作者:冯源
整理:老鱼
作者介绍:

冯源,武汉达梦数据库股份有限公司副总经理,主要负责达梦数据库产品的软件测试、技术规划工作。长期从事大型、通用国产关系数据库管理系统——达梦数据库产品DMDBMS v4.0、v5.0、v6.0、v7.0和v8.0系列的产品测试和技术规划工作,熟悉国内外主流数据库产品体系架构,对于数据库安全防护体系、数据库性能优化、数据库领域基准测试模型与方法具有深厚经验;参与了《GB/T 30994-2014 关系数据库管理系统检测规范》、《GB/T 20273-2019 数据库管理系统安全技术要求》等多项国家标准的编制工作。
正文
我分享的主题是“达梦分布式数据库演进”,主要分享达梦公司分布式数据库演进、发展历程,介绍达梦公司对分布式数据库未来发展和应用前景的分析观点。
在正式分享前,我想先从几个不太相关的小故事讲起,以归纳我的核心观点。

无论是爆米花,还是要扔出去的手雷,亦或是过年发射的窜天猴,其实都有一定共性,就是加热膨胀时,如果不对其进行精准控制,扔出去就会变成一个炸弹,如果是在精准的温度、压力下释放,就会变成爆米花,如果自始至终都给其一个发泄口,就会飞上天去变成一个漂亮的焰火。
通过这三个事物,我想表达的是什么?很多时候,看起来不太一样的东西背后,其实都有着相似的原理,不同的用途,就看你怎么用?

技术是用来解决问题的,同样的技术可以解决不同问题。反之,为了解决问题,达到相同目标,又可以选择不同的技术,至于用什么技术、用哪项技术,还是以需求为核心,这是我在导语当中可以得出的两个结论。
接下来,我将通过挖掘分布式数据库是怎么产生的,最初是为了解决什么问题,来印证前面两个结论。
分布式数据库其实不是什么特别新鲜的东西,基于以下几个事实:

为什么?上述事实可能不是特别清晰,回到当时文献看一看,这是1979年到1980年的文献。
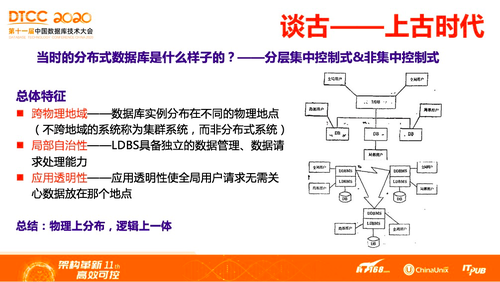
总体来说,当时学术界对于分布式数据库的研究,主要分为两个架构:一个是分层集中控制式,也就是很多区域性数据库,上面加一个分布式调度层。另一个是非集中控制式,这个更接近现在的分布式数据库,也就是去中心化的架构。即便是在今天来看,也不是特别过时,现在有很多数据库仍然是沿着这样的思路架构来做。
无论任何一种架构,1970-1980年时,其定义,抽象出来有三个特点,也就是所谓的分布式数据库应该具备哪些特征?
首先,是跨物理地域的特点,数据库实例分布在不同的物理地点。当时名词中,有一个“集群系统”,也是采用类似架构,由很多节点组成,但没有跨地域,所以,称之为集群系统。
另一特点是局部自治性,任何数据库都应该具备本地管理、本地处理的能力。
在此基础上有全局性的数据访问请求时,不需要关心数据分布在哪一个区域,称之为应用透明性。
总结起来,就是物理上分布,逻辑上一体。

当时的分布式数据库选的什么技术进行研究?我们能发现,其中很多词在今天是非常熟悉了,比如数据的划分,水平划分还是垂直划分,分片存储还是复制存储,数据分布以后如何保证事务完整性?怎么实现数据提交?怎么预防分布式环境下的变化?
要用一项技术,一定要看当时的需求是什么?我们再仔细看,就会发现非常有意思的东西,今天我们谈数据库的划分,更多的是希望,通过数据库的划分让数据分散存储,提高数据存储能力,通过分散存储可以实现过载均衡性能提高,但当时的论文写得非常有意思,他们的目标是节省网络费用,甚至包括后面很多研究者在研究,到底是应该分片还是应该复制,或者是在什么时候分片、什么时候复制,出发点也是怎样平衡存储费用和网络通信费用。
既然,分布式数据库的大量技术问题,早在“上古时代”就已经提出,并已有相当的基础,那么,为什么分布式数据库在90年代却“偃旗息鼓”了?
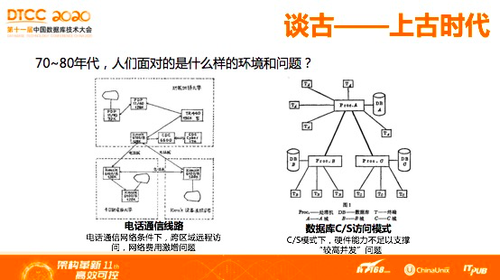
如果仔细回顾当时研究这些技术的目标,也就是费用问题,就能够很清楚地知道,为什么出现这些情况。(左图)是当时西德实验室的分布式数据库,从当时的架构图非常清楚地看到,三所大学节点网络通信用的是电话线,九十年代,在家里上网都知道,那个时候上网费有多贵,所以,如果数据库系统,分布式通信依靠的是电话线实现,就近划分数据就近访问数据,一定能够节省大量的通信费用成本,如果不去挖历史,是无法得知当时的技术目标是什么。
七八十年代,计算机应用刚刚兴起,那时,现在熟悉的中间件还不存在,用户稍微多一点,数据库就无法承担并发能力,在C/S模式下,硬件能力不足以支撑“较高并发”,因此,单机数据库或者集中式数据库没有办法满足性能要求。
为什么在九十年代会发生这种巨变?原因很简单,硬件技术的发展,使得集中式数据库具备了足够的并发处理能力。另一个非常重要的原因是,交易中间件的诞生和完善,大概是1985年到1995年,它的出现改变了应用程序访问数据库的访问模式,信息系统从两层结构变成三层结构,显著改善了数据库并发响应速度。
达梦认为,集中式数据库技术的发展,充分发挥了硬件设备的能力,当时面对的问题,最终由硬件设备的发展+集中式数据库组合解决,人们失去了继续发展、使用分布式数据库技术的理由。
小结一下,通过对七十年代到八十年代分布式数据库的回顾,不管是用户或是研究者,在当时研究分布式数据库技术,或者到了九十年代不再研究分布式数据库技术,最终都是“需求第一” 性原则的作用结果。

1989年,达梦发布了第二代数据库产品DM2(分布式数据库管理系统),也是那时,达梦开始做分布式数据库研究,体系结构、存储结构和随机查询方面都做了一些工作,最后,也是随着技术趋势的演进,演变为主要研发集中式数据库产品。
到了今天为什么分布式数据库再次兴起?移动互联网之前,我们非常熟悉的甲骨文和IBM这些巨头,在市场上非常成功。而到2012年,以Google发布Spanner论文为标志,分布式数据库结束蛰伏。分布式数据库到今天有着非常多的流派,大体上可以分为三类:Google Spanner及其参考文献,PG XC/XL技术结构方案更传统,也更接近经典的分布式数据库,为什么我把PG单独拎出来说?因为,达梦看到,今年国内有很多分布式数据库厂商基于PG XC/XL,产业上是不可忽视的点。另外Amazon云原生数据库,国内也有很多产品是参照其方案实现。
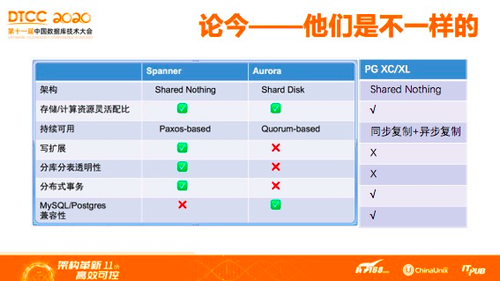
我们找到一些参考资料,只针对Spanner和Aurora进行了对比,我个人把PG也加进来了。可以看到,虽然大家都叫分布式数据库,但实际上细节不一样,这说明实现目标不一样。如果仔细去看的话,有的是共享存储架构,有的是非共享。今天,因为时间有限,我们单独拎出来一个点看一看,比如持续可用。为什么不同的分布式数据库会选择不同的数据库协议?强调一下,之前我形成的第一个结论,为了解决产品的问题,用户和开发人员都是以“需求第一性”原则为主。
Spanner有很多的技术创新,最关键的精髓有几点:首先是引入PAXOS,引入TruTime API,然后,做了多版本的外部一致性。
为什么Spanner要做PAXOS?Spanner是Google自用的数据库,虽然后来发布了Cloud Spanner,但在最初,它是给Google广告系统用的。Google是一个全球化的公司,业务遍布全球,用户遍布全球,分布式机构也是遍布全球,全球化的公司就有全球化的利益,什么叫做全球化的利益?就是当一个区域甚至一个大洲发生不可控的因素的时候,利益不会受损,业务可以持续运转,需要一个能够维护全球利益的数据库,也就意味着遇到局域性的灾害、疫情甚至政治不稳定、海底光缆故障大面积设备失效,也可以保证其业务持续不断地赚钱,也能为客户带去它的价值,这是Google对数据库的诉求。正因为如此,Google第一篇论文并非冠以分布式数据库,而是冠以全球分布式数据库的名字和原因。

今天,我们发微信或打电话都时习以为常,认为信息传播成本非常低,可能就几分钱或者几毛钱话费,但我们忽略了一个事实,信息传播速度是有上限,信息传输是有成本的。
站在地球这样个范围不是问题,如果极端一点,远在火星或太阳进行通信,一条消息发过去,要五分钟的时间,如何知道消息对方收到否?所以,通信天生的不可靠才是一种常态。
只有在这种情况下,我们才会意识到,进行一次通信传输应该有一些保证,保证信息不可失真,保证大家能够看到同样的消息,在这种情况下PAXOS是最好的衍生性保障。
为什么70年代会有分布式集群概念?因为距离比较近,如果距离远,信息能不能收到会成问题,我们是不是能达成共识也是问题,这是这个概念的由来,没有一个大距离的跨度,是不需要这么复杂技术的。
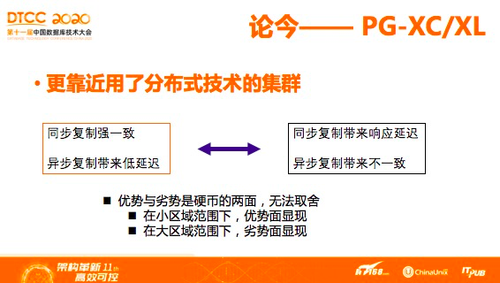
众所周知,PG-XC/XL的经典版本,或社区版本当中用的是传统复制技术,保证同步复制和异步复制,好处是同步复制带来强一致,异步复制延迟较低,但这是在一个小距离环境下看到的,也就是一个硬币正面和反面的问题。要是这个距离扩大到一千公里级别,硬币的另外一面就会显现出来,在大区域范围下,同步复制的延迟以及异步复制带来的不一致性问题就会显现。PG这套系统如果视之为集群效果非常好,有着更好的响应时间、运维和线性扩展效果,所以,这套系统更适合小范围部署的、追求线性扩展的用户。

云原生算不算分布式?有没有衡量标准?如果以是否产生分布式事务来看,单主模式是没有分布式事务的,所以不是分布式数据库。以有没有分布式存储来看,逻辑上看是共享存储,所以,好像也不算分布式数据库,但是基于云技术实现分布式存储,所以应该可以算分布式数据库。如果从有没有跨地域的能力来看,当然有了,所以应该算分布式数据库。
因此,从需求第一性原则出发,云原生是不是分布式不重要,重要的还是Amazon为什么要做?Aurora的定位是什么?满足全球访问需求?其实不是,也不是在小范围做到极致扩展,就是为了租赁给普通用户。普通用户怎样使用数据库?99%的用户没有像Google那样的全球利益,也不需要做极致的扩展,其实就是一种使用模式,只是想把以前使用从本地搬到云上,简简单单地让云厂商解决副本的问题就很完美。
所以我们能看到,过去几年,云原生数据架构的变革更多的是在中下层动刀,比如亚马逊的日志即数据,减少云上的网络流量,到了国内可能还有一些改变,Quorum协议改到Raft协议,进一步降低网络同步流量占用,但会引入一些延迟;不过这样也没关系,可以通过RDMA来弥补。另一方面,因为云上部署,因此基础设施集约化是可以做到的,NVME可以上,FPEG、RDMA也可以上,这些就是前几年可以看到的云原生数据库厂商的技术发展的内容,而数据库的中上层,更多的是以继承PG和MySQL为主。
通过分析这三类技术路线,达梦认为是不是分布式其实并不重要,还是要回到发展技术的初衷来看“需求第一性”。站在用户的角度要不要用分布式数据库?怎样用分布式数据库?用户应该要对自己的需求非常清楚,然再去选数据库。

刚才谈了三种架构,还有一种没有谈,就是分布式中间件。2015年,达梦做了一个分布式中间件,后来发现这个技术方案对应用不透明,事务也不保证,容灾能力也较弱,所以,达梦抛弃了这套方案,中间件的事情,交给中间件厂商来做,达梦来走适配,效果同样很好。
到了2019年,达梦认为从现状上来看,分布式数据库最大的问题是兼容性代价太高,所以,达梦更提倡透明式TDD的概念,在保障数据库通用性、具有比较强的一致性前提下,同时具备一些可扩展的能力。
到了2020年,达梦发布了新一代的原生数据库,希望在透明式分布式数据库的基础上进一步加强分布式处理能力。
达梦分布式思路,原则是“需求第一性”,技术只是工具手段,按需选择。
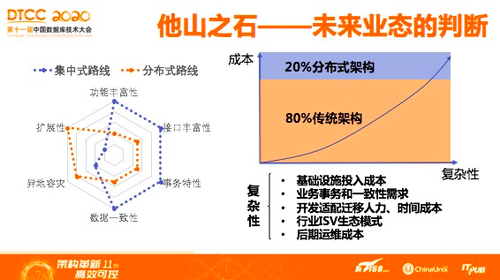
鉴于分布式数据库现状,众所周知,分布式数据库性能很强,但有好就有坏。达梦对未来的判断是,80%的系统架构还会在原有的传统集中式架构当中去用,因为这些业务系统负载较高,或者对可靠性要求没有那么高,并发也没有那么高,通过传统技术可以非常低成本地解决。
随着分布式架构复杂度的增加,成本也一定会增加,所以,更适合更高端的行业场景。传统集中式无法解决的分布式数据库应该是什么样子?
首先,是数据量爆炸,并发曲线非常陡峭,用户对数据响应时间的容忍度相对比较低,这也是一个现实,分布式数据库今后不是你的数据库或者是我的数据库,它将变成基础设施,因此一定要有足够的容灾能力,因为,大家都是跑在一个系统上。
时间有限,每个需求采用什么样的技术来满足,不能全部介绍,我只提三点:达梦数据库已经引入Raft,因为异地副本自适应能力是采用传统复制技术不可能实现的,现在有很多厂商仍然采用一主多备的复制,达梦认为并不太适合1000公里以上的自适应故障处理能力。
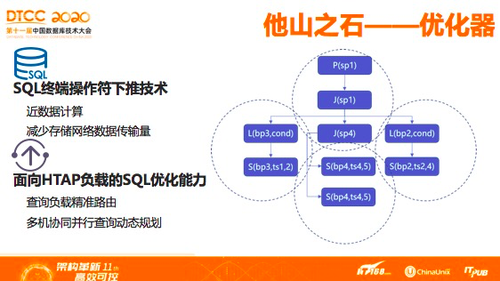
前几年,分布式数据库主要是谈架构,很少谈优化器,其实优化器是数据库的核心。作为一个传统的数据库厂商,做了这么多年,达梦最大的优势就在于优化器。记得以前和大家分析过一个案例,一个央企财务系统上,有一个500多页的SQL,达梦可以很好的处理这种复杂SQL,这种请求目前来看,在分布式是比较难处理的,而达梦可以把这种SQL优化能力,从集中式数据库平移到分布式数据库产品里面。
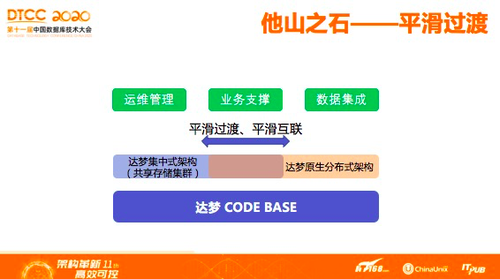
目前,分布式数据库应用和推广最大的障碍就是生态,原因在于分布式数据库的通用性不够:很多经典功能在集中式可以用得很好,分布式就不能用,所以,会有很多的应用移植工作。达梦的重点思路是通过一套Code Base完成这项工作,不管是集中式还是分布式,达梦都用一套Code Base,无论是做运维管理还是应用开发,或是做大数据集中层,协议都是一样的,语法都是一样的,可以做到平滑的过渡、互联,实现统一。
最后,目前看来分布式数据库技术现状,用一个字来总结就是“乱”,厂商多、路线多、概念多。但这是百花齐放的时代,乱是正常的。从长久来看,最终一定是趋同。不管是从传统厂商做起的达梦,还是从To B、To C或者服务器厂商做起的,没有谁一开始就是做分布式数据库的,大家的基因不太一样,但基因不是重点,重点是环境最后会把大家塑造成长得差不多的模样。所以,作为用户不用太担心,选谁都不会错。

