日前,百度宣布将自主研发的图数据库 HugeGraph 捐赠给 Apache 软件基金会,成为 Apache 孵化项目,孵化成功的HugeGraph有望成为全球首个 Apache 软件基金会的图数据库顶级项目。
图数据库已然成为当下最热门的数据库类目,不过图数据库发展还处于起始阶段,有机遇也有挑战。本文整理自DTCC 2021中国数据库技术大会上嘉宾演讲,分享嘉宾章炎,是HugeGraph图计算贡献者之一,前百度高级研发,目前在 Zoom 担任Java业务架构师。
本文包括以下部分:
1、图计算是什么,能解决什么业务问题?
2、图计算与传统计算的区别,为什么需要图计算
3、图计算业界现状,如何应对挑战?
4、如何应对挑战 -- 自研图计算
5、图算法开发与应用简介
图计算是什么,能解决什么业务问题?
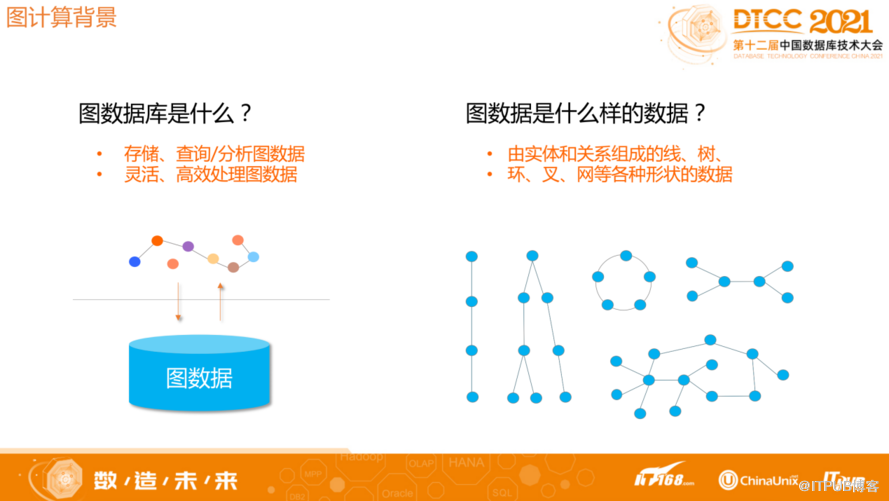
什么是图数据库?一般如果按照存储模型分类,数据库可以分为文档模型、图模型,关系模型等等,在文档模型中,文档之间通常没有关联,但图和文档模型相反,所有的连接点都有可能和其它任何节点产生关联,正由于这个特性导致图数据库在图模型处理中非常复杂。
图按照数据模型目前主流分为属性图和RDF图,而通常所说的基本都是属性图,属性图包含顶点、边,边和顶点都有一组KV属性,以及都有Label作为类型的唯一标识符。通常顶点表达实体,边表达实体之间的关系。图的任意顶点之间都可能产生关联,组成线、树、环、叉、网等各种形状的数据结构。
HugeGragh是百度安全部门自研的图数据库,2018年开源,采用APL 2.0开源协议,迭代了多个版本。
HugeGragh按照应用场景分为OLTP和OLAP。OLTP主要做即时图查询,OLAP做离线分析。最近针对我们遇到的一些问题推出了新的图计算的框架,框架使用多轮迭代计算算法,主打大规模的数据处理以及计算的稳定性。HugeGragh内置了很多算法,普通用户只需要调用API就可以直接使用这些内置算法,易于使用。
1 什么是图计算?
以图模型的方式对现实世界的问题建模,然后分析问题,选出合适的算法解决问题,这些过程就是图计算。比如要在社交网络中量化一个人的重要程度,每个人可以用一个顶点表达,人与人之间的关系通过顶点之间的边表达,图模型建立起来以后可以很直观的判断,如果此人重要,大概率会和很多人建立关联,并且每个人之间的关联路径很短。图计算针对上述场景有紧密中立性算法,可以通过算法计算出每个顶点的分值,分值越高就代表此人重要性越高,如果一个人和所有人都直接建立关联,此人肯定是最重要的人之一。总之通过图模型的方式描述一些问题,很简洁,也很符合我们的直觉。
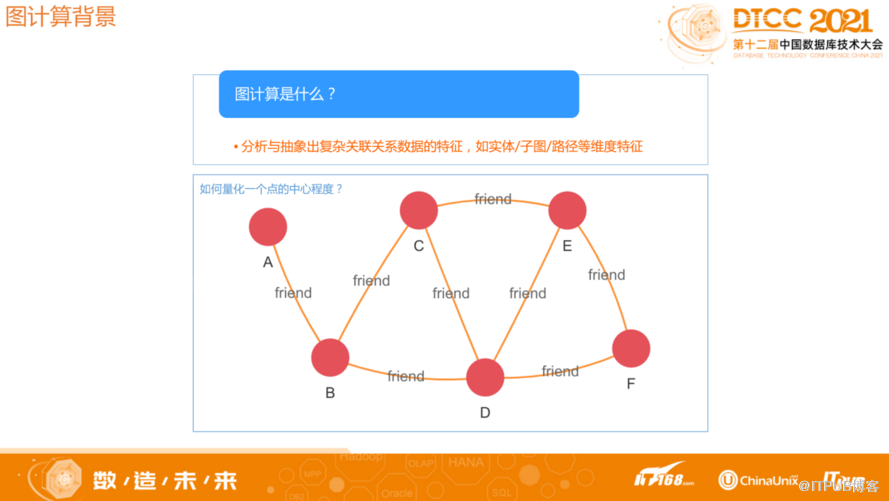
2 图计算能够解决什么业务问题?
一般来说图计算能够解决的常见问题包括网络安全、情报关系、智能营销、智能推荐、智能运维等,通过用图模型的方式建模,然后用合适的算法发现特殊点,发现问题,解决问题。比如循环担保问题,图计算可以用环路检测识别是否有循环担保问题,如果出现环路说明存在循环担保。
图计算与传统计算的区别,为什么需要图计算
图计算与传统计算有以下主要区别:
·处理的数据维度多、关联关系错综复杂
·非简单的单轮计算,而是具有依赖关系的多轮迭代
·数据分布,逻辑上关联紧密的图无法简单按照单维度被划分到一起
·分区不均问题,受现实世界中幂律分布而被放大,导致计算任务负载不均衡
·多轮迭代算法导致上下游任务无法割裂,需要相互配合同步
·迭代中间结果量巨大,图算法复杂度O(n*(degreeAdepth))随深度呈指数增长
其中针对多轮迭代算法导致的上下游任务需要相互配合和同步,无法割裂的问题,我们在设计系统时会尽量提高并发数,而对于图模型随着深度增加,复杂度也会增加,某些项目的中间结果会呈爆炸现象,我们会在设计时尽量平衡处理这些问题,通过打磨每一处的细节,来应对这些挑战。
图计算业界现状,如何应对挑战?
理论上要支持一个大规模的图计算,必须通过分区的方式使系统扩展,这里涉及到图的切分。现在业界对于图的切分一般分为两种:一种是边切法,一种是点切法。
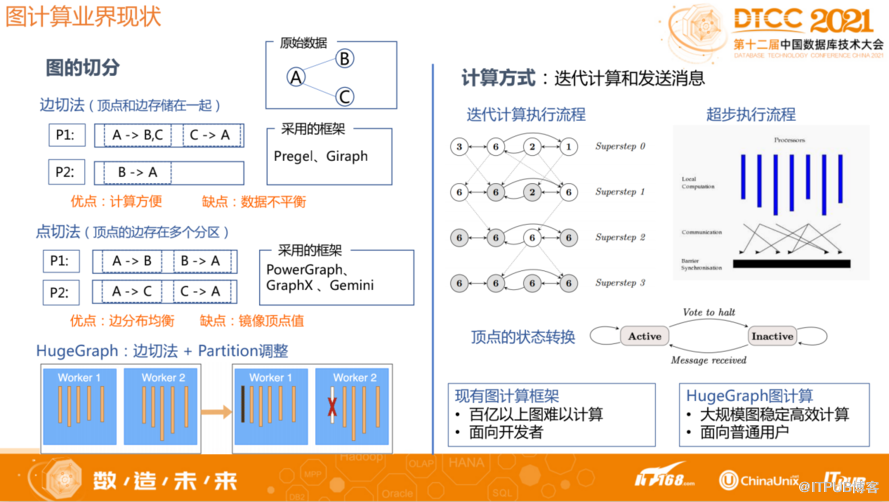
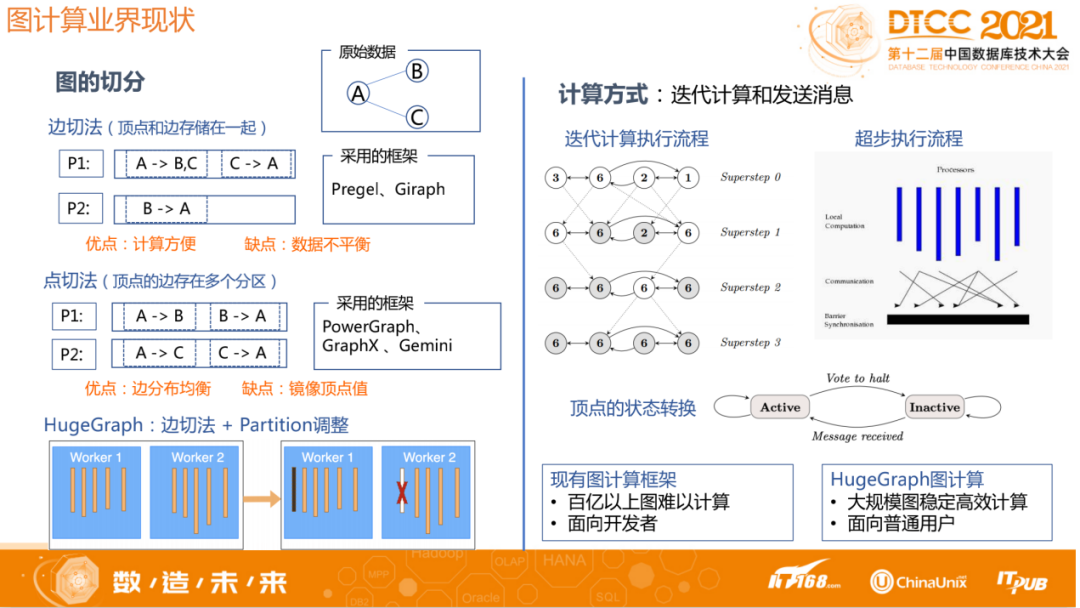
边切法是把某条边剪断,顶点和边存储在一起,每一个顶点反映在不同分区。优点是计算方便,缺点是数据分布不平衡。因为这种分区方式是把点和边放在一起,所以计算的时候只需要考虑单个节点就好,现在业界很多都是采用边切法的方式做切分。
点切法是将某个点进行划分,每个区都有不同的边,但顶点存在于多个节点、多个分区。优点是边分布均衡,缺点是由于每个存储都在不同地方,计算时需要汇总同步这些数据。
HugeGraph采用边切法。对于某些边特别多的超级点,有可能导致分区不均衡,我们针对超级点问题通过Partition调整来进行优化。比如如果某个Worker分布的超级点比较多,从而导致数据量比较大,这时可以根据负载情况将该Worker其它的Partition挪到其他Worker节点来平衡负载。总之也是通过数据进行分区,每个分区落在不同的Worker节点, 同时会根据数据量情况动态调整,以解决超级点问题。
前面说的多轮迭代图计算的框架就是DSP迭代计算,将算法分成不同的超级步,每个超级步需要迭代所有顶点,所有的顶点全部迭代之后会发消息(根据算法特征,根据一个初始值、计算值,需要发给相邻的节点,即发消息),再开启下一轮迭代。即下一轮超级步依赖于上一轮计算结果。最终所有节点全部变成Inactive就说明迭代结束,输出结果。
目前现有的图计算框架会有一些问题,百亿以上的图难以计算,而且不太稳定,图随机访问多,邻接边幂律分布导致任务划分难以均衡负载;图算法复杂度高,消息与中间结果指数级增长;现有的一些框架超过十亿规模图时,计算性能差、OOM严重。
如何应对挑战 -- 自研图计算
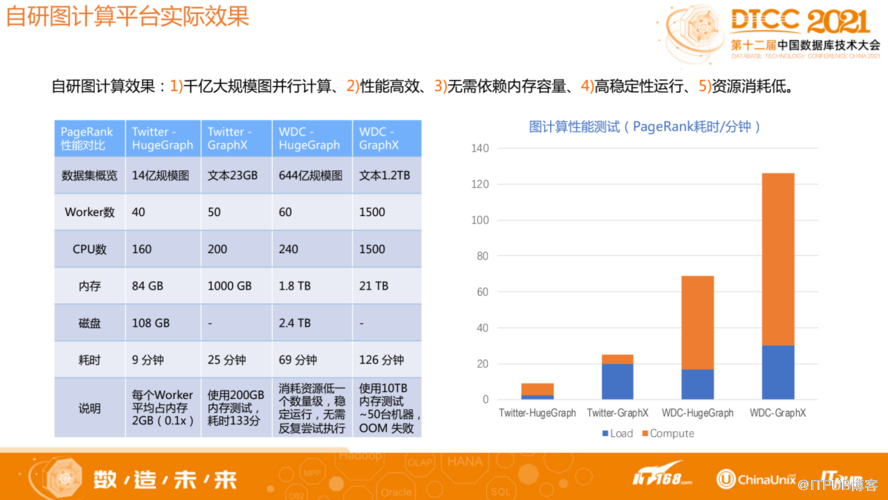
HugeGraph自研图计算平台对相关问题进行了优化,比现有一些图计算框架实现了更好的性能,能够支撑迁移大规模图并行计算,高稳定性运行。
1 自研图计算架构
1.1图查询&图计算-整体架构
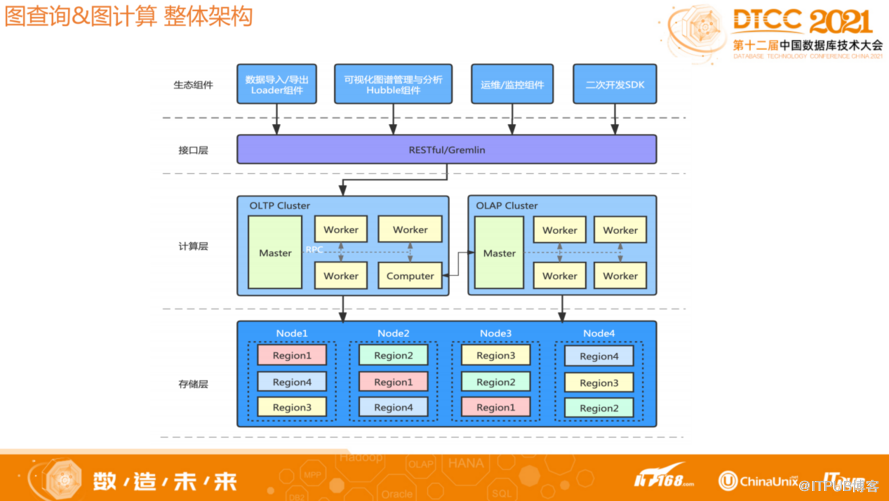
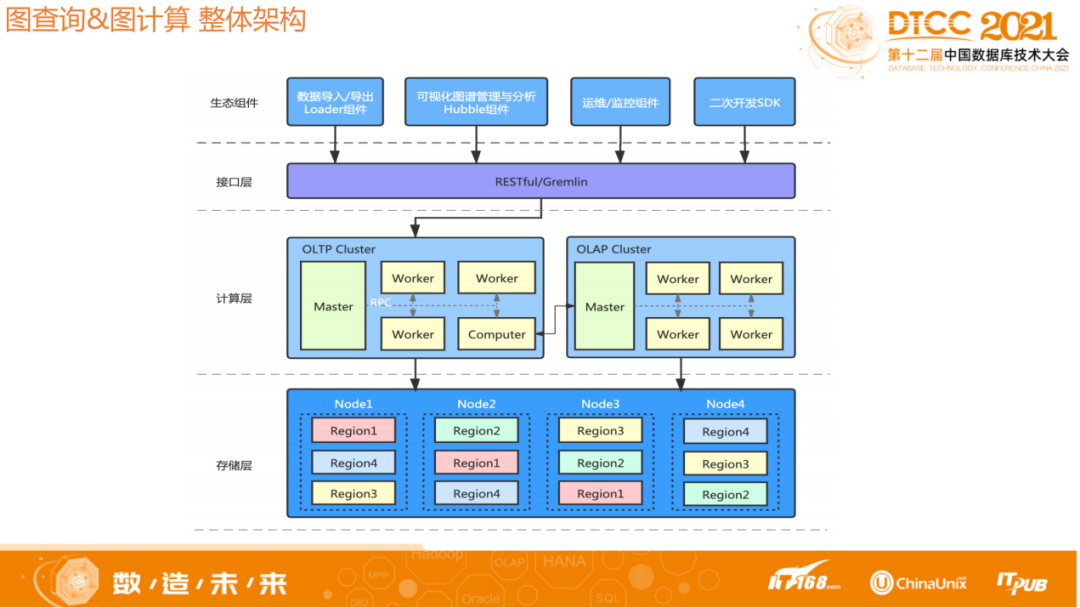
HugeGraph整体架构如上图,采用存储与计算分离架构。从底层到上层分别为存储层、计算层、接口层和生态组件。最上面是生态资源,现在已有的Loader组件可以将数据导入导出,此外也提供了一个Hubble平台,能够以可视化的方式查询和分析数据,图计算结果可以在Hubble上显示。
计算层OLAP和OLTP分开。OLAP是今天分享的主要框架,大体上分为Master和Worker两个角色。因为是分多轮迭代,所以需要一个协调者,以及信息流的汇总者,而Master角色就是来承担这些任务;Worker负责加载和输出,以及具体算法的执行。Worker数据加载采用分片方式,所以通过扩展Worker数量可以增加OLAP计算容量和并行计算能力。
存储层目前支持很多内置的存储组件,比如 HBase,Cassandra, MySQL, RocksDB 等等,同时框架也提供了插件化能力,如果用户有自己自研的存储组件,那么只需要实现对应的插件接口,就能够在存储层集成自定义的存储。目前HugeGraph的OLTP和OLAP底层采用同一套存储组件。
1.2 图计算架构-组件架构
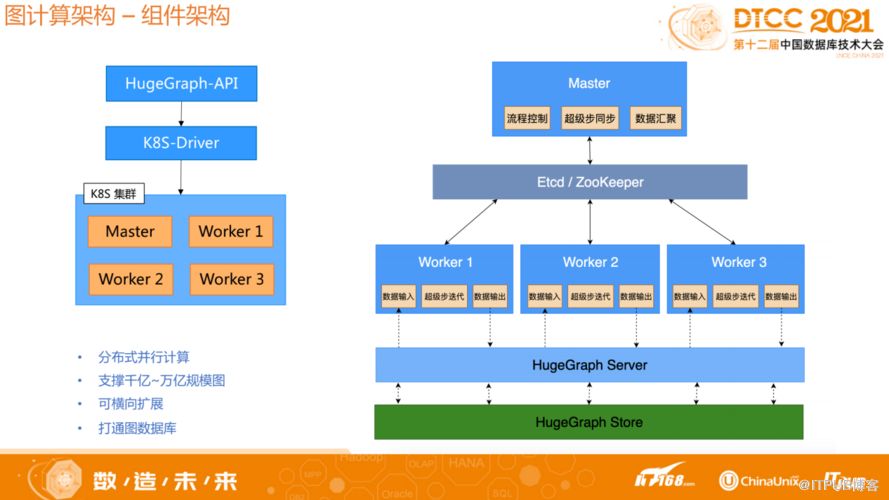
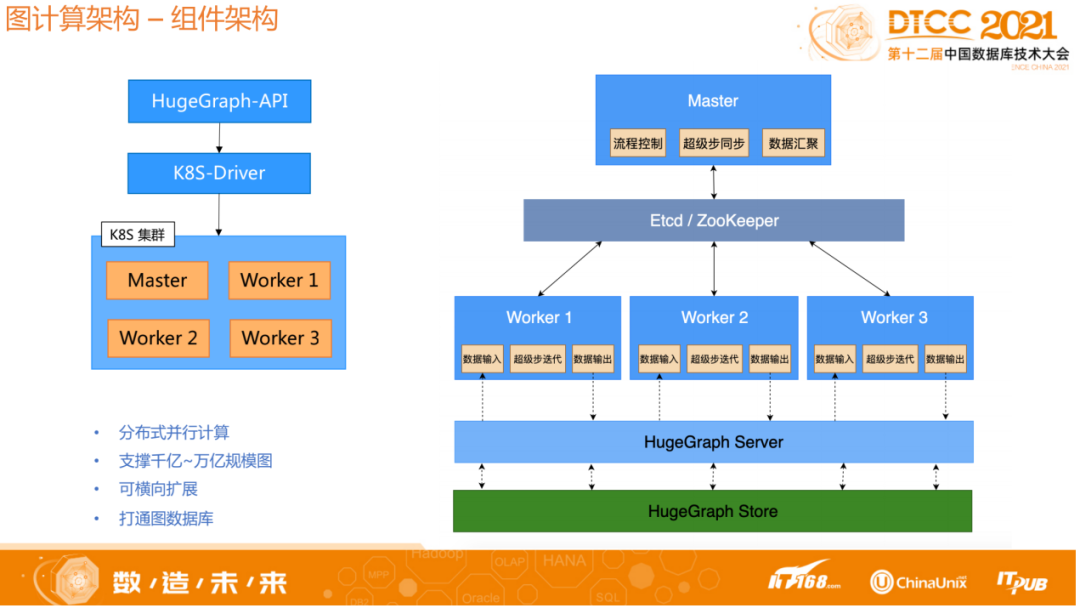
上图为组件架构。用户可以根据自己的数据量和算法配置参数信息,通过API的方式提交任务,任务会通过driver模块启动k8s集群创建对应的图计算组件,执行对应的算法,输出结果。
1.3 图计算架构-技术架构
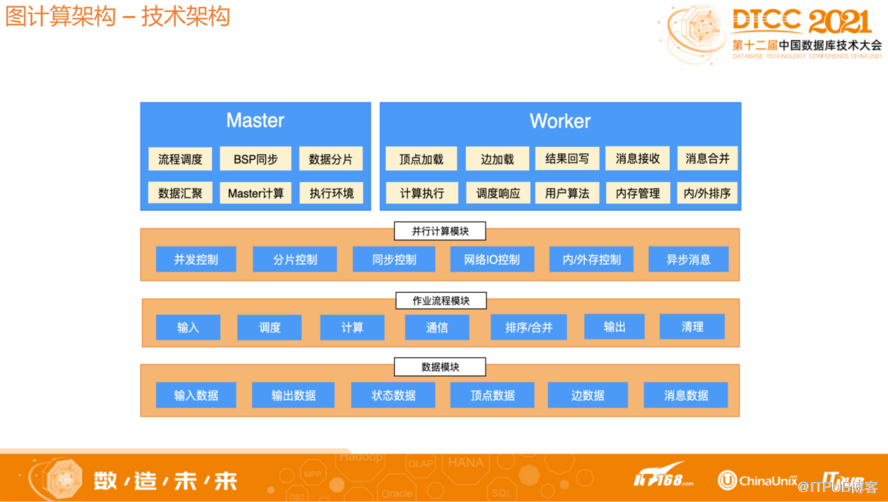
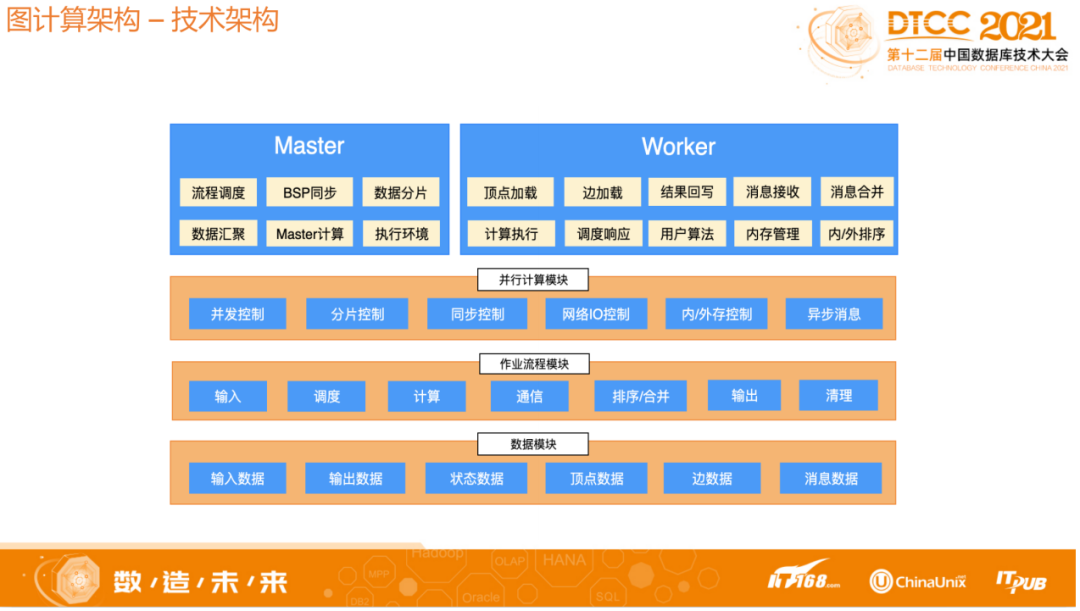
Master的角色主要是做流程调控,BSP同步,数据分片等,Worker角色主要是做对应数据的加载以及计算,Worker加载的数据都是通过Master分配,Worker和Master并行加载对应的数据,Master再进行数据汇总。对于Worker的消息发送,数据的存储都是采用自定义格式,通过设计自己的消息和数据存储结构,提高大数据存储量以及并行化处理能力,解决面临的挑战。
为了提升并行计算的能力,我们对底层做了很多优化。比如收发消息和迭代之间是并行的,不会等上一轮的计算结束才会收发消息。底层数据存储都是根据Partition分片的粒度分开,同时对所有数据进行排序,以减少随机访问。同时所有数据都是经过顺序访问进行计算,这样可以减少同步开销,更好的提高并行计算能力。
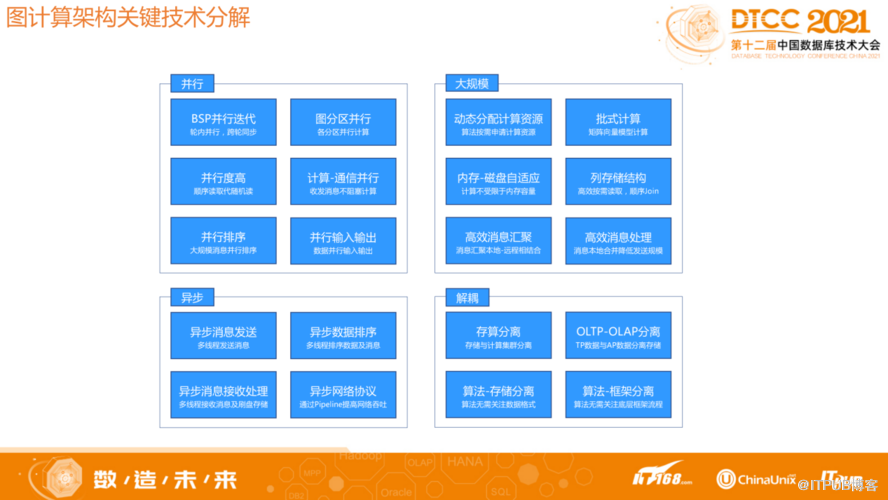
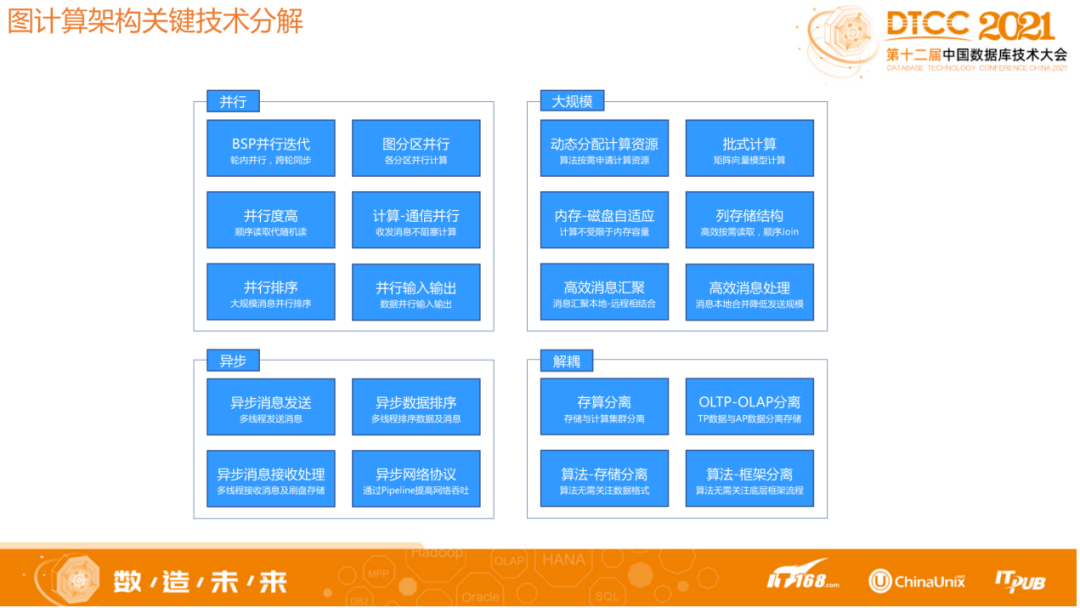
我们的主要目的是提升大数据量下的并行能力和稳定性,所以必然不会依赖于内存。比如对于超级点处理,并不会把所有数据都加载在内存中进行计算,而是加载一部分、计算一部分,所以稳定性可以得到保证。在迭代计算中发消息,收消息以及计算之间是并行,异步处理的,比如虽然下一轮迭代开始的时候所有消息需要保证接收完毕,但在每一轮迭代中,每一次收发消息都不会阻塞到计算逻辑。
在设计的时候我们极致的追求并行化,从存储到消息,再到上层的BSP框架的设计,包括请求、消息发送和计算,都充分考虑到并行方式,以充分利用计算机的处理能力。
2 图计算关键技术挑战及解决方案
图计算框架面临以下关键技术挑战:并行计算不均衡、消息传输量巨大、内存OOM严重、分布式节点部分失败。针对这些挑战HugeGraph采取了相应解决方法。
并行计算不均衡挑战。我们采用存算分离架构,使用 K8S 扩展,多 Worker并行计算。每个Worker负责部分Partition数据,按照点粒度分区。Worker 根据边总数量分配 Partition 个数,确保性能与负载均衡。Worker 内部采用多 Partition 多线程并行计算,同时计算与消息异步并行,充分利用了CPU多核能力。总之从底层到上层设计,各个组件之间的交互充分考虑到并行能力。
消息传输量巨大挑战。随着迭代速度增加,中间数据、中间结果和消息可能会大量增加。我们采取以下措施保证稳定性:发往远程的消息在本地 Combine 合并,超级点消息延迟到目标 Worker 分发。消息传输与计算并行,消息传输通过 Pipeline 方式提升吞吐。自定义协议与格式,分离数据面与控制面,利用压缩编码减少数据传输量。大规模消息利用基于磁盘/内存文件的堆排序/败者树进行动态多路归并,控制消息文件数量。
内存OOM严重挑战。不依赖内存容量来存储图计算的输入和中间结果,从根本上解决 OOM问题。内存-磁盘自适应,不依赖内存 Map,通过顺序 Join 内存/磁盘列存文件。重用内存对象,自分配内存方式管理内存,使用JVM堆外内存降低GC压力。通过Pipeline方式进行批式向量计算,平衡性能。
分布式节点部分失败问题。部分节点失败,将导致整个集群计算中断,造成时间、计算资源的极大浪费。要建立全链路负载反馈机制,尽可能避免部分节点因瞬时负载过高导致的失败。建立故障恢复机制,每一轮计算的中间结果快照到分布式文件系统上。部分节点失效时,无需从头计算,通过启动新的节点替代故障节点即可。
图算法开发与应用简介
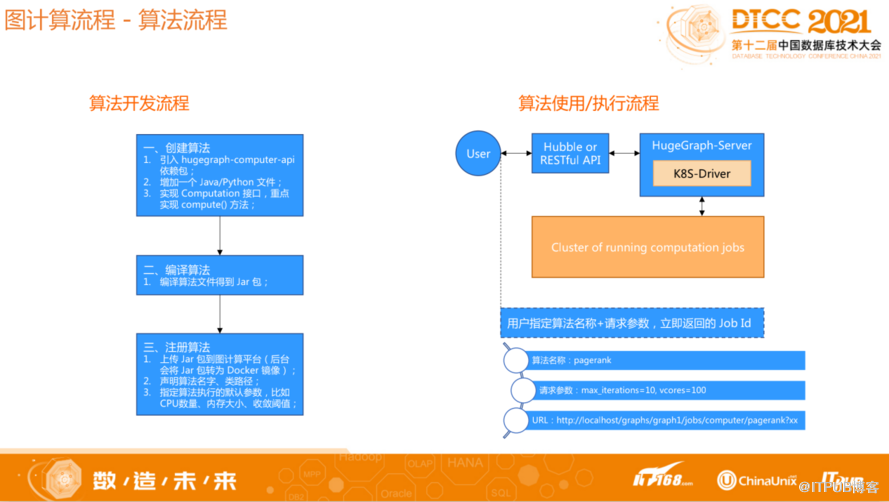
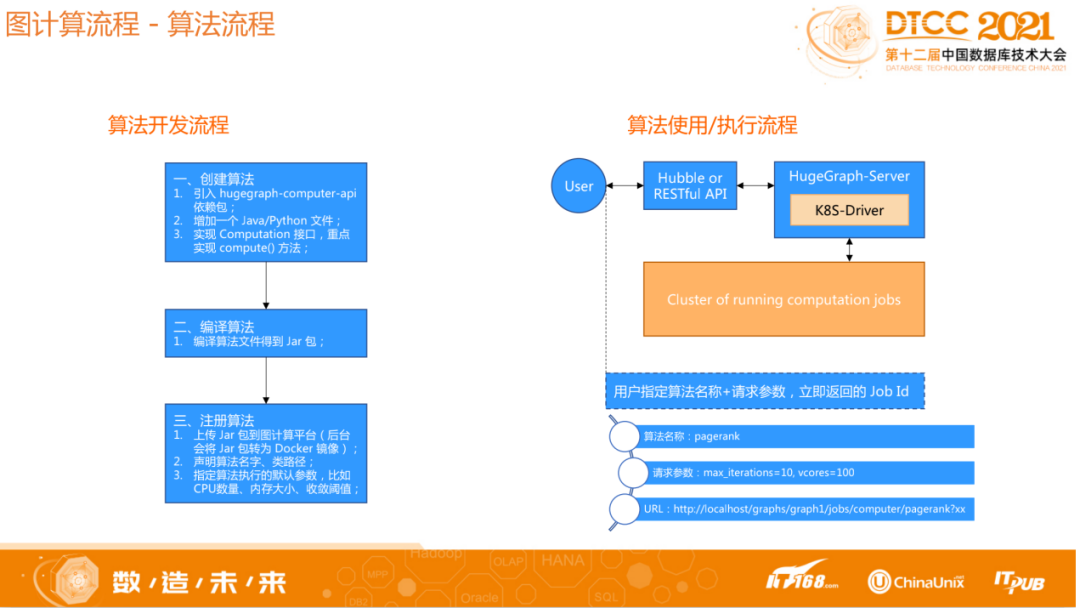
关于HugeGraph算法开发,只需要通过引入API的依赖包,然后实现对应的框架接口,再将该包传到后台,同时根据计算的数据量、算法类型调整参数即可。计算的输入及输出格式均与算法本身解耦,采取HugeGraph标准的OLTP接口访问计算结果,不需要关注框架流程与算法的执行细节,仅关注算法逻辑本身,专注每个顶点收到的消息及其处理。总之HugeGraph内置了很多算法,同时如果用户需要自己开发一个算法,只需要关注算法本身的问题,具体数据怎么封装、怎么输出,这些都不需要关心,非常易于使用。

