ByteGAP、ByteGNN),能够支撑集团的所有和图相关的场景,从公开数据集测试结果来看快了30倍左右。目前,团队也积极联合学术界力量,与香港中文大学、北京理工大学的老师展开合作,一起推动图数据库发展。

